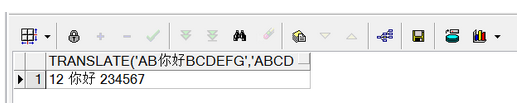
刪除重復的記錄
因是手動錄入數據,所以經常會產生重復的數據,這時就需要刪除多余的數據。
創建測試用表:
CREATE TABLE dupes(
id integer,
name varchar(10)
);
INSERT INTO dupes VALUES(1, 'TOM');
INSERT INTO dupes VALUES(2, 'ALLEN');
INSERT INTO dupes VALUES(3, 'ALLEN');
INSERT INTO dupes VALUES(4, 'SMITH');
INSERT INTO dupes VALUES(5, 'SMITH');
INSERT INTO dupes VALUES(6, 'SMITH');
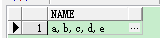
SELECT * FROM dupes;
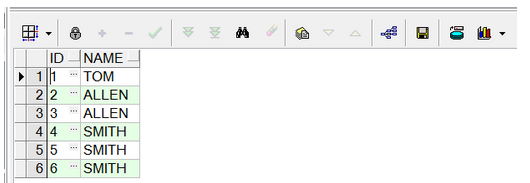
可以看到“ALLEN”和“SMITH”這兩個人的數據重復了,現在要求表中name重復的數據只保留一行,其他的刪除。
刪除數據有好幾種方法,下面介紹三種方法。
方法一:通過name相同,id不同的方式來判斷。
sql代碼如下:
DELETE FROM dupes a
WHERE EXISTS (SELECT 1
FROM dupes b
WHERE a.name = b.name
AND a.id > b.id);
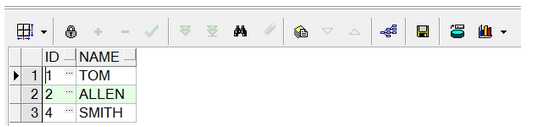
SELECT * FROM dupes;
執行結果如下:
方法二:用ROWID來代替其中的id。
sql代碼如下:
DELETE FROM dupes a
WHERE EXISTS (SELECT 1
FROM dupes b
WHERE a.name = b.name
AND a.ROWID > b.ROWID);
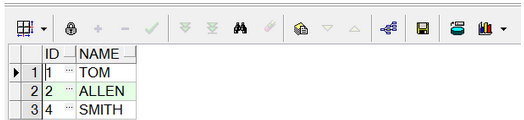
執行結果如下:
方法三:通過分析函數根據name分組生成序號,然後刪除序號大於1的數據。
sql代碼如下:
DELETE FROM dupes a
WHERE ROWID IN (SELECT rid
FROM (SELECT ROWID as rid,
ROW_NUMBER() OVER(PARTITION BY name ORDER BY id) AS seq
FROM dupes)
WHERE seq > 1);
執行結果和上面一樣。