MongoDB的常規備份策略
MongoDB的備份其實算是一個基本操作,最近總是有人問起,看來很多人對這裡還不太熟悉。為了避免一次又一次地重復解釋,特總結成一篇博客供後來者查閱。如有不盡正確之處請指正。
1. 內建方法
1.1 復制數據庫文件
不用多做解釋,幾乎對任何數據庫都有用,簡單粗暴。但像多數數據庫一樣,這個操作必須在mongod實例停止的情況下進行才能保證你得到的是正確狀態下的數據庫。否則在備份過程中如果有寫操作,可能造成備份到的庫處於非正常狀態而不可使用。必須停止數據庫這一點就造成了這個方法的可用性非常低,使用場景有限。
1.2 mongodump/mongorestore
我不打算細說這兩個命令如何使用,因為介紹這兩個命令的文章網上已經一大堆了,大家可以輕松從別處或者官方文檔中找到說明。不想細說的另一個原因也是希望看到這裡的讀者能夠養成獨立解決問題的能力,不要對所謂的“高手”產生依賴,遇到問題獨立思考獨立解決,這將是你今後的道路上必不可少的技能之一。
下面介紹一些別人說得相對少的東西。
1.2.1 除了mongodump/mongorestore之外還有一對組合是mongoexport/mongoimport
區別在哪裡?
mongoexport/mongoimport導入/導出的是JSON格式,而mongodump/mongorestore導入/導出的是BSON格式。
JSON可讀性強但體積較大,BSON則是二進制文件,體積小但對人類幾乎沒有可讀性。
在一些mongodb版本之間,BSON格式可能會隨版本不同而有所不同,所以不同版本之間用mongodump/mongorestore可能不會成功,具體要看版本之間的兼容性。當無法使用BSON進行跨版本的數據遷移的時候,使用JSON格式即mongoexport/mongoimport是一個可選項。跨版本的mongodump/mongorestore個人並不推薦,實在要做請先檢查文檔看兩個版本是否兼容(大部分時候是的)。
JSON雖然具有較好的跨版本通用性,但其只保留了數據部分,不保留索引,賬戶等其他基礎信息。使用時應該注意。
總之,這兩套工具在實際使用中各有優勢,應該根據應用場景選擇使用(好像跟沒說一樣)。但嚴格地說,mongoexport/mongoimport的主要作用還是導入/導出數據時使用,並不是一個真正意義上的備份工具。所以這裡也不展開介紹了。
1.2.2 mongodump有一個值得一提的選項是--oplog
注意這是replica set或者master/slave模式專用(standalone模式運行mongodb並不推薦)。
--oplog use oplog for taking a point-in-time snapshot
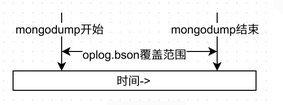
看英文說明好牛B的樣子,point-in-time快照哦,我第一次看到這句話的時候的理解是它可以讓數據庫回到這段時間中的任意一個時間點的狀態,美了好一陣。但實際上並不是。它的實際作用是在導出的同時生成一個oplog.bson文件,存放在你開始進行dump到dump結束之間所有的oplog。這個東西具體有什麼用先賣個關子。用圖形來說明下oplog.bson的覆蓋范圍:
為了後面的講解不至於把人說暈,進一步說明之前先解釋一下什麼是oplog及其相關概念。官方提供的文檔其實已經很全面地做了解釋,點擊查看中文文檔或英文文檔。
簡單地說,在replica set中oplog是一個定容集合(capped collection),它的默認大小是磁盤空間的5%(可以通過--oplogSizeMB參數修改),位於local庫的db.oplog.rs,有興趣可以看看裡面到底有些什麼內容。其中記錄的是整個mongod實例一段時間內數據庫的所有變更(插入/更新/刪除)操作。當空間用完時新記錄自動覆蓋最老的記錄。所以從時間軸上看,oplog的覆蓋范圍大概是這樣的:
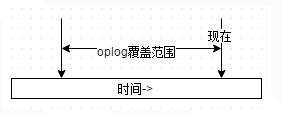
其覆蓋范圍被稱作oplog時間窗口。需要注意的是,因為oplog是一個定容集合,所以時間窗口能覆蓋的范圍會因為你單位時間內的更新次數不同而變化。想要查看當前的oplog時間窗口預計值,可以使用以下命令:
test:PRIMARY> rs.printReplicationInfo()
configured oplog size: 1561.5615234375MB <--集合大小
log length start to end: 423849secs (117.74hrs) <--預計窗口覆蓋時間
oplog first event time: Wed Sep 09 2015 17:39:50 GMT+0800 (CST)
oplog last event time: Mon Sep 14 2015 15:23:59 GMT+0800 (CST)
now: Mon Sep 14 2015 16:37:30 GMT+0800 (CST)
oplog有一個非常重要的特性——冪等性(idempotent)。即對一個數據集合,使用oplog中記錄的操作重放時,無論被重放多少次,其結果會是一樣的。舉例來說,如果oplog中記錄的是一個插入操作,並不會因為你重放了兩次,數據庫中就得到兩條相同的記錄。這是一個很重要的特性,也是後面這些操作的基礎。
回到主題上來,看看oplog.bson到底有什麼作用。首先要明白的一個問題是數據之間互相有依賴性,比如集合A中存放了訂單,集合B中存放了訂單的所有明細,那麼只有一個訂單有完整的明細時才是正確的狀態。假設在任意一個時間點,A和B集合的數據都是完整對應並且有意義的(對非關系型數據庫要做到這點並不容易,且對於MongoDB來說這樣的數據結構並非合理。但此處我們假設這個條件成立),那麼如果A處於時間點x,而B處於x之後的一個時間點y時,可以想象A和B中的數據極有可能不對應而失去意義。
再回來看mongodump的操作。mongodump的進行過程中並不會把數據庫鎖死以保證整個庫凍結在一個固定的時間點,這在業務上常常是不允許的。所以就有了dump的最終結果中A集合是10點整的狀態,而B集合則是10點零1分的狀態這種情況。這樣的備份即使恢復回去,可以想象得到的結果恐怕意義有限。那麼上面這個oplog.bson的意義就在這裡體現出來了。如果在dump數據的基礎上,再重做一遍oplog中記錄的所有操作,這時的數據就可以代表dump結束時那個時間點(point-in-time)的數據庫狀態。
這個結論成立的重要條件就是冪等性:已存在的數據,重做oplog不會重復;不存在的數據重做oplog就可以進入數據庫。所以當做完截止到某個時間點的oplog時,數據庫就恢復到了截止那個時間點的狀態。
來看看mongorestore的選項。跟oplog相關的選項有--oplogReplay和--oplogLimit。第一個選項顧名思義,可以重放oplog.bson中的操作內容。第二個選項
後面再做介紹。先來看一個例子:
首先我們模擬一個不斷有插入操作的集合foo,
use test
for(var i = 0; i < 100000; i++) {
db.foo.insert({a: i});
}
然後在插入過程中模擬一次mongodump並指定--oplog。
mongodump -h 127.0.0.1 --oplog
注意--oplog選項只對全庫導出有效,所以不能指定-d選項。因為整個實例的變更操作都會集中在local庫中的oplog.rs集合中。
根據上面所說,從dump開始的時間系統將記錄所有的oplog到oplog.bson中,所以我們得到這些文件:
yaoxing ~ $ ll dump/
total 440
-rw-r--r-- 1 yaoxing yaoxing 442470 Sep 14 17:21 oplog.bson
drwxr-xr-x 2 yaoxing yaoxing 4096 Sep 14 17:21 test
其中test是我們剛才使用的數據庫,oplog.bson是導出期間進行的所有操作。如果對oplog.bson中的內容好奇,可以用bsondump工具來查看其中的內容,例如:
{"h":{"$numberLong":"2279811375157953332"},"ns":"test.foo","o":{"_id":{"$oid":"55f834ae6b530b5854f9d6ee"},"a":7784.0},"op":"i","ts":{"$timestamp":{"t":1442329774,"i":3248}},"v":2}
從oplog.bson中我們挑選第一條和最後一條內容出來觀察
{"h":{"$numberLong":"2279811375157953332"},"ns":"test.foo","o":{"_id":{"$oid":"55f834ae6b530b5854f9d6ee"},"a":7784.0},"op":"i","ts":{"$timestamp":{"t":1442329774,"i":3248}},"v":2}
...
{"h":{"$numberLong":"-1177358680665374097"},"ns":"test.foo","o":{"_id":{"$oid":"55f834b26b530b5854f9fa5e"},"a":16856.0},"op":"i","ts":{"$timestamp":{"t":1442329778,"i":1361}},"v":2}
紅字部分可以看出,從開始進行mongodump時,循環進行到i=7784,而到整個操作結束時,循環進行到i=16856。再看一下test/foo.bson中數據的最後一條
{"_id":{"$oid":"55f834ae6b530b5854f9d73d"},"a":7863.0}
可以發現,最終dump出的數據既不是最開始的狀態,也不是最後的狀態,而是中間某個隨機狀態。這正是因為集合不斷變化造成的。
那麼使用mongorestore來恢復:
yaoxing ~ $ mongorestore -h 127.0.0.1 --oplogReplay dump
2015-09-19T01:22:20.095+0800 building a list of dbs and collections to restore from dump dir
2015-09-19T01:22:20.095+0800 reading metadata for test.foo from
2015-09-19T01:22:20.096+0800 restoring test.foo from
2015-09-19T01:22:20.248+0800 restoring indexes for collection test.foo from metadata
2015-09-19T01:22:20.248+0800 finished restoring test.foo (7864 documents)
2015-09-19T01:22:20.248+0800 replaying oplog
2015-09-19T01:22:20.463+0800 done
注意紅字的兩句,第一句表示test.foo集合中恢復了7864個文檔;第二句表示重放了oplog中的所有操作。所以理論上foo應該有16857個文檔(7864個來自foo.bson,剩下的來自oplog.bson)。驗證一下:
test:PRIMARY> db.foo.count()
16857
這就是帶oplog的mongodump的真正作用。
1.2.3 從別處而來的oplog
聰明如你可能已經想到,既然dump出的數據配合oplog就可以把數據庫恢復到某個狀態,那是不是擁有一份從某個時間點開始備份的dump數據,再加上從dump開始之後的oplog,如果oplog足夠長,是不是就可以把數據庫恢復到其後的任意狀態了?是的!事實上replica set正是依賴oplog的重放機制在工作。當secondary第一次加入replica set時做的initial sync就相當於是在做mongodump,此後只需要不斷地同步和重放oplog.rs中的數據,就達到了secondary與primary同步的目的。
既然oplog一直都在oplog.rs中存在,我們為什麼還需要在mongodump時指定--oplog呢?需要的時候從oplog.rs中拿不就完了嗎?答案是肯定的,你確實可以只dump數據,不需要oplog。在需要的時候可以再從oplog.rs中取。但前提是oplog時間窗口(忘了時間窗口概念的請往前翻)必須能夠覆蓋dump的開始時間。
明白了這個道理,理論上只要我們的mongodump做得足夠頻繁,是可以保證數據庫能夠恢復到過去的任意一個時間點的。MMS(現在叫Cloud Manager)的付費備份也正是在利用這個原理工作。假設oplog時間窗口有24小時,那麼理論上只要我在每24小時內完成一次dump,即可保證dump之後的24小時的point-in-time數據恢復。在oplog時間窗口快要滑出24小時的時候,只要及時完成下一次dump,就又可以有24小時的安全期。
來做個測試。仍然使用前面的方法模擬一段時間的數據庫插入操作:
use test
for(var i = 0; i < 100000; i++) {
db.foo.insert({a: i});
}
同時做一次mongodump並不帶--oplog:
yaoxing ~/dump $ mongodump -h 127.0.0.1
2015-09-24T00:06:11.929+0800 writing test.system.indexes to dump/test/system.indexes.bson
2015-09-24T00:06:11.929+0800 done dumping test.system.indexes (1 document)
2015-09-24T00:06:11.929+0800 writing test.foo to dump/test/foo.bson
2015-09-24T00:06:11.963+0800 done dumping test.foo (11162 documents)
可見我們導出了i=11162時的狀態。等插入完成後,理論上我們的foo集合應該有100000條記錄
> use test
switched to db test
> db.foo.count()
100000
現在假設我進行了一次誤操作:
> db.foo.remove({})
WriteResult({ "nRemoved" : 100000 })
更慘的是我之後又往foo裡面插入了一條數據
> db.foo.insert({a: 100001});
WriteResult({ "nInserted" : 1 })
現在怎樣讓時間倒流,回到災難前的狀態呢?由於在災難前我們有過一次dump,因此現在只要在oplog時間窗口還能覆蓋導出時間之前把oplog搶救出來就好了:
yaoxing ~ $ mongodump -h 127.0.0.1 -d local -c oplog.rs
2015-09-24T00:09:41.040+0800 writing local.oplog.rs to dump/local/oplog.rs.bson
2015-09-24T00:09:41.525+0800 done dumping local.oplog.rs (200003 documents)
為什麼會有200003條記錄呢?請自行使用bsondump工具查看發生了什麼事情。
從前面講的可知,使用mongodump加oplog.bson(請注意文件位置)即可恢復數據庫。這裡的dump/local/oplog.rs.bson其實就是我們需要的oplog.bson。因此把它重命名後放到合適的位置,一個模擬出來的恢復環境就准備好了
yaoxing ~/dump $ ll
total 18464
-rw-r--r-- 1 yaoxing yaoxing 18900271 Sep 24 00:09 oplog.bson
drwxr-xr-x 2 yaoxing yaoxing 4096 Sep 24 00:06 test
但是這個oplog.bson可是包含了所有災難操作的啊,如果全盤恢復回去,就等於是先讓時光倒流,再看悲劇重演一遍。心都碎了……這時候你需要一個新朋友,就是上面提到的--oplogLimit。它與--oplogReplay一起使用時,可以限制重放到的時間點。那麼重要的問題就是如何找到災難發生的時間點了。仍然是bsondump。如果你對Linux命令熟悉,可以在管道中直接操作。如果不行,那就先dump到文件中,再用文本編輯器打開慢慢找好了。我們需要找的內容是"op":"d",它表示進行了一次刪除操作。可以發現,oplog.bson中有100000次刪除操作,實際上是一條一條把記錄刪除掉,這也是為什麼remove({})操作會這麼慢。如果對一個集合進行drop()就會快得多,它進行的操作請讀者自己嘗試。
yaoxing ~/dump $ bsondump oplog.bson | grep "\"op\":\"d\"" | head
{"b":true,"h":{"$numberLong":"5331406427126597755"},"ns":"test.foo","o":{"_id":{"$oid":"5602cdf1befd4a4bfb4d149b"}},"op":"d","ts":{"$timestamp":{"t":1443024507,"i":1}},"v":2}
...
此條記錄中我們需要的是紅色的$timestamp部分,它代表的發生這個操作的時間,也正是我們的--oplogLimit需要傳入的時間,只是格式稍稍有變:
yaoxing ~ $ mongorestore -h 127.0.0.1 --oplogReplay --oplogLimit "1443024507:1" dump/
2015-09-24T00:34:09.533+0800 building a list of dbs and collections to restore from dump dir
2015-09-24T00:34:09.534+0800 reading metadata for test.foo from
2015-09-24T00:34:09.534+0800 restoring test.foo from
2015-09-24T00:34:09.659+0800 restoring indexes for collection test.foo from metadata
2015-09-24T00:34:09.659+0800 finished restoring test.foo (11162 documents)
2015-09-24T00:34:09.659+0800 replaying oplog
2015-09-24T00:34:11.548+0800 done
其中1443024507即是$timestamp中的"t",1即是$timestamp中的"i"。這樣配置後oplog將會重放到這個時間點以前,即正好避開了第一條刪除語句及其後面的操作,數據庫停留在災難前狀態。驗證一下:
rs0:PRIMARY> db.foo.count()
100000
1.3 小結
結合上術知識,我們可以總結一些mongodb的備份准則(只針對replica或master/slave),滿足這些准則,MongoDB就可以進行point-in-time恢復操作:
任意兩次數據備份的時間間隔(第一次備份開始到第二次備份結束)不能超過oplog時間窗口覆蓋范圍。
在上次數據備份的基礎上,在oplog時間窗口沒有滑出上次備份結束的時間點前進行完整的oplog備份。請充分考慮oplog備份需要的時間,權衡服務器空間情況確定oplog備份間隔。
實際應用中的注意事項:
考慮到oplog時間窗口是個變化值,請關注oplog時間窗口的具體時間。
在靠近oplog時間窗口滑動出有效時間之前必須要有足夠的時間dump出需要的oplog.rs,請預留足夠的時間,不要頂滿時間窗口再備份。
當災難發生時,第一件事情就是要停止數據庫的寫入操作,以往oplog滑出時間窗口。特別是像上述這樣的remove({})操作,瞬間就會插入大量d記錄從而導致oplog迅速滑出時間窗口。
2. 外置方法
1. MMS/Cloud Manager
以前叫做MMS,監控功能免費,備份功能收費;前兩個月更名為Cloud Manager並開始對監控功能收費,另外增加一個運維自動化機器人,挺傻瓜化的,有興趣可以玩玩。不過既然收費,我相信我國國情決定了可能沒有幾個公司會願意使用。因此不做重點介紹,只要知道它能提供任意時間點的數據恢復就可以了,功能強大,土豪公司歡迎使用。
2. 磁盤快照
常見的如LVM快照,是可以用來備份MongoDB的,但必須開啟MongoDB的Journal並且Journal必須和數據文件在一個卷上。話說應該多數人都是開啟Journal的吧?沒有Journal的話斷電是會丟失最多60s的數據的。
快照其實是一個較mongodump/mongorestore來得更快的備份方式,相當實用,但只能提供到備份時間點的數據恢復,作用有限。不展開細說,有興趣可以查閱官方文檔。理論上說,快照當然也可以結合oplog重放來達到point-in-time數據恢復的。但是本人沒有親身實驗,有興趣的朋友可以玩玩並做個介紹。