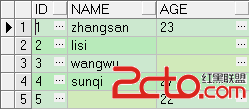
MongoDb 創建、更新以及刪除文檔常用命令
mongodb由C++寫就,其名字來自humongous這個單詞的中間部分,從名字可見其野心所在就是海量數據的處理。關於它的一個最簡潔描述為:scalable, high-performance, open source, schema-free, document-oriented database。MongoDB的主要目標是在鍵/值存儲方式(提供了高性能和高度伸縮性)以及傳統的RDBMS系統(豐富的功能)架起一座橋梁,集兩者的優勢於一身。
安裝及使用:
首先在Ubuntu上安裝MongoDB。
下載MongoDB, 現在最新的生產版本1.7.0
1. 解壓文件.
$ tar -xvf mongodb-linux-i686-1.4.3.tgz
2. 為MongoDB創建數據目錄,默認情況下它將數據存儲在/data/db
$ sudo mkdir -p /data/db/
$ sudo chown `id -u` /data/db
3. 啟動MongoDB服務.
$ cd mongodb-linux-i686-1.4.3/bin
$ ./mongod
4. 打開另一個終端,並確保你在MongoDB的bin目錄,輸入如下命令.
$ ./mongo
一些概念
一個mongod服務可以有建立多個數據庫,每個數據庫可以有多張表,這裡的表名叫collection,每個collection可以存放多個文檔(document),每個文檔都以BSON(binary json)的形式存放於硬盤中,因此可以存儲比較復雜的數據類型。它是以單文檔為單位存儲的,你可以任意給一個或一批文檔新增或刪除字段,而不會對其它文檔造成影響,這就是所謂的schema-free,這也是文檔型數據庫最主要的優點。跟一般的key-value數據庫不一樣的是,它的value中存儲了結構信息,所以你又可以像關系型數據庫那樣對某些域進行讀寫、統計等操作。Mongo最大的特點是他支持的查詢語言非常強大,其語法有點類似於面向對象的查詢語言,幾乎可以實現類似關系數據庫單表查詢的絕大部分功能,而且還支持對數據建立索引。Mongo還可以解決海量數據的查詢效率,根據官方文檔,當數據量達到50GB以上數據時,Mongo數據庫訪問速度是MySQL10 倍以上。
BSON
BSON是Binary JSON 的簡稱,是一個JSON文檔對象的二進制編碼格式。BSON同JSON一樣支持往其它文檔對象和數組中再插入文檔對象和數組,同時擴展了JSON的數據類型。如:BSON有Date類型和BinDate類型。
BSON被比作二進制的交換格式,如同Protocol Buffers,但BSON比它更“schema-less”,非常好的靈活性但空間占用稍微大一點。
BSON有以下三個特點:
1. 輕量級
2. 跨平台
3. 效率高
命名空間
MongoDB存儲BSON對象到collections,這一系列的數據庫名和collection名被稱為一個命名空間。如同:java.util.List;用來管理數據庫中的數據。
索引
mongodb可以對某個字段建立索引,可以建立組合索引、唯一索引,也可以刪除索引,建立索引就意味著增加空間開銷。默認情況下每個表都會有一個唯一索引:_id,如果插入數據時沒有指定_id,服務會自動生成一個_id,為了充分利用已有索引,減少空間開銷,最好是自己指定一個unique的key為_id,通常用對象的ID比較合適,比如商品的ID。
shell操作數據庫:
1. 超級用戶相關:
1. #進入數據庫admin
use admin
2. #增加或修改用戶密碼
db.addUser('name','pwd')
3. #查看用戶列表
db.system.users.find()
4. #用戶認證
db.auth('name','pwd')
5. #刪除用戶
db.removeUser('name')
6. #查看所有用戶
show users
7. #查看所有數據庫
show dbs
8. #查看所有的collection
show collections
9. #查看各collection的狀態
db.printCollectionStats()
10. #查看主從復制狀態
db.printReplicationInfo()
11. #修復數據庫
db.repairDatabase()
12. #設置記錄profiling,0=off 1=slow 2=all
db.setProfilingLevel(1)
13. #查看profiling
show profile
14. #拷貝數據庫
db.copyDatabase('mail_addr','mail_addr_tmp')
15. #刪除collection
db.mail_addr.drop()
16. #刪除當前的數據庫
db.dropDatabase()
2. 增刪改
1. #存儲嵌套的對象
db.foo.save({'name':'ysz','address':{'city':'beijing','post':100096},'phone':[138,139]})
2. #存儲數組對象
db.user_addr.save({'Uid':'yushunzhi@sohu.com','Al':['test-1@sohu.com','test-2@sohu.com']})
3. #根據query條件修改,如果不存在則插入,允許修改多條記錄
db.foo.update({'yy':5},{'$set':{'xx':2}},upsert=true,multi=true)
4. #刪除yy=5的記錄
db.foo.remove({'yy':5})
5. #刪除所有的記錄
db.foo.remove()
3. 索引
1. #增加索引:1(ascending),-1(descending)
2. db.foo.ensureIndex({firstname: 1, lastname: 1}, {unique: true});
3. #索引子對象
4. db.user_addr.ensureIndex({'Al.Em': 1})
5. #查看索引信息
6. db.foo.getIndexes()
7. db.foo.getIndexKeys()
8. #根據索引名刪除索引
9. db.user_addr.dropIndex('Al.Em_1')
4. 查詢
1. #查找所有
2. db.foo.find()
3. #查找一條記錄
4. db.foo.findOne()
5. #根據條件檢索10條記錄
6. db.foo.find({'msg':'Hello 1'}).limit(10)
7. #sort排序
8. db.deliver_status.find({'From':'ixigua@sina.com'}).sort({'Dt',-1})
9. db.deliver_status.find().sort({'Ct':-1}).limit(1)
10. #count操作
11. db.user_addr.count()
12. #distinct操作,查詢指定列,去重復
13. db.foo.distinct('msg')
14. #”>=”操作
15. db.foo.find({"timestamp": {"$gte" : 2}})
16. #子對象的查找
17. db.foo.find({'address.city':'beijing'})
5. 管理
1. #查看collection數據的大小
2. db.deliver_status.dataSize()
3. #查看colleciont狀態
4. db.deliver_status.stats()
5. #查詢所有索引的大小
6. db.deliver_status.totalIndexSize()
5. advanced queries:高級查詢
條件操作符
$gt : >
$lt : <
$gte: >=
$lte: <=
$ne : !=、<>
$in : in
$nin: not in
$all: all
$not: 反匹配(1.3.3及以上版本)
查詢 name <> "bruce" and age >= 18 的數據
db.users.find({name: {$ne: "bruce"}, age: {$gte: 18}});
查詢 creation_date > '2010-01-01' and creation_date <= '2010-12-31' 的數據
db.users.find({creation_date:{$gt:new Date(2010,0,1), $lte:new Date(2010,11,31)});
查詢 age in (20,22,24,26) 的數據
db.users.find({age: {$in: [20,22,24,26]}});
查詢 age取模10等於0 的數據
db.users.find('this.age % 10 == 0');
或者
db.users.find({age : {$mod : [10, 0]}});
匹配所有
db.users.find({favorite_number : {$all : [6, 8]}});
可以查詢出{name: 'David', age: 26, favorite_number: [ 6, 8, 9 ] }
可以不查詢出{name: 'David', age: 26, favorite_number: [ 6, 7, 9 ] }
查詢不匹配name=B*帶頭的記錄
db.users.find({name: {$not: /^B.*/}});
查詢 age取模10不等於0 的數據
db.users.find({age : {$not: {$mod : [10, 0]}}});
#返回部分字段
選擇返回age和_id字段(_id字段總是會被返回)
db.users.find({}, {age:1});
db.users.find({}, {age:3});
db.users.find({}, {age:true});
db.users.find({ name : "bruce" }, {age:1});
0為false, 非0為true
選擇返回age、address和_id字段
db.users.find({ name : "bruce" }, {age:1, address:1});
排除返回age、address和_id字段
db.users.find({}, {age:0, address:false});
db.users.find({ name : "bruce" }, {age:0, address:false});
數組元素個數判斷
對於{name: 'David', age: 26, favorite_number: [ 6, 7, 9 ] }記錄
匹配db.users.find({favorite_number: {$size: 3}});
不匹配db.users.find({favorite_number: {$size: 2}});
$exists判斷字段是否存在
查詢所有存在name字段的記錄
db.users.find({name: {$exists: true}});
查詢所有不存在phone字段的記錄
db.users.find({phone: {$exists: false}});
$type判斷字段類型
查詢所有name字段是字符類型的
db.users.find({name: {$type: 2}});
查詢所有age字段是整型的
db.users.find({age: {$type: 16}});
對於字符字段,可以使用正則表達式
查詢以字母b或者B帶頭的所有記錄
db.users.find({name: /^b.*/i});
$elemMatch(1.3.1及以上版本)
為數組的字段中匹配其中某個元素
Javascript查詢和$where查詢
查詢 age > 18 的記錄,以下查詢都一樣
db.users.find({age: {$gt: 18}});
db.users.find({$where: "this.age > 18"});
db.users.find("this.age > 18");
f = function() {return this.age > 18} db.users.find(f);
排序sort()
以年齡升序asc
db.users.find().sort({age: 1});
以年齡降序desc
db.users.find().sort({age: -1});
限制返回記錄數量limit()
返回5條記錄
db.users.find().limit(5);
返回3條記錄並打印信息
db.users.find().limit(3).forEach(function(user) {print('my age is ' + user.age)});
結果
my age is 18
my age is 19
my age is 20
限制返回記錄的開始點skip()
從第3條記錄開始,返回5條記錄(limit 3, 5)
db.users.find().skip(3).limit(5);
查詢記錄條數count()
db.users.find().count();
db.users.find({age:18}).count();
以下返回的不是5,而是user表中所有的記錄數量
db.users.find().skip(10).limit(5).count();
如果要返回限制之後的記錄數量,要使用count(true)或者count(非0)
db.users.find().skip(10).limit(5).count(true);
分組group()
假設test表只有以下一條數據
{ domain: "www.mongodb.org"
, invoked_at: {d:"2009-11-03", t:"17:14:05"}
, response_time: 0.05
, http_action: "GET /display/DOCS/Aggregation"
}
使用group統計test表11月份的數據count:count(*)、total_time:sum(response_time)、avg_time:total_time/count;
db.test.group(
{ cond: {"invoked_at.d": {$gt: "2009-11", $lt: "2009-12"}}
, key: {http_action: true}
, initial: {count: 0, total_time:0}
, reduce: function(doc, out){ out.count++; out.total_time+=doc.response_time }
, finalize: function(out){ out.avg_time = out.total_time / out.count }
} );
[
{
"http_action" : "GET /display/DOCS/Aggregation",
"count" : 1,
"total_time" : 0.05,
"avg_time" : 0.05
}
]