oracle中的分區表在系統中使用的頻率不小,在一些數據量大的系統中更是頻繁出現。
提到分區表,首先就要理解下什麼是分區。其實所謂的分區簡單來說就是分區域,分區表就是將一張表分區域存放。
那麼分區域中的區域又指的是哪裡?
那就是傳說中存放表的地方--->表空間。
表空間:是一個或多個數據文件的集合,所有的數據對象都存放在指定的表空間中,但主要存放的是表, 所以稱作表空間。
那麼為什麼要把一張好好的表分開來存放。
當表中的數據量不斷增大,查詢數據的速度就會變慢,應用程序的性能就會下降,這時就應該考慮對表進行分區。
表進行分區後,邏輯上表仍然是一張完整的表,只是將表中的數據在物理上存放到多個“表空間”(物理文件上),這樣查詢數據時,不至於每次都掃描整張表而只是從當前的分區查到所要的數據大大提高了數據查詢的速度。
前面提到了,一般數據量大的系統中分區表的使用是比較頻繁的。
那麼一般我們什麼時候要建立分區表呢?
1、表的大小超過2GB。
2、表中包含歷史數據,新的數據被增加到新的分區中。
使用表分區在解決大數據量表的基礎上, 還有下面幾個優點:
1、改善查詢性能:對分區對象的查詢可以僅搜索自己關心的分區,提高檢索速度。
2、增強可用性:如果表的某個分區出現故障,表在其他分區的數據仍然可用;
3、維護方便:如果表的某個分區出現故障,需要修復數據,只修復該分區即可;
4、均衡I/O:可以把不同的分區映射到不同磁盤以平衡I/O,改善整個系統性能。
一般的普通表如果要轉化為分區表,要用到oracle提供的在線重定義表。
可以參考文章:http://www.cnblogs.com/hfliyi/p/3626302.html
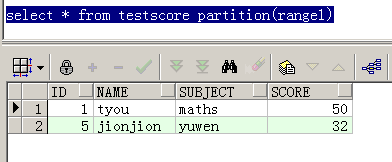
分區表中有一個概念,叫分區字段。那麼如何確認分區字段,一張分區表的分區字段是根據什麼來確定的。
這裡我們只聊兩種常用情況。
1. 按范圍分區(比如說交易歷史表中的交易完成時間,日志表中的事件發生時間)
2. 按列表分區(比如某張業務表中的狀態值)
多說一句:選取分區字段和選取索引字段一樣, 對這個字段的辨識度要求都比較高。
用數序上的極端分析來說,一個字段的辨識度最低就是這個字段只有一個值,那麼在這個上面做索引或者分區,那肯定是狗血透了。
而且分區字段應該能保證表數據的分布基本上是均勻的, 如果有100w條數據,有一個狀態列,只有一條狀態是inactive的,其他都是active,那麼這個字段雖然可以按列表分區,但是卻達不到我們建立分區表的目的。