Oracle的group by除了基本用法以外,還有3種擴展用法,分別是rollup、cube、grouping sets,分別介紹如下:
1、rollup
對數據庫表emp,假設其中兩個字段名為a,b,c。
如果使用group by rollup(a,b),首先會對(a,b)進行group by ,然後對 a 進行 group by ,最後對全表進行 group by 操作。
如下查詢結果:
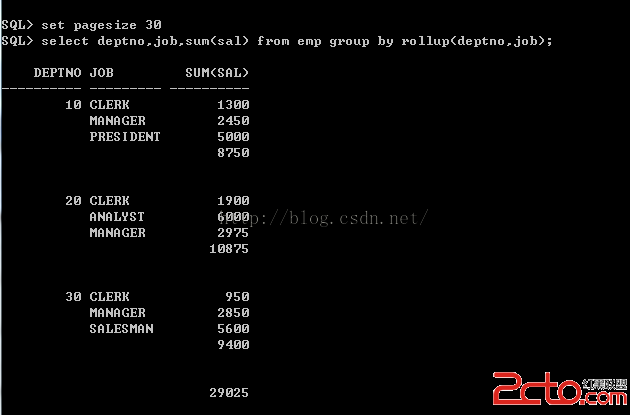
查詢語句
Select deptno,job,sum(sal) from emp group by rollup(deptno,job);
等同於
Select deptno,job,sum(sal) from emp group by deptno,job
union all
Select deptno,null sum(sal) from emp group by deptno
union all
Select null,null,sum(sal) from emp (group by null )
2、cube
如果使用group by cube(a,b),,則首先會對(a,b)進行group by,然後依次是(a),(b),最後對全表進行group by 操作,一共是2^2=4次grouping
如下查詢結果;
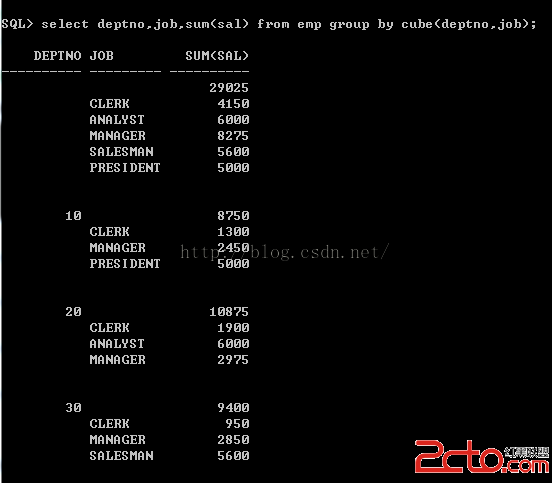
查詢語句
Select deptno,job,sum(sal) from emp group by cube(deptno,job);
等同於
Select deptno,job,sum(sal) from emp group by deptno,job
union all
Select deptno,null sum(sal) from emp group by deptno
union all
Select null,job, sum(sal) from emp group by job
union all
Select null,null,sum(sal) from emp (group by null )
3、grouping sets
grouping sets就是對參數中的每個參數做grouping,如果使用group by grouping sets(a,b),則對(a),(b)進行group by
如下查詢結果:
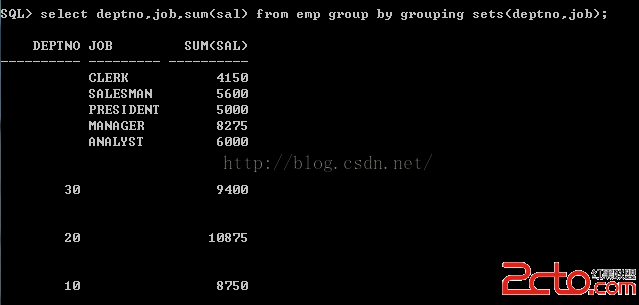
查詢語句
Select deptno,job,sum(sal) from emp group by cube(deptno,job);
等同於
select null,job,sum(sal) from emp group by job
union all
select deptno,null,sum(sal) from emp group by deptno
4、grouping
使用grouping可以判斷該行是數據庫中本來的行,還是有統計產生的行,grouping值為0時說明這個值是數據庫中本來的值,為1說明是統計的結果,參數只有一個,而且必須為group by中出現的某一列
如下查詢結果:
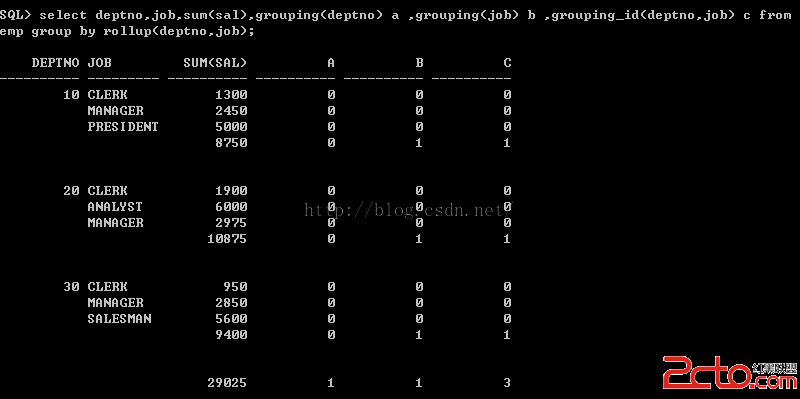
查詢語句
select deptno,job,sum(sal),grouping(deptno) a,grouping(job) b from emp group by rollup(deptno,job);
5、grouping_id
Grouping_id()的返回值其實就是參數中的每列的grouping()值的二進制向量,如果grouping(a)=1,grouping(b)=1,則grouping_id(A,B)的返回值就是二進制的11,轉成10進制就是3。參數可以是多個,但必須為group by中出現的列。
查詢結果如下:
查詢語句
select deptno,job,sum(sal),grouping(deptno) a,grouping(job) b,grouping_id(deptno,job) from emp group by rollup(deptno,job);
6、group_id
GROUP_ID()唯一標識重復組,可以通過group_id去除重復組
查詢結果如下:
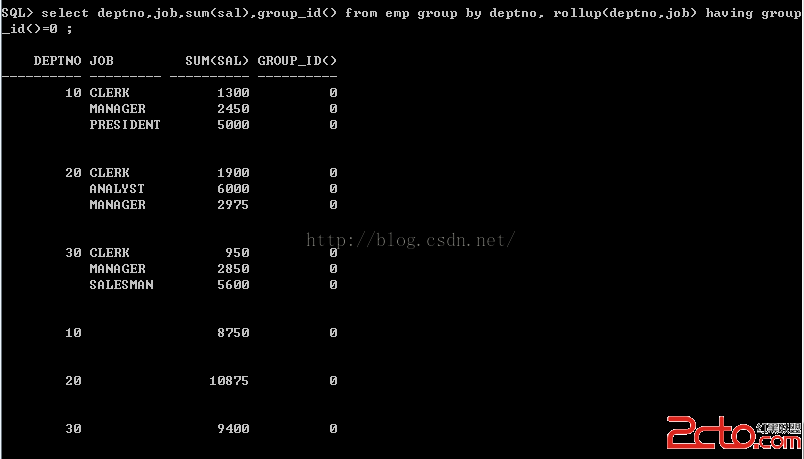
查詢語句
select deptno,job,sum(sal),group_id() from emp group by deptno, rollup(deptno,job) having group_id()=0;