項目開發中,我們有時會碰到需要分組排序來解決問題的情況:
1、要求取出按field1分組後,並在每組中按照field2排序;
2、亦或更加要求取出1中已經分組排序好的前多少行的數據
這裡通過一張表的示例和SQL語句闡述下oracle數據庫中用於分組排序函數的用法。
1.row_number() over()
row_number()over(partition by col1 order by col2)表示根據col1分組,在分組內部根據col2排序,而此函數計算的值就表示每組內部排序後的順序編號(組內連續的唯一的)。
與rownum的區別在於:使用rownum進行排序的時候是先對結果集加入偽劣rownum然後再進行排序,而此函數在包含排序從句後是先排序再計算行號碼。row_number()和rownum差不多,功能更強一點(可以在各個分組內從1開始排序)。
2.rank() over()
rank()是跳躍排序,有兩個第二名時接下來就是第四名(同樣是在各個分組內)
3.dense_rank() over()
dense_rank()也是連續排序,有兩個第二名時仍然跟著第三名。相比之下row_number是沒有重復值的。
示例:
如有表Test,數據如下
SQL代碼:
CREATEDATE ACCNO MONEY
2014/6/5 111 200
2014/6/4 111 600
2014/6/5 111 400
2014/6/6 111 300
2014/6/6 222 200
2014/6/5 222 800
2014/6/6 222 500
2014/6/7 222 100
2014/6/6 333 800
2014/6/7 333 500
2014/6/8 333 200
2014/6/9 333 0
比如要根據ACCNO分組,並且每組按照CREATEDATE排序,是組內排序,並不是所有的數據統一排序,
用下列語句實現:
Sql代碼
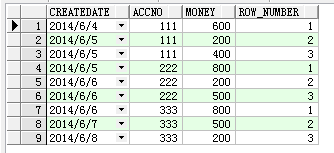
select t.*,row_number() over(partition by accno order by createDate) row_number from Test t
查詢結果如下:
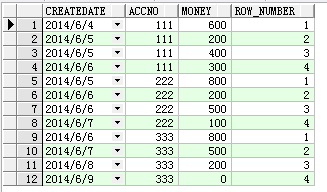
大家可以注意到ACCNO為111的記錄有兩個相同的CREATEDATE,用row_number函數,他們的組內計數是連續唯一的,但是如果用rank或者dense_rank函數,效果就不一樣,
如下:
rank的sql:
select t.*,rank() over(partition by accno order by createDate) rank from Test t
查詢結果:
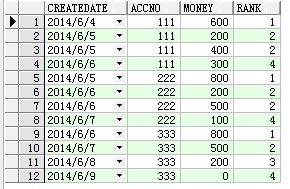
可以發現相同CREATEDATE的兩條記錄是兩個第2時接下來就是第4.
dense_rank的sql:
Sql代碼
select t.*,dense_rank() over(partition by accno order by createDate) dense_rank from Test t
查詢結果:
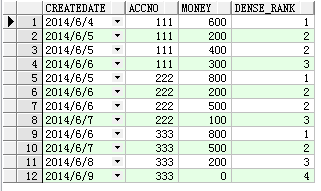
可以發現相同CREATEDATE的兩個字段是兩個第2時接下來就是第3.
項目中特殊的業務需求可能會要求用以上三個不同的函數,具體情況具體對待。
再比如有時會要求分組排序後分別取出各組內前多少的數據記錄,sql如下:
Sql代碼
select createDate,accno,money,row_number from (select t.*,row_number() over(partition by accno order by createDate) row_number from Test t) t1 where row_number<4
查詢結果如下: