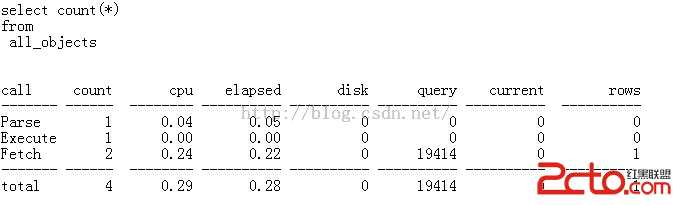
數據庫的索引就類似於書本的目錄,索引指向查詢內容所在的位置(如書中的頁碼),減少了磁盤I/O次數。數據庫程序不必掃描整張表,直接通過索引就可以迅速找到要查找的內容。
聚集索引:對於我們認識的字可以通過拼音進行查找,拼音也即是索引,索引的順序也就是數據的物理順序。我們把這種數據按照索引的順序進行存儲,確定表中數據的物理順序的方式稱為聚集索引。因為數據的物理順序只有一種,所以一個表只能有一個聚集索引。聚集索引效率高,但對數據更新影響大,不適用於頻繁更新的列。
非聚集索引:對於我們不認識的字,需要查找偏旁部首目錄找到該字所在的頁碼,然後通過頁碼找到相應的字。我們把這種數據存儲在一個地方,索引存儲在另一個地方,索引帶有一指針指向數據的存儲位置的方式稱為非聚集索引。聚集索引效率低,影響小。
ROWID存儲了行在數據庫文件中的具體位置:64位(A-Z, a-z, 0-9, +, /),ROWID由四部分組成:OOOOOOOFFFBBBBBBRRR
OOOOOO:數據對象編號(6位顯示)
FFF:相關數據文件編號(3位顯示)
BBBBBB:數據塊編號(6位顯示)
RRR:數據塊中行編號(3位顯示)
(1)大大提高數據檢索、分組、排序的速度
(2)對數據庫表進行增、刪、改操作需要動態維護索引需要耗費時間,數據量越大,耗時越多
(3)每個索引會占用一定的物理空間
(1)WHERE、ORDER BY子句中使用最頻繁的字段
(2)經常被分組排序的列
(3)連接兩個表的連接字段
(4)具有高選擇性(相同值少)的字段
(5)小字段上(不要在大的文本字段甚至超長字段上建立索引)
(6)不會經常更新的字段
(7)索引字段盡量使用數字型字段,字符類型會逐個比較字符串中的每個字符,而數字只需比較一次。
(8)盡可能使用varchar/nvarchar代替char/nchar,因為變長字段存儲空間小,效率高些。
(9)如果單列索引中包含空值,索引中將不存在此記錄。如果復合索引的每個列都為空,索引中不存在此記錄;至少有一個列不為空,此記錄存在於索引中。
(1)若幾個字段經常同時以AND方式出現在WHERE子句中,且單字段查詢比較少,則考慮建立復合索引。
(2)復合索引的字段個數一般不要超過3個
(3)如果既有單字段索引,又有這幾個字段的復合索引,一般可以刪除復合索引
(4)考慮將WHERE子句中使用最頻繁的字段放在復合索引的第一位。若使用頻率相同,數據在物理上按某一個字段排序的,則將這個字段放在復合索引的第一位;若使用頻率相同,則將最具選擇性的字段排在最前面,將最不具選擇性的字段排在最後面。
(5)復合索引的第一列作為條件才能保證系統使用該索引,且讓條件中的字段順序與索引順序一致。
(1)不要對索引列進行is null, is not null判斷
(2)不要對索引列使用!=, <>, >操作符和NOT操作
(3)不要對索引列進行函數、算術或其他表達式(如+, ||)運算
(4)不要對索引使用帶通配符%的like操作
(5)顯示轉換數據類型。當比較不同數據類型的數據時, ORACLE自動對其進行類型轉換,當字符和數值比較時, ORACLE會優先將數值類型轉換成字符類型。因為內部發生的類型轉換, 這個索引將不會被使用。