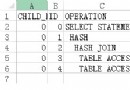
簡單來說就是數據庫根據索引找到了指定的記錄所在行後,還需要根據rowid再次到數據塊裡取數據的操作。
"回表"一般就是指執行計劃裡顯示的"TABLE ACCESS BY INDEX ROWID"。
例如select的字段裡有索引不包含的列
根據tom的oracle編程藝術,建表big_table,300W數據。
建索引:
create index idx_big_table_created on big_table(created);
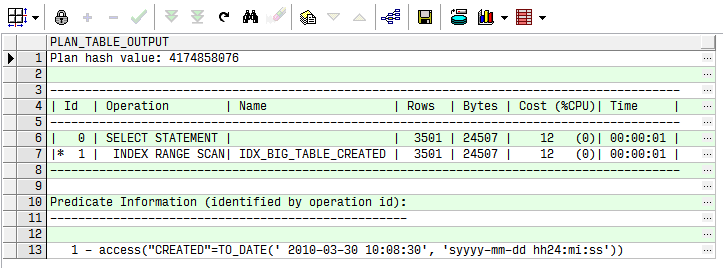
下面語句不會回表,因為只查詢了索引列。
explain plan for
select created
from big_table a
where created = to_date('2010/3/30 10:08:30', 'yyyy/mm/dd hh24:mi:ss');
select * from table(dbms_xplan.display)
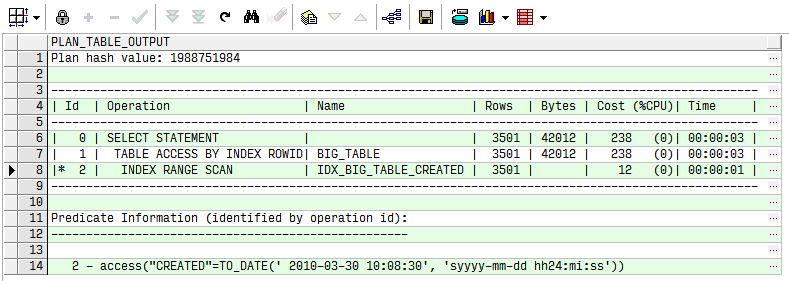
下面語句要回表,因為還查詢了除索引列的其他列,雖然id字段是主鍵。
explain plan for
select id,created
from big_table a
where created = to_date('2010/3/30 10:08:30', 'yyyy/mm/dd hh24:mi:ss');
select * from table(dbms_xplan.display)
當某個索引包含有多個已索引的列時,稱這個索引為組合(concatented)索引。
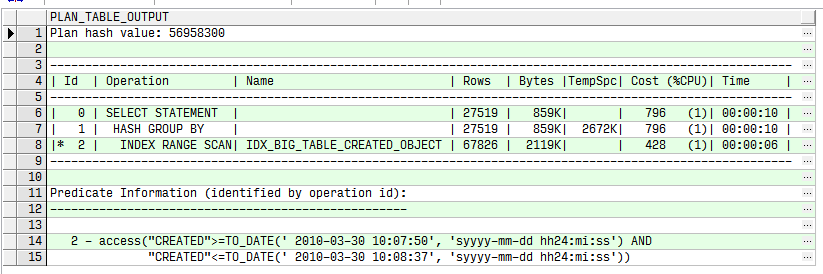
下面語句不會回表:
explain plan for
select object_name, count(1)
from big_table a
where created >= to_date('2010/3/30 10:07:50','yyyy/mm/dd hh24:mi:ss')
and created <= to_date('2010/3/30 10:08:37','yyyy/mm/dd hh24:mi:ss')
group by object_name;
select * from table(dbms_xplan.display)
1.一個表建立多少個索引比較合適?比如說不大於5個
這個沒有定論,樓主要綜合查詢效率和dml效率自己確定,索引可以加快select的查詢速度,但也會降低delete,insert和update等dml語句的執行速度。
2.聯合索引比單索引的效率高麼?
如果聯合索引中的多個字段都在where謂詞中出現了,則聯合索引效率比單列索引高,因為通過多個條件可以從索引中過濾得到更少的記錄條數,也就減少了需要回表掃描的次數,甚至可以直接在聯合索引中得到所查的所有結果,則不再需要回表。
但是由於多列的聯合索引肯定要比單列索引大,也就是說同樣的索引需要存儲的物理塊要多於單列索引,所以,如果查詢中只出現了聯合索引中的某一列,則其效率不如單列索引。
3.compress 這個壓縮 ,能起到什麼作用?
沒研究過
4.上網上查資料時,都說oracle使用聯合索引需要前導列,這個和版本有關系嗎?
前導列跟版本沒有關系。
前導列的概念是這樣的,如果建立了f1,f2上的聯合索引,則在查詢時必須要用到f1,也就是所謂的前導列,該索引才會有效,因為索引是按照前導列排序的,如果where條件謂詞中沒有前導列,則需要執行索引掃描才能得到想要的結果,這種情況下其效率往往較差。
5.如果不需要前導列的話,reverse 這個反轉 又起到什麼作用呢?
鑒於前面描述的前導列的概念,我們考慮如下表存儲table(f1,f2);
aa 1
ab 2
ac 3
ad 4
ae 5
如果我們對表table建立f1上的普通索引,由於按照f1進行排序,所以針對where f1=ad則需要遍歷所有的a開始的索引,而如果對f1建立reverse索引,則由於da只有一個,則可以更快的得到需要的結果。