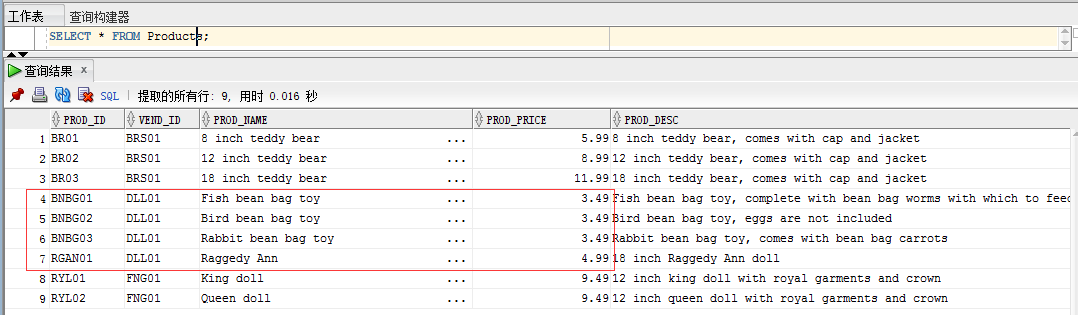
大概168個換熱站機組,每套機組將近400個點,整體有6萬多個點需要進行實時更新。數據庫裡其中有一個監控參數表(yxjk_jkcs),每一個點位屬性都在裡面存放,其中有一個字段CS_VALUE 是存放被更新的實時數據。
所有數據更新一次的時間,大概為10分鐘,而達不到2分鐘一更新的實時數據要求的效果。而且數據在更新的過程中,對服務器的資源利用量很大。
查看了Buffer Cache Size
以及Shared Pool Size ,這兩個一個是負責結果集的緩存大小,一個是負責存儲解析SQL語句
select *from dict where table_name like '%SGA%'—全局緩存
select *from v$version;--數據庫版本情況
select *from v$sgastat WHERE POOL='shared pool' order by bytes desc;
SELECT *FROM V$SGAINFO;
select *from v$sgastat;
select *from v$sga;
select *from v$sga_value;
select *from v$sgastat where pool='shared pool'
selectvalue/1024/1024 from v$parameter where name like '%sga_target%';
從語句的返回結果中判斷,緩存區的字節大小為400兆,而32位系統,oracle最大可以支持到1.7G。根據這樣的結果,對緩存區進行了設置,擴大到了1.4G,保證內存的使用空間。
select * from v$sql wherelower(sql_text) like lower('%yxjk_jkcs%');
然後根據以上的語句得出,語句的執行次數比較多,說明沒有執行預編譯。
declare i number;
begin
for i in 1 .. 60000 loop
update yxjk_jkcs set CS_VALUE='{體驗中換熱站154.tyzx154.scyx_echysx}'where JKD_ID='tyzx154' and CS_ID='scyx_echysx';
end loop;
rollback;
end;
利用oracle本身實驗了一下循環預編譯,發現執行6萬次只用幾秒。同時發現這個表中的參與的兩個查詢條件 JKD_ID和CS_ID是分開的索引。於是把這兩個字段聯合起來建立了一個索引。速度又增快了一些。