這個比較簡單,用||或concat函數可以實現
SQL Code
1
2
select concat(id,username) str from app_user
select id||username str from app_user
實際上就是拆分字符串的問題,可以使用 substr、instr、regexp_substr函數方式
使用union all函數等方式
首先讓我們來看看這個神奇的函數wm_concat(列名),該函數可以把列值以","號分隔起來,並顯示成一行,接下來上例子,看看這個神奇的函數如何應用准備測試數據
SQL Code
1
2
3
4
5
6
create table test(id number,name varchar2(20));
insert into test values(1,'a');
insert into test values(1,'b');
insert into test values(1,'c');
insert into test values(2,'d');
insert into test values(2,'e');
SQL Code
1
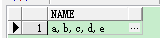
select wm_concat(name) name from test;
SQL Code
1
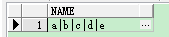
select replace(wm_concat(name),',','|') from test;
SQL Code
1
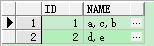
select id,wm_concat(name) name from test group by id;
sql語句等同於下面的sql語句:
SQL Code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
-------- 適用范圍:8i,9i,10g及以後版本 ( MAX + DECODE )
select id,
max(decode(rn, 1, name, null)) ||
max(decode(rn, 2, ',' || name, null)) ||
max(decode(rn, 3, ',' || name, null)) str
from (select id,
name,
row_number() over(partition by id order by name) as rn
from test) t
group by id
order by 1;
-------- 適用范圍:8i,9i,10g及以後版本 ( ROW_NUMBER + LEAD )
select id, str
from (select id,
row_number() over(partition by id order by name) as rn,
name || lead(',' || name, 1) over(partition by id order by name) ||
lead(',' || name, 2) over(partition by id order by name) ||
lead(',' || name, 3) over(partition by id order by name) as str
from test)
where rn = 1
order by 1;
-------- 適用范圍:10g及以後版本 ( MODEL )
select id, substr(str, 2) str
from test model return updated rows partition by(id) dimension by(row_number()
over(partition by id order by name) as rn) measures(cast(name as varchar2(20)) as str)
rules upsert iterate(3) until(presentv(str [ iteration_number + 2 ], 1, 0) = 0)
(str [ 0 ] = str [ 0 ] || ',' || str [ iteration_number + 1 ])
order by 1;
-------- 適用范圍:8i,9i,10g及以後版本 ( MAX + DECODE )
select t.id id, max(substr(sys_connect_by_path(t.name, ','), 2)) str
from (select id, name, row_number() over(partition by id order by name) rn
from test) t
start with rn = 1
connect by rn = prior rn + 1
and id = prior id
group by t.id;
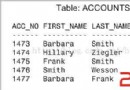
案例: 我要寫一個視圖,類似"create or replace view as select 字段1,...字段50 from tablename" ,基表有50多個字段,要是靠手工寫太麻煩了,有沒有什麼簡便的方法? 當然有了,看我如果應用wm_concat來讓這個需求變簡單,假設我的APP_USER表中有(id,username,password,age)4個字段。查詢結果如下
SQL Code
1
2
3
4
5
/** 這裡的表名默認區分大小寫 */
select 'create or replace view as select ' || wm_concat(column_name) ||
' from APP_USER' sqlStr
from user_tab_columns
where table_name = 'APP_USER';

利用系統表方式查詢
SQL Code
1
select * from user_tab_columns
在Oracle 11g中,Oracle 又增加了2個查詢:pivot(行轉列) 和unpivot(列轉行)
參考:http://blog.csdn.net/tianlesoftware/article/details/7060306、http://www.oracle.com/technetwork/cn/articles/11g-pivot-101924-zhs.html
google 一下,網上有一篇比較詳細的文檔:http://www.oracle-developer.net/display.php?id=506
測試數據 (id,類型名稱,銷售數量),案例:根據水果的類型查詢出一條數據顯示出每種類型的銷售數量。
SQL Code
1
2
3
4
5
6
7
8
9
create table demo(id int,name varchar(20),nums int); ---- 創建表
insert into demo values(1, '蘋果', 1000);
insert into demo values(2, '蘋果', 2000);
insert into demo values(3, '蘋果', 4000);
insert into demo values(4, '橘子', 5000);
insert into demo values(5, '橘子', 3000);
insert into demo values(6, '葡萄', 3500);
insert into demo values(7, '芒果', 4200);
insert into demo values(8, '芒果', 5500);
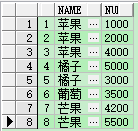
分組查詢 (當然這是不符合查詢一條數據的要求的)
SQL Code
1
select name, sum(nums) nums from demo group by name

行轉列查詢
SQL Code
1
select * from (select name, nums from demo) pivot (sum(nums) for name in ('蘋果' 蘋果, '橘子', '葡萄', '芒果'));

注意: pivot(聚合函數 for 列名 in(類型)) ,其中 in('') 中可以指定別名,in中還可以指定子查詢,比如 select distinct code from customers
當然也可以不使用pivot函數,等同於下列語句,只是代碼比較長,容易理解
SQL Code
1
2
3
4
5
select *
from (select sum(nums) 蘋果 from demo where name = '蘋果'),
(select sum(nums) 橘子 from demo where name = '橘子'),
(select sum(nums) 葡萄 from demo where name = '葡萄'),
(select sum(nums) 芒果 from demo where name = '芒果');
顧名思義就是將多列轉換成1列中去
案例:現在有一個水果表,記錄了4個季度的銷售數量,現在要將每種水果的每個季度的銷售情況用多行數據展示。
創建表和數據
SQL Code
1
2
3
4
5
6
create table Fruit(id int,name varchar(20), Q1 int, Q2 int, Q3 int, Q4 int);
insert into Fruit values(1,'蘋果',1000,2000,3300,5000);
insert into Fruit values(2,'橘子',3000,3000,3200,1500);
insert into Fruit values(3,'香蕉',2500,3500,2200,2500);
insert into Fruit values(4,'葡萄',1500,2500,1200,3500);
select * from Fruit
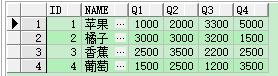
列轉行查詢
SQL Code
1
select id , name, jidu, xiaoshou from Fruit unpivot (xiaoshou for jidu in (q1, q2, q3, q4) )
注意: unpivot沒有聚合函數,xiaoshou、jidu字段也是臨時的變量
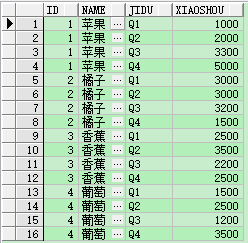
同樣不使用unpivot也可以實現同樣的效果,只是sql語句會很長,而且執行速度效率也沒有前者高
SQL Code
1
2
3
4
5
6
7
select id, name ,'Q1' jidu, (select q1 from fruit where id=f.id) xiaoshou from Fruit f
union
select id, name ,'Q2' jidu, (select q2 from fruit where id=f.id) xiaoshou from Fruit f
union
select id, name ,'Q3' jidu, (select q3 from fruit where id=f.id) xiaoshou from Fruit f
union
select id, name ,'Q4' jidu, (select q4 from fruit where id=f.id) xiaoshou from Fruit f
上述pivot列轉行示例中,你已經知道了需要查詢的類型有哪些,用in()的方式包含,假設如果您不知道都有哪些值,您怎麼構建查詢呢?
pivot 操作中的另一個子句 XML 可用於解決此問題。該子句允許您以 XML 格式創建執行了 pivot 操作的輸出,在此輸出中,您可以指定一個特殊的子句 ANY 而非文字值
示例如下:
SQL Code
1
2
3
4
5
6
7
select * from (
select name, nums as "Purchase Frequency"
from demo t
)
pivot xml (
sum(nums) for name in (any)
)

如您所見,列 NAME_XML 是 XMLTYPE,其中根元素是 <PivotSet>。每個值以名稱-值元素對的形式表示。您可以使用任何 XML 分析器中的輸出生成更有用的輸出。
Pivot 為 SQL 語言增添了一個非常重要且實用的功能。您可以使用 pivot 函數針對任何關系表創建一個交叉表報表,而不必編寫包含大量 decode 函數的令人費解的、不直觀的代碼。同樣,您可以使用 unpivot 操作轉換任何交叉表報表,以常規關系表的形式對其進行存儲。Pivot 可以生成常規文本或 XML 格式的輸出。如果是 XML 格式的輸出,您不必指定 pivot 操作需要搜索的值域。