序列:可供多個用戶來產生唯一數值的數據庫對象集合
自動提供唯一數值
共享對象
主要用於主鍵自增
將序列值裝入內存可以提高訪問效率
創建:
CREATE SEQUENCE sequence
increment by n
start with n
maxvalue n | nomaxvalue
minvalue n | no maxvalue
cycle | nocycle
cache | nocache
查詢序列:
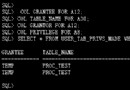
查詢數據字典視圖 USER_SEQUENCES 獲取序列定義信息
SELECT sequence_name, min_value, max_value,
increment_by, last_number
FROM user_sequences;
注意:如果指定NOCACHE 選項,則列LAST_NUMBER 顯示序列中下一個有效的值
獲取序列下一個有效值:sequence_name.nextval 獲取存放序列的當前值:sequence_currval NEXTVAL 應在 CURRVAL 之前指定,否則會報錯。
序列在一下情況會出現裂縫:
1.回滾
2.系統異常
3.多表同時使用一個序列
修改序列:
ALTER SEQUENCE sequence
increment by n
maxvalue n | nomaxvalue
minvalue n | no maxvalue
cycle | nocycle
cache | nocache
注意沒有start with
刪除序列:
DROP sequence sequence_name
概念:
1.一種獨立於表的模式對象,可以存儲在與表不同的磁盤或其他表空間中
2.索引被損壞或刪除,不會對表造成影響,只影響查詢速度
3.索引一旦建立,Oracle會對其進行自動維護,由Oracle來決定何時使用索引,用戶無法指定
4.刪除一個表時,會自動將基於該表的索引刪除
5.通過指針加速Oracle服務器的查詢速度
創建索引:
自動創建:在定義primary key 和unique約束後會自動的在相應的列後創建唯一性索引
手動創建:
CREATE INDEX index
什麼時候創建索引:
列中數據值分布范圍很廣
列經常在 WHERE 子句或連接條件中出現
表經常被訪問而且數據量很大 ,訪問的數據大概占數據總量的2%到4%
什麼時候不要創建索引:
表很小
列不經常作為連接條件或出現在WHERE子句中
查詢的數據大於2%到4%
表經常更新
需要注意的是:創建索引一個是也占一定的資源,二一個使用索引的時候會加快查詢速度,相應的插入速度就慢了,因為還要維護索引
查詢索引:使用數據字典視圖user_indexs,user_ind_columns查看索引信息
SELECT ic.index_name, ic.column_name,
ic.column_position col_pos,ix.uniqueness
FROM user_indexes ix, user_ind_columns ic
WHERE ic.index_name = ix.index_name
刪除索引:
DROP INDEX index_name;
使用同義詞訪問相同的對象
縮短對象名字的長度
創建同義詞:
CREATE SYNONYM synonym_name
FOR object
刪除同義詞:
DROP SYNONYM synonym_name
說明一下,到此為止,基本的Oracle知識已經學完,關於存儲過程和觸發器會在後續的學習中逐漸掌握,接下來會學習jdbc的知識,關於Oracle的總結,會在近期來完成,Oracle的練習也需要多做,主要是子查詢,當然我認為總結也是非常重要的,學習是一方面,但是總結才是提升的時候,當把所有知識都熟記於心的時候,你就學會了這裡知識,否則你只是學過了這些知識,程序這件事,得多練多總結。相信我自己,可以的。自勉。