為了方便學習和測試,所有的例子都是在Oracle自帶用戶Scott下建立的。
create table EMP
(
empno NUMBER(4) not null,
ename VARCHAR2(10),
job VARCHAR2(9),
mgr NUMBER(4),
hiredate DATE,
sal NUMBER(7,2),
comm NUMBER(7,2),
deptno NUMBER(2)
)
alter table EMP
add constraint PK_EMP primary key (EMPNO);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7369, 'SMITH', 'CLERK', 7902, to_date('17-12-1980', 'dd-mm-yyyy'), 800, null, 20);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7499, 'ALLEN', 'SALESMAN', 7698, to_date('20-02-1981', 'dd-mm-yyyy'), 1600, 300, 30);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7521, 'WARD', 'SALESMAN', 7698, to_date('22-02-1981', 'dd-mm-yyyy'), 1250, 500, 30);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7566, 'JONES', 'MANAGER', 7839, to_date('02-04-1981', 'dd-mm-yyyy'), 2975, null, 20);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7654, 'MARTIN', 'SALESMAN', 7698, to_date('28-09-1981', 'dd-mm-yyyy'), 1250, 1400, 30);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7698, 'BLAKE', 'MANAGER', 7839, to_date('01-05-1981', 'dd-mm-yyyy'), 2850, null, 30);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7782, 'CLARK', 'MANAGER', 7839, to_date('09-06-1981', 'dd-mm-yyyy'), 2450, null, 10);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7788, 'SCOTT', 'ANALYST', 7566, to_date('19-04-1987', 'dd-mm-yyyy'), 3000, null, 20);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7839, 'KING', 'PRESIDENT', null, to_date('17-11-1981', 'dd-mm-yyyy'), 5000, null, 10);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7844, 'TURNER', 'SALESMAN', 7698, to_date('08-09-1981', 'dd-mm-yyyy'), 1500, 0, 30);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7876, 'ADAMS', 'CLERK', 7788, to_date('23-05-1987', 'dd-mm-yyyy'), 1100, null, 20);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7900, 'JAMES', 'CLERK', 7698, to_date('03-12-1981', 'dd-mm-yyyy'), 950, null, 30);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7902, 'FORD', 'ANALYST', 7566, to_date('03-12-1981', 'dd-mm-yyyy'), 3000, null, 20);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7934, 'MILLER', 'CLERK', 7782, to_date('23-01-1982', 'dd-mm-yyyy'), 1300, null, 10);
注:標題中的紅色order by是說明在使用該方法的時候必須要帶上order by
一、rank()/dense_rank() over(partition by ...order by ...)
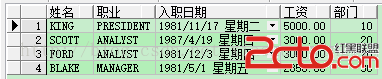
現在客戶有這樣一個需求,查詢每個部門工資最高的雇員的信息,相信有一定oracle應用知識的同學都能寫出下面的SQL語句:
select * from (select ename, job, hiredate, e.sal, e.deptno
from emp e,
(select deptno, max(sal) sal from emp group by deptno) t
where e.deptno = t.deptno
and e.sal = t.sal)
order by deptno;
select * from (select ename 姓名, job 職業, hiredate 入職日期, e.sal 工資, e.deptno 部門
from emp e,
(select deptno, max(sal) sal from emp group by deptno) t
where e.deptno = t.deptno
and e.sal = t.sal)
order by 部門;
在滿足客戶需求的同時,大家應該習慣性的思考一下是否還有別的方法。這個是肯定的,就是使用本小節標題中rank() over(partition by...)或dense_rank() over(partition by...)語法,SQL分別如下:
select empno, ename, job, hiredate, sal, deptno from (select empno, ename, job, hiredate, sal, deptno, rank() over(partition by deptno order by sal desc) r from emp) where r = 1; select empno, ename, job, hiredate, sal, deptno from (select empno, ename, job, hiredate, sal, deptno, dense_rank() over(partition by deptno order by sal desc) r from emp) where r = 1為什麼會得出跟上面的語句一樣的結果呢?這裡補充講解一下rank()/dense_rank() over(partition by e.deptno order by e.sal desc)語法。
那麼rank()和dense_rank()有什麼區別呢?
rank(): 跳躍排序,如果有兩個第一級時,接下來就是第三級。
dense_rank(): 連續排序,如果有兩個第一級時,接下來仍然是第二級。
小作業:查詢部門最低工資的雇員信息。
二、min()/max() over(partition by ...)
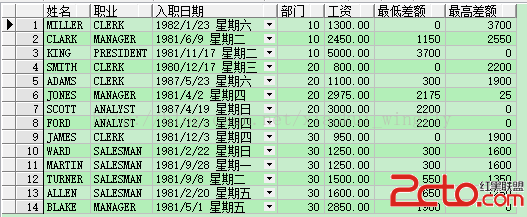
現在我們已經查詢得到了部門最高/最低工資,客戶需求又來了,查詢雇員信息的同時算出雇員工資與部門最高/最低工資的差額。這個還是比較簡單,在第一節的groupby語句的基礎上進行修改如下:
-- 查詢每位雇員信息的同時算出雇員工資與所屬部門最高/最低員工工資的差額
select ename 姓名, job 職業, hiredate 入職日期, e.deptno 部門, e.sal 工資, e.sal-me.min_sal 最低差額, me.max_sal-e.sal 最高差額 from emp e, (select deptno, min(sal) min_sal, max(sal) max_sal from emp group by deptno) me where e.deptno = me.deptno order by e.deptno, e.sal;
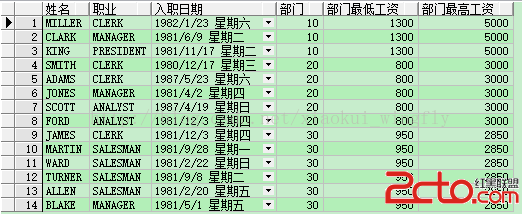
select ename 姓名, job 職業, hiredate 入職日期, deptno 部門, min(sal) over(partition by deptno) 部門最低工資, max(sal) over(partition by deptno) 部門最高工資 from emp order by deptno, sal; select ename 姓名, job 職業, hiredate 入職日期, deptno 部門, nvl(sal - min(sal) over(partition by deptno), 0) 部門最低工資差額, nvl(max(sal) over(partition by deptno) - sal, 0) 部門最高工資差額 from emp order by deptno, sal;
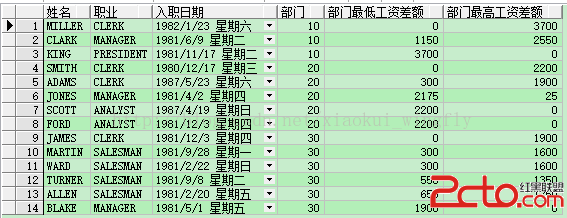
小作業:如果在本例中加上order by,會得到什麼結果呢?
三、lead()/lag() over(partition by ... order by ...)
中國人愛攀比,好面子,聞名世界。客戶更是好這一口,在和最高/最低工資比較完之後還覺得不過瘾,這次就提出了一個比較變態的需求,計算個人工資與比自己高一位/低一位工資的差額。這個需求確實讓我很是為難,在groupby語句中不知道應該怎麼去實現。不過。。。。現在我們有了over(partition by ...),一切看起來是那麼的簡單。如下:
-- 計算個人工資與比自己高一位/低一位工資的差額
select ename 姓名, job 職業, sal 工資, deptno 部門, lead(sal, 1, 0) over(partition by deptno order by sal) 比自己工資高的部門前一個, lag(sal, 1, 0) over(partition by deptno order by sal) 比自己工資低的部門後一個, nvl(lead(sal) over(partition by deptno order by sal) - sal, 0) 比自己工資高的部門前一個差額, nvl(sal - lag(sal) over(partition by deptno order by sal), 0) 比自己工資高的部門後一個差額 from emp;
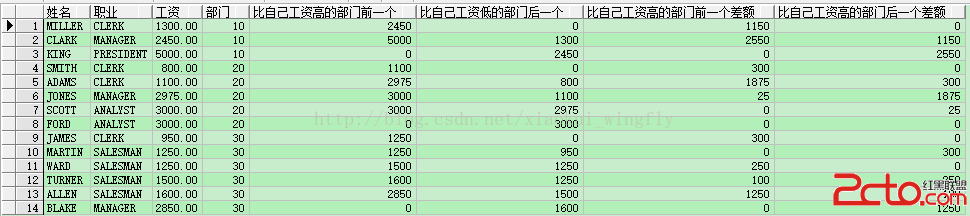
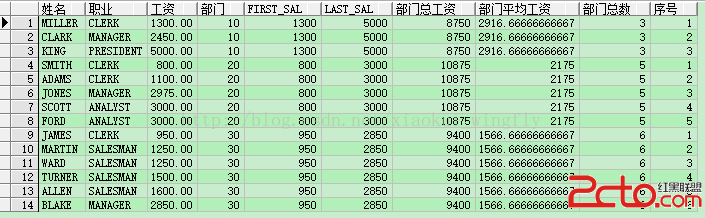
下面再列舉一些常用的方法在該語法中的應用(注:帶order by子句的方法說明在使用該方法的時候必須要帶order by):
select ename 姓名, job 職業, sal 工資, deptno 部門,
first_value(sal) over(partition by deptno) first_sal,
last_value(sal) over(partition by deptno) last_sal,
sum(sal) over(partition by deptno) 部門總工資,
avg(sal) over(partition by deptno) 部門平均工資,
count(1) over(partition by deptno) 部門總數,
row_number() over(partition by deptno order by sal) 序號
from emp;
重要提示:大家在讀完本片文章之後可能會有點誤解,就是OVER (PARTITION BY ..)比GROUP BY更好,實際並非如此,前者不可能替代後者,而且在執行效率上前者也沒有後者高,只是前者提供了更多的功能而已,所以希望大家在使用中要根據需求情況進行選擇。