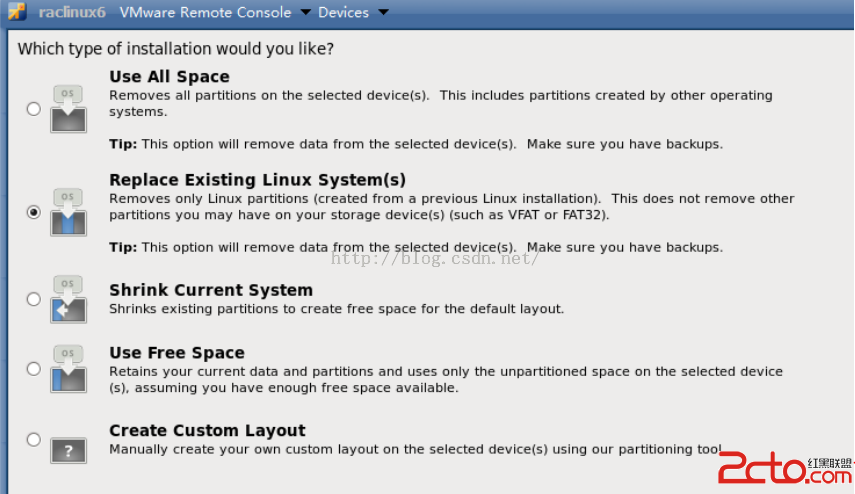
在關系數據庫中,索引是一種與表有關的數據庫結構,它是除表以外的另一個重要模式對象。索引是建立在表的一列或多個列上的輔助對象,目的是提高表中數據的訪問速度。
索引時表示數據的另一種方式,它提供的數據順序不同於數據在磁盤上的物理存儲順序。它重新排列數據的物理位置,使其值為有序鍵值列表,每個鍵值是指向表行的指針,故其排列方式使其搜索變得更加有效。
Oracle中常用的索引類型有:B樹索引、反向鍵索引、位圖索引、基於函數的索引、簇索引、全局索引和局部索引。
創建索引的語法如下:
CREATE UNIQUE|BTIMAP INDEX <schema>.<index_name>
ON <schema>.<table_name>
(<column_name>|<expression> ASC|DESC,
<column_name>|<expression> ASC|DESC,...
)
TABLESPACE <tablespace_name>
STORAGE <storage_settings>
LOGGING|NOLOGGING
COMPUTE STATISTICS
NOCOMPRESS|COMPRESS <nn>
NOSORT|REVERSE
PATITION|GLOBAL PATITION <patition_setting>;B樹索引是Oracle中默認並且最常用的索引,B樹索引的組織結構類似一棵樹,其中主要數據集中在葉子結點上,每個葉子結點中包括:索引列的值和記錄行對應的物理地址ROWID。
創建一個B數索引,需要使用CREATE INDEX語句,如果用戶要在自己的模式中創建索引,則必須具有CREATE INDEX的系統權限:如果用戶想要在其他用戶模式中創建索引,則必須具有CREATE ANY INDEX的系統權限。
創建索引時,在ON關鍵字後面指定索引引用的表名和列名,使用TABLESPACE指定存儲索引的表空間。
默認情況下,當用戶為表定義一個主鍵時 系統將自動為該列創建一個B樹索引,另外,當一個列已經包含索引時,則無法再在該列上創建索引。
例1:
CREATE UNIQUE INDEX sname_index ON siege.student sname)TABLESPACE learning;索引可以是唯一的,也可以是不唯一的,唯一的B樹索引可以保證索引列上不會有重復的值。創建唯一索引需要使用關鍵字UNIQUE。
例2:
DROP INDEX sname_index;
CREATE UNIQUE INDEX sname_index ON siege.student (sname)TABLESPACE learning;注:每列只能創建一個索引,索引先刪除之前的索引再來創建唯一索引。
復合索引,是指基於表中多個字段的索引。
例3:
DROP INDEX sname_index ;
CREATE INDEX sname_index ON siege.student (sname,sage)TABLESPACE learning;位圖索引不同於B樹索引,它不存儲ROWID值,也不存儲鍵值,主要用於在比較特殊的列上創建索引。
當列的技術很低時(指在索引列中,所有列值的數量比表中行的數量少,例如’性別‘列只有2個值)。Oracle建議,當一個列的所有取值數量與行的總數比小於1%時,對該列就不再適合建立B樹索引,而適用位圖索引。
位圖索引適用於在表中基數比較小的列上創建,在表上放置單獨的位圖索引沒有意義,只有對多個列建立位圖索引,系統才可以有效地利用它們來提高查詢的速度。
位圖所以不是能使唯一索引,也不能進行鍵壓縮,位圖索引的作用來源於與其他位圖索引的結合,當在多個列上進行查詢,Oracle對這些列上的位圖進行布爾AND和OR運算,最終找到需要的結果。
先修改student表結構,增加ssex字段,並賦值:
ALTER TABLE student ADD (ssex Varchar2(1));
UPDATE student SET ssex='M'然後對ssex列創建位圖索引:
例4:
CREATE BITMAP INDEX ssex_bitmap_index on siege.student(ssex) TABLESPACE learning;注:由於本機器安裝的是XE版的Oracle,在執行下列語句時Bit-mapped indexes=FALSE,說明未安裝此功能,故上面的語句執行會報00439錯誤,不過正常情況下應是正確的。
select * from v$option Where PARAMETER='Bit-mapped indexes'反向鍵索引時一種特殊的B樹索引,適用於在含有序列數的列上創建索引,在常規的B樹索引中,如果主鍵是遞增的,那麼在向表中添加新的數據時,B數索引將直接訪問最後一個數據,而不是一個結點一個結點的訪問,這種情況造成的結果是:隨著數據行的增加,以及原有數據行的刪除,B樹索引將變得越來越不均勻。
此時,可以創建反向鍵索引,其原理是:如果用戶使用序列編號在表中添加新的記錄,則反向鍵索引首先反向轉化每個列鍵值的字節,然後在反向後的新數據上進行索引。
例如,如果用戶輸入索引鍵2009,則反向鍵索引將其反向轉化為9002, 這樣可以將索引鍵變成非遞增的,從而使得數據在值的范圍分布上比原來更均勻。
反向鍵索引適用於在表中嚴格排序的列上創建,在查詢時,用戶只需要像常規方式一樣查詢數據,而不需要關心鍵的反向處理,系統會自動完成該處理。
例5:
CREATE INDEX sid_reserve_index on siege.student(sid) REVERSE TABLESPACE learning;