DB筆記(Oracle)
一.Oracle的安裝,服務的啟動,數據庫的建立,用戶的建立(略過)。
二.Select語句:
(一)、單行函數:
1. 表達式和null計算,結果為null,即,不作顯示(也就是數據失蹤了!)。所以一般用函數NVL(列名,替換值),如NVL(sal,0)。
2. 字符串拼接:|| 例如:select ID||’---’||uname from emp;
3. 排序 和過濾(order by 和 where):
a) select* from emp order by sal asc,comm desc; 此表達式為按薪水升序排,薪水相同的按獎金倒序排。
b) select* from emp order by ( sal + NVL(comm,0) ) desc;此表達式是:按照薪水和獎金之和來排序,注意:如果不用NVL直接用comm,則會丟失一些值。
c) select* from emp where uname > ‘CBA’; 字符串的過濾, 這個具體還沒搞懂。
d) select* from emp where sal between 100 and 200;
4. 條件選擇:and,or,in(a1,a2,a3)。注意:其中in(a1,a2,a3)表示選擇a1,a2,a3三個中的一個,而不是選擇三個范圍中的一個。
5. Not關鍵字:not in(a,b,c); is not null; 等等。
6. Like關鍵字:通配符有兩個,如下
a) %: 任意字符 出現 任意次數。
b) _: 任意字符 出現 一次。
注意:查詢通配符需要轉義,如下:select * from emp where ename like‘%\%%’ escape ‘\’; select * from emp where ename like ‘_H@_%’ escape ‘@’;
7. 事件處理函數: upper(), Lower(), substr(ename,1,4), length(), trim(), ltrim(), rtrim()。
8. 時間格式函數:to_char(sysdate,’yyyy-mm-dd’); to_date(string,’yyyy-mm-dd’)。
兩個日期間的天數 select floor( sysdate – to_date(‘2014/12/27’ , ‘yyyy/mm/dd’) );
9. rownum: 行號,表的原本數據排序,只能用於<或<=運算符,不能用>或>=運算符,如果要取後幾行數據,需要一個where子查詢先倒敘排列。
10. 正則表達式:sql語句支持正則表達式,例子如下:
select* from emp where regexp_like(列名,’正則表達式’);
(二)、組函數:
1. avg() ,min(), max(), sum() 略過不講。
2.count():計數函數。返回查詢結果的行數,經常配合distinct,去除重復行。
例如: select count(eno) from emp whereeno>200; 或者 select count(distinct eno) from emp;
3. group by : 分組函數。
a). 查詢單位不再以行為單位,所有操作均以組為單位.
b). 何為一組?值相同則為一組.
c). having為過濾分組,
c). group by子句 須在where子句之後,order by子句之前。
d). select eno from emp group byeno; ----eno相同的分為一組,查詢每組的eno
select depno,sal(sal) from dept group by depno; ----以部門號分組,查詢。
select max( avg(sal) ) from dept group by deptno; ----先按部門編號分組,查出每組平均值的最大值。
select * from dept group by sal,comm; ----工資和獎金相同的分為一組,查詢*。
三.Insert,update,delete語句(略過)。
四.其他操作:
1. 索引index:可以給某個列增加index,提高其select的效率。創建方法超級簡單:create index index_name on tablename(cols); 然後不用管,我們索引時oracle會自動調用index來檢索。刪除方法也超簡單:drop index index_name; 注意: index缺點也不少,Index不適合:數據唯一性不好的列+增刪改頻繁的列。所以不到必要,不用建立。
2. 視圖view:使用方法和表的一模一樣,好處:sql重用+安全
create view v$_vname as (select子句); drop view V$_vname;
3. 序列sequence:用法:創建,刪除,引用。略過。
五.DB設計范式: (重要)
1. DB范式目前有六種,1NF,2NF,3NF,BCNF,4NF,5NF(完美范式)。依次越優化。
2. 企業級開發,最低滿足3NF。
3. 滿足范式越高,DB冗余越低,DB越優化。
4. 詳解:
a) 1NF:表的每個列都是原子的。
錯誤示范 -->
b) 2NF:實體屬性完全依賴主關鍵字。即不能只依賴主鍵的一部分。
錯誤示范 à (略過)
常見錯誤 à 聯合主鍵的表。 某些屬性依賴主鍵的一部分。
解決方案 à 拆分主鍵拆分表,外鍵關聯。
c) 3NF:
錯誤示范 -->
常見錯誤 à 表中屬性A依賴於B,B依賴於C。數據量大時會大量冗余。
解決方案 à 拆表,外鍵關聯。
d) BCNF:允許出現有主鍵的一部分被主鍵另一部分或者其他部分決定。即聯合主鍵相互依賴。
錯誤示范 à倉庫表storehouse(倉庫ID,管理員ID,物品ID,數量),一個倉庫一個管理員,一個倉庫多個物品,則依賴關系如下:
出現了倉庫ID和管理員ID相互依賴,符合3NF但不符合BCNF。
解決方案 -->拆分。
編程兩個一對多,這種結構也叫:實體表—映射表關聯結構。
e) 注意:映射表中兩個外鍵需形成聯合主鍵。
備注:
1. 別名可以用中文,但要加雙引號;
2. oracle的某些客戶端,如PLsql等,有sql window和command window窗口,用來跑不同的語句,例如desc User; 指令只能在command window中跑;
3. SQL語句優化:Select * from emp; *是通配符,性能較低,程序中盡量不要出現*,最好能具體到列名。
4. SQL不區分大小寫,但是script執行的時候會統一轉化為大寫。 所以:大寫執行效率高但不利於閱讀,小寫腳本執行效率高但不利於閱讀,所以一般關鍵字大寫,另外需要注意:建議程序裡關鍵字也大寫,有利於增加效率。
5. SQL語句的優化: 檢索結果少and 檢索結果多, 檢索結果多 and 檢索結果少。因為sql語句是順序執行。
6. SQL語句優化:select * from emp where eno=100 or eno=200 oreno=300; 此語句和select * from emp where eno in (100,200,300); 等價,但是用in的語法清晰+效率高,因為in函數內部做了優化。
7.SQL語句優化:用like關鍵字和通配符來檢索數據萬不得已再用,它的操作慢的不得了。
8. 組函數的嵌套最多兩層,例如 max( avg(sal) )等,不能出現max( min( avg(sal) ) ).
9. Oracle內部執行順序:where行級過濾 à group by分組 à having組級過濾 à order by排序。所以:group by子句 須在where子句之後,order by子句之前,即where…group by…order by…
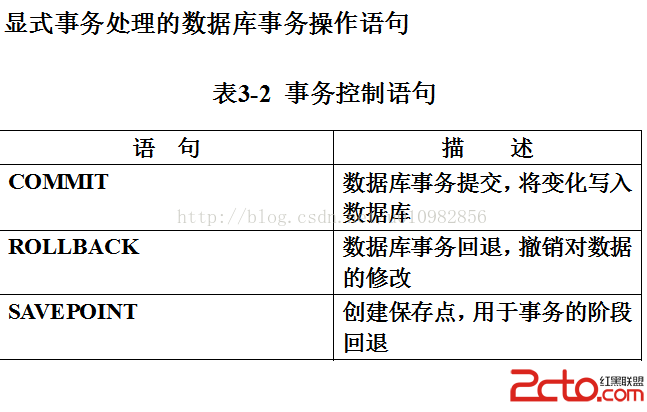
10. Transaction事務機制要點:只操作insert,update,delete行級語句。如果系統正常關閉,則事務自動commit;如果執行create,drop等表級操作,事務自動commit;如果非正常關閉如斷電等,事務自動rollback。