數據庫版本:Oracle 10g
字符集:SIMPLIFIED CHINESE_CHINA.US7ASCII
JDK:1.6.0_45
Oracle驅動:ojdbc14.jar
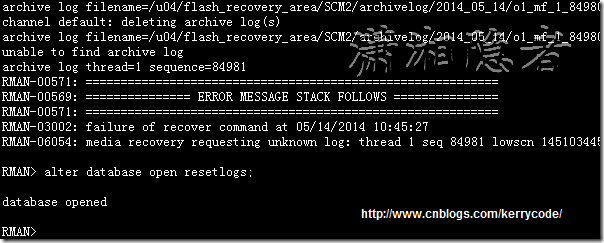
使用JDBC操作數據庫,獲取連接、執行SQL沒有問題。但是,查詢出來的結果中,所有漢字,均顯示為亂碼。
debug查看到在數據從數據庫中獲取出來的時候,就已經是亂碼,而使用PL/SQL等工具,均顯示正常。
不知是否Oracle的驅動,在進行漢字處理的時候,使用了系統默認的字符集?此時,本著死馬當活馬醫的理念,使用下對漢字的強制轉碼,ASCII碼是標准的ISO-8859-1的子集,也許使用這個ISO-8859-1可以獲取到正常的漢字?於是,首先測試使用new String(fieldValue.getBytes("ISO-8859-1"));輸出依然亂碼!想想應該是將這東西進行轉碼,而不僅僅是按照這個格式獲取,於是調整為:new String(fieldValue.getBytes("ISO-8859-1"), "GBK"),測試下,搞定!只是,所有用到漢字的地方,均需要這麼搞一下,有點麻煩。
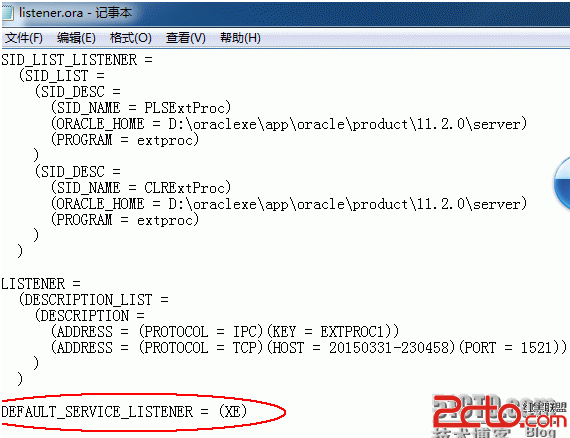
據說,可以使用另外一種方式:改Oracle的字符集!
1、需要修改注冊表:HKEY_LOCAL_MACHINE\SOFTWARE\ORACLE\HOME0\NLS_LANG 的值為SIMPLIFIED CHINESE_CHINA.ZHS16GBK
2、修改一個系統變量NLS_LANG.
以上兩種,第二種方式試過,可以。第一種,未在現有環境下做過測試。
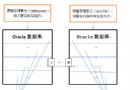
另外,將獲取到的漢字,寫入另外一個oracle 11g的數據庫中,發現:漢字不是按照一個漢字兩個字節來存放的;而是一個漢字3個字節!
查了一下,發現:字符集是AL32UTF8,這個字符集一般都默認中文是3個字節。於是,需要將目標數據庫表的字段長度進行擴充。實際對於漢字的問題,oralce以及較新的sqlserver,都支持nvarchar的格式,對於使用nvarchar的字段,無論漢字還是數字、字符、英文字母,均每個字符占用1位。
如果不確定當前一個漢字占用幾個字符,可以使用select length('汗') from dual;進行查看。
對於US7ASCII的字符集,目前來看,新上的系統使用的較少了,而對於一些較老的遺留系統,可能會存在這種情況。具體還需注意!