rac_/home/oracle權限過大引發的節點信任關系錯
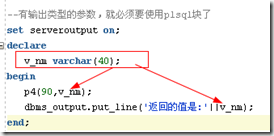
Oracle SQL*plus常用的命令和函數,oracle
【Oracle】RAC刪除節點 環境: OS:OEL5.
Oracle數據庫升級或數據遷移方法研究,oracle數據庫
oracle數據庫常用命令 conn 連接新用戶,常用來
某些時候,需要關聯不同的數據庫進行數據查詢、操作等。