【oracle11g,19】索引管理
一.索引的分類:
1.邏輯上分為:
單列索引和復合索引
唯一索引和非唯一索引
函數索引
domain索引
2.物理上分:
分區索引和非分區索引
b-tree
bitmap
注意:表和索引最好不放在同一表空間。
二.domain索引:(了解)
一般的索引 %MI%'是不走的索引的,但有可能走域索引。
域索引用於文本的檢索,適合數據倉庫。
SQL> select * from scott.emp where ename like '%MI%';
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
---------- ---------- --------- ---------- --------- ---------- ---------- ----------
7369 SMITH CLERK 7902 17-DEC-80 800 20
7934 MILLER CLERK 7782 23-JAN-82 1300 10
SQL> select * from scott.emp where ename like 'MI%';
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
---------- ---------- --------- ---------- --------- ---------- ---------- ----------
7934 MILLER CLERK 7782 23-JAN-82 1300 10
三.b-tree和bitmap 索引:
1.b-tree索引是默認的索引。

#創建索引表空間 (unifZ喎?http://www.Bkjia.com/kf/ware/vc/" target="_blank" class="keylink">vcm0gc2l6ZTq/ydLUvPXJ2cvpxqwpCgoKU1FMJmd0OyBjcmVhdGUgdGFibGVzcGFjZSBpbmR4IGRhdGFmaWxlIA=="/u01/app/oracle/oradata/PROD/disk4/indx01.dbf' size 50m autoextend on next 10m maxsize 500m uniform size 1m;
Tablespace created.
詳解:http://www.tuicool.com/articles/q6vqEf
2.位圖索引


四.b-tree 和 bitmap的區別:
1.b-tree索引使用場景:
基數比較大(在一個大表上)
建立在重復值比較少的列上 ,在做select查詢時,返回記錄的行數小於全部記錄的4%,
因為索引是有序的,所以可以在排序字段上建立索引。
update 較多。
oltp使用
2.bitmap 索引使用場景: (在生產環境中不使用)
基數比較小
建立在重復值非常高的列上
在做DML時代價高,所以在update較少的列上建立bitmap索引。
一般使用在altp。
bitmap缺點:當對一個有位圖索引的數據表進行dml(包括insert)操作的時候,oracle會由於bitmap index 鎖定過多的數據行。
3.案例: 性別列上建立索引
SQL> create table lxtb(id number(8),gender varchar2(2),name varchar2(30));
SQL> declare
2 v_num number(2);
3 begin
4 for i in 1..20000 loop
5 v_num:=round(dbms_random.value(0,1),0);
6 if v_num>0 then
7 insert into lxtb values(i,"M','male'||i);
8 else
9 insert into lxtb values(i,'F','female'||i);
10 end if;
11 if mod(i,1000)=0 then
12 commit;
13 end if;
14 end loop;
15 commit;
16 end;
17 /
PL/SQL procedure successfully completed.
SQL> select count(*) from lxtb;
COUNT(*)
----------
20000
SQL> select * from lxtb where rownum<=10;
ID GE NAME
---------- -- --------------------------------------------------
1 M male1
2 M male2
3 M male3
4 M male4
5 M male5
6 F female6
7 M male7
8 M male8
9 F female9
10 M male10
10 rows selected.
SQL> col index_name for a20
SQL> col index_type for a10
SQL> select index_name,index_type,table_name,tablespace_name
2 from dba_indexes where table_name='LXTB';
no rows selected
SQL> col column_name for a10
SQL> select index_name,table_name,column_name from dba_ind_columns where table_name='LXTB';
no rows selected
#創建b-tree索引 (默認索引)
SQL> create index i_gender on lxtb(gender) tablespace indx;
Index created.
#BLEVEL=1 表示b-tree為兩層,LEAF_BLOCKS 表示頁塊數。
SQL> select index_name,index_type,table_name,tablespace_name,blevel,leaf_blocks
2 from dba_indexes where table_name='LXTB';
INDEX_NAME INDEX_TYPE TABLE_NAME TABLESPACE BLEVEL LEAF_BLOCKS
-------------------- ---------- ---------- ---------- ---------- -----------
I_GENDER NORMAL LXTB INDX 1 37
SQL> drop index i_gender;
Index dropped.
#創建位圖索引:
SQL> create bitmap index i_gender on lxtb(gender) tablespace indx;
Index created.
SQL> col index_name for a20
SQL> col index_type for a10
SQL> select index_name,index_type,table_name,tablespace_name,blevel,leaf_blocks
2 from dba_indexes where table_name='LXTB';
INDEX_NAME INDEX_TYPE TABLE_NAME TABLESPACE BLEVEL LEAF_BLOCKS
-------------------- ---------- ---------- ---------- ---------- -----------
I_GENDER BITMAP LXTB INDX 0 1
五.索引的管理操作:
1.分析索引的命令:收集統計信息
SQL> analyze index i_gender validate structure;
Index analyzed.
SQL> exec DBMS_STATS.GATHER_INDEX_STATS('SYS','I_GENDER');
PL/SQL procedure successfully completed.
2.對索引碎片的整理: 一般碎片整理不徹底,要重建索引。
SQL> alter index i_gender coalesce;
Index altered.
3.將索引遷移到其他表空間:
SQL> select index_name,index_type,table_name,tablespace_name,blevel,leaf_blocks
2 from dba_indexes where table_name='LXTB';
INDEX_NAME INDEX_TYPE TABLE_NAME TABLESPACE BLEVEL LEAF_BLOCKS
-------------------- ---------- ---------- ---------- ---------- -----------
I_GENDER NORMAL LXTB INDX 1 37
#遷移到其他表空間
SQL> alter index i_gender rebuild tablespace users nologging online;
Index altered.
SQL> col index_type for a10
SQL> select index_name,index_type,table_name,tablespace_name,blevel,leaf_blocks
2 from dba_indexes where table_name='LXTB';
INDEX_NAME INDEX_TYPE TABLE_NAME TABLESPACE BLEVEL LEAF_BLOCKS
-------------------- ---------- ---------- ---------- ---------- -----------
I_GENDER NORMAL LXTB USERS 1 37
4.監控索引: 查看查詢是否走索引,
SQL> select * from v$object_usage where index_name='I_GENDER';
no rows selected
#打開監控
SQL> alter index i_gender monitoring usage;
Index altered.
MON:yes表示監控,no:表示未監控
#use= NO表示查詢沒有走索引,use=yes表示查詢走索引。
SQL> select * from v$object_usage where index_name='I_GENDER';
INDEX_NAME TABLE_NAME MON USE START_MONITORING END_MONITORING
-------------------- ---------- --- --- ------------------- -------------------
I_GENDER LXTB YES NO 02/10/2014 18:39:27
#關閉監控
SQL> alter index i_gender nomonitoring usage;
Index altered.
SQL> select * from v$object_usage where index_name='I_GENDER';
INDEX_NAME TABLE_NAME MON USE START_MONITORING END_MONITORING
-------------------- ---------- --- --- ------------------- -------------------
I_GENDER LXTB NO YES 02/10/2014 18:39:27 02/10/2014 18:41:43
六.創建和重建索引:(重點)
1.注意:在生成庫上重建或創建索引,對索引的一切操作,一定要使用nologging online,
nologging :少計日志,提高效率。
online:不阻塞dml操作
#創建索引
SQL> create index i_gender on lxtb(gender) tablespace indx nologging online;
Index created.
#重建索引
alter index xxx rebuild online;
2.rebuild 和 rebuild online 區別:

七.函數索引:
(略) 詳見:【sql,11】視圖、序列、索引、同義詞、權限和角色的管理
八.反向索引:

在生成庫上不建議使用。
#創建反向索引:
SQL> create index i_id on lxtb(id) reverse tablespace indx;
Index created.
SQL> col index_name for a20
SQL> col index_type for a10
SQL> select index_name,index_type,table_name,tablespace_name,blevel,leaf_blocks
2 from dba_indexes where table_name="LXTB';
INDEX_NAME INDEX_TYPE TABLE_NAME TABLESPACE BLEVEL LEAF_BLOCKS
-------------------- ---------- ---------- ---------- ---------- -----------
I_NAME NORMAL LXTB INDX 1 60
I_GENDER NORMAL LXTB USERS 1 37
I_UPPER FUNCTION-B LXTB INDX 1 60
ASED NORMA
L
I_ID NORMAL/REV LXTB INDX 1 44
八.HASH索引:(一般不使用)
使用hash算法分散值。與反向索引相似,范圍查詢效率極低。
#創建hash索引
SQL> create index i_id on lxtb hash(id) tablespace indx;
Index created.
九.復合索引:
詳見:【sql,11】視圖、序列、索引、同義詞、權限和角色的管理
十.查詢索引:
SQL> select index_name,index_type,table_name,tablespace_name,blevel,leaf_blocks,buffer_pool
2 from dba_indexes where table_name='LXTB';
INDEX_NAME INDEX_TYPE TABLE_NAME TABLESPACE BLEVEL LEAF_BLOCKS BUFFER_
-------------------- ---------- ---------- ---------- ---------- ----------- -------
I_NAME NORMAL LXTB INDX 1 60 DEFAULT
I_GENDER NORMAL LXTB USERS 1 37 DEFAULT
I_UPPER FUNCTION-B LXTB INDX 1 60 DEFAULT
ASED NORMA
L
I_ID NORMAL/REV LXTB INDX 1 44 DEFAULT
#切換緩存池
SQL> alter index scott.pk_emp storage(buffer_pool keep);
Index altered.
SQL> col index_name for a20
SQL> col index_type for a10
SQL> select index_name,index_type,table_name,tablespace_name,blevel,leaf_blocks,buffer_pool
2 from dba_indexes where table_name='LXTB';
INDEX_NAME INDEX_TYPE TABLE_NAME TABLESPACE BLEVEL LEAF_BLOCKS BUFFER_
-------------------- ---------- ---------- ---------- ---------- ----------- -------
I_NAME NORMAL LXTB INDX 1 60 DEFAULT
I_GENDER NORMAL LXTB USERS 1 37 DEFAULT
I_UPPER FUNCTION-B LXTB INDX 1 60 DEFAULT
ASED NORMA
L
I_ID NORMAL/REV LXTB INDX 1 44 DEFAULT
SQL> select object_id,object_name,object_type from dba_objects where owner='SCOTT';
OBJECT_ID OBJECT_NAME OBJECT_TYPE
---------- -------------------- --------------------
10184 DEPT TABLE
10185 PK_DEPT INDEX
10186 EMP TABLE
10187 PK_EMP INDEX
10188 BONUS TABLE
10189 SALGRADE TABLE
6 rows selected.
SQL> select segment_name,segment_type,tablespace_name,bytes/1024 k,extents,blocks
2 from dba_segments where owner='SCOTT';
SEGMENT_NA SEGMENT_TY TABLESPACE K EXTENTS BLOCKS
---------- ---------- ---------- ---------- ---------- ----------
DEPT TABLE USERS 64 1 8
PK_DEPT INDEX USERS 64 1 8
EMP TABLE USERS 64 1 8
PK_EMP INDEX USERS 64 1 8
BONUS TABLE USERS 64 1 8
SALGRADE TABLE USERS 64 1 8
SQL> select constraint_name,table_name,column_name
2 from dba_cons_columns where owner='SCOTT';
CONSTRAINT TABLE_NAME COLUMN_NAM
---------- ---------- ----------
PK_DEPT DEPT DEPTNO
PK_EMP EMP EMPNO
FK_DEPTNO EMP DEPTNO
以下內容參考:http://blog.csdn.net/rlhua/article/details/13776423
十一.設置index 為invisible.
An invisible index is an index that is ignored by the optimizer unless you explicitly set the OPTIMIZER_USE_INVISIBLE_INDEXES initialization parameter to TRUE at the session or system level.
To create an invisible index:
Use the CREATE INDEX statement with the INVISIBLE keyword.
The following statement creates an invisible index named emp_ename for the ename column of the emp table:
CREATE INDEX emp_ename ON emp(ename)
TABLESPACE users
STORAGE (INITIAL 20K
NEXT 20k) INVISIBLE;
隱藏索引
scott@TESTDB> create index emp_ename_i on emp(ename) invisible;
Index created.
scott@TESTDB> select index_name,VISIBILITY from user_indexes;
INDEX_NAME VISIBILIT
-------------------- ---------
PK_EMP VISIBLE
EMP_SAL_F VISIBLE
EMP_COMM_I VISIBLE
EMP_ENAME_I
INVISIBLE
PK_DEPT VISIBLE
scott@TESTDB> select * from emp where ename='KING';
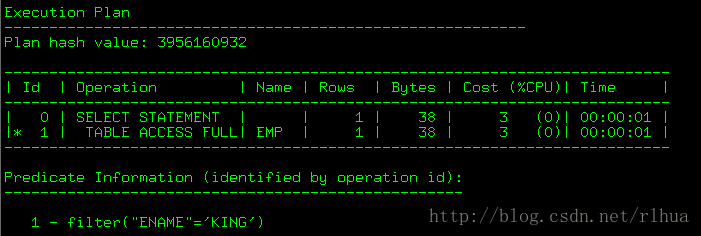
沒有走索引
切換到系統用戶,修改參數
sys@TESTDB> alter session set
optimizer_use_invisible_indexes=true;
Session altered.
sys@TESTDB> select * from scott.emp where ename='KING';
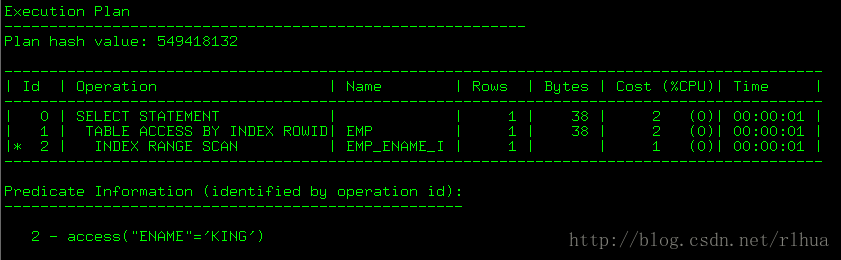
隱藏索引變正常索引或反之
sys@TESTDB> alter index scott.emp_ename_i visible;
Index altered.
scott@TESTDB> select index_name,VISIBILITY from user_indexes;
INDEX_NAME VISIBILIT
------------------------------ ---------
PK_EMP VISIBLE
EMP_SAL_F VISIBLE
EMP_COMM_I VISIBLE
EMP_ENAME_I VISIBLE
PK_DEPT VISIBLE
多個索引,把慢的索引隱藏點,讓他走快的索引
scott@TESTDB> alter index emp_ename_i visible;
Index altered.
scott@TESTDB> alter index emp_ename_i invisible;
Index altered.