先用scott用戶下的emp表做實驗.
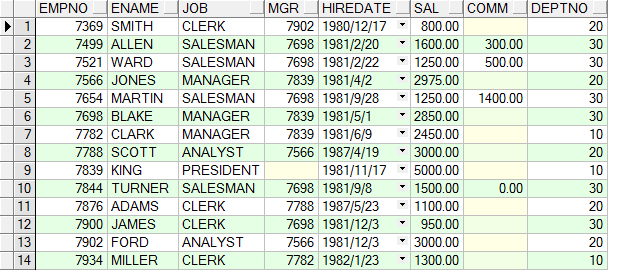
emp表有個字段,一個是empno(員工編號),另一個是mgr(上級經理編號)
下面是表中所有數據
select *
from emp
start with empno=7698
connect by mgr=prior empno;
執行結果如下:
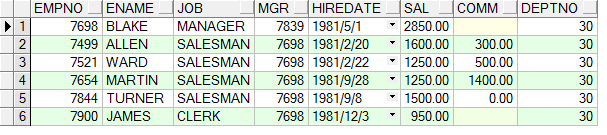
得到的結果是empno=7698的數據,以及會得到mgr=7698的數據。
它是向下遞歸的, 即我們從empno=7698開始遍歷,去找出mgr=7698的所有數據S(用S代表查出的所有數據.), 然後在從S中的empno的值去匹配查找是否還有滿足,mgr in (s.empno)的數據。一直遍歷進去到沒有數據為止。
下面的這個可以詳細的表述效果。<喎?http://www.Bkjia.com/kf/ware/vc/" target="_blank" class="keylink">vcD4KCgo8dGFibGUgYm9yZGVyPQ=="0" cellspacing="0" cellpadding="0">
1
2
--向下遞歸遍歷
select *
from emp
connect by mgr=
prior empno
start with empno=7839;
執行結果如下:
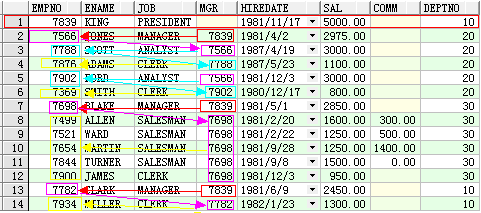
1
2
--向上遞歸遍歷
select
* from emp connect by prior mgr=empno start with empno=7844;
執行結果如下:

這樣直到沒有匹配的數據為止。
以上只是簡單的舉了個例子。
connect by是結構化查詢中用到的,其基本語法是:
1
2
3
4
select ...
from tablename
start
by cond1
connect by cond2
where cond3
簡單說來是將一個樹狀結構存儲在一張表裡,比如一個表中存在兩個字段(如emp表中的empno和mgr字段):empno, mgr那麼通過表示每一條記錄的mgr是誰,就可以形成一個樹狀結構。
用上述語法的查詢可以取得這棵樹的所有記錄。
其中:
cond1是根結點的限定語句,當然可以放寬限定條件,以取得多個根結點,實際就是多棵樹。
cond2是連接條件,其中用prior表示上一條記錄,比如connect by prior id=praentid就是說上一條記錄的id是本條記錄的praentid,即本記錄的父親是上一條記錄。
cond3是過濾條件,用於對返回的所有記錄進行過濾。
prior和start with關鍵字是可選項
prior運算符必須放置在連接關系的兩列中某一個的前面。對於節點間的父子關系,prior運算符在一側表示父節點,在另一側表示子節點,從而確定查找樹結構是的順序是自頂向下還是自底向上。在連接關系中,除了可以使用列名外,還允許使用列表達式。
start with子句為可選項,用來標識哪個節點作為查找樹型結構的根節點。若該子句被省略,則表示所有滿足查詢條件的行作為根節點。