SQL語句執行時,Oracle的優化器會根據統計信息確定表的訪問方式,一般來說,有兩種基本的數據訪問方式:1)全掃描。在全掃描(全表掃描或者快速全索引掃描)中,多個塊被讀入到一個IO運算中。2)索引掃描。索引掃描首先掃描索引葉子塊以取得特定的行id(rowid),然後利用這些行id來訪問父表取得實際的行數據,訪問通過單塊讀取來完成。這裡主要講解全掃描方式,後面將介紹索引掃描。
當對一個表進行全掃描時,會將表中所有數據塊(block)取出並進行處理,篩選出符合條件的數據。注意Oracle必須將整個數據塊(block)中的數據讀到內存中,再取得符合條件的數據。因此Oracle的優化器需要關心兩個信息:獲取塊的數量和每個塊中捨棄的數據量。優化器將根據這兩個信息來判斷是否使用全掃描,首先我們來看看獲取塊的數量怎麼影響優化器的選擇。
總的來說,如果查詢需要取出表的大部分數據塊,則應該采用全掃描。但由於很難評估查詢將取出的表的數據塊的數量,因此在使用全掃描上存在很多這樣的“經驗法則”:當你的查詢會取出表中x%的數據行,則應該選擇全掃描。這些法則有一定的道理,但是並不准確,因為當取出的數據行較大時,自然取出的數據塊也會較大,這時采用全掃描並沒有問題,但有時雖然取出的數據行較小,會取出的數據塊也可能會較大,實際上這時也應該采用全掃描,但這些“經驗法則”則不再生效。我們看看下面具體的例子。
我們創建一個表T1:
create table t1 as select trunc((rownum - 1) / 100) id, rownum value from dba_source where rownum <= 10000
然後為T1創建索引:
create index idx_t1_id on t1(id)
然後為T1收集統計信息:
BEGIN
dbms_stats.gather_table_stats(user,
't1',
method_opt => 'FOR ALL COLUMNS SIZE 1',
cascade => TRUE);
END;
然後我們執行查詢:
select * from t1 where id = 0
該查詢的執行計劃如下:
SELECT STATEMENT, GOAL = ALL_ROWS TABLE ACCESS BY INDEX ROWID INDEX RANGE SCAN
該執行計劃使用了索引范圍掃描,由於符合條件id為0的數據在表中只有100行數據,而整個表有1萬行數據,查詢出的數據只占整個數據的1%,因此我們認為這是一種合理的執行計劃。
接下來我們看下面的例子,創建一個表格T2:
create table t2 as select mod(rownum,100) id, rownum value from dba_source where rownum <= 10000
同樣為T2創建索引:
create index idx_t2_id on t2(id)
然後為T2收集統計信息:
BEGIN
dbms_stats.gather_table_stats(user,
't2',
method_opt => 'FOR ALL COLUMNS SIZE 1',
cascade => TRUE);
END;
然後執行查詢:
select * from t2 where id = 0
該查詢的執行計劃如下:
SELECT STATEMENT, GOAL = ALL_ROWS TABLE ACCESS FULL
我們看到表的執行計劃變成的全表掃描,我們可以很容易的得到該查詢的結果任然是100條數據,占T2表總數據量的1%,如果我們進一步比較T2和T1的數據,會發現兩張表的id字段完全一樣,那為什麼T1選擇的是索引掃描,而T2卻選擇了全表掃描呢?
要了解原因,我們需要從數據在數據塊上的分布來分析,在T1表中,id字段的分布如下:
0 0...0 0 1 1...1 1 2 2...2 2......88 88...88 88......99 99...99 99
而T2表中id字段的分布如下:
0 1 2 3 ... 98 99 0 1 2 3 ... 98 99 ...... 0 1 2 3 ... 98 99
從這裡可以看出T1表中id為0的數據都集中在幾個數據塊上,而T2表中id為0的數據則分布在很多不同的塊上,這樣導致T1的查詢只需要讀取很少塊就可以得到結果,因此使用了索引范圍掃描,而T2上的查詢則需要讀取大部分塊,因此優化器選擇了全表掃描。
需要注意的是,全掃描的效率不僅取決於讀取的數據塊個數,也取決於最終的結果集行數。從上面的例子中我們可以看到:當一個數據塊被讀取後,查詢將根據過濾條件捨棄不符合條件的數據。而這個捨棄的過程是需要耗費資源的,由於這個操作在內存中,因此耗費的將是CPU資源,而捨棄的數據量越大,耗費的CPU資源就越多。
因此,讀取的數據塊的個數越多,捨棄的數據量越大,全掃描的成本(cost)就越高。
不難想象,當表的數據量不斷增大,捨棄的行的數量不斷增加,全掃描的成本不斷增加,最終可能導致優化器放棄全掃描,轉而選擇索引掃描。
多掃描使用的是多塊讀取,即一個單獨的IO調用將會讀取多個塊,讀取的塊的數量是可變的,但有一個上限,通過db_file_multiblock_read_count參數指定,該參數通過下面的SQL查看:
select * from v$parameter where name = 'db_file_multiblock_read_count'
下面描述了Oracle在幾種情況下讀取的塊的數量:
1)Oracle不得不讀取超過一定邊界范圍的數據塊。
在這種情況下,Oracle將會在一次調用中讀取直到邊界范圍的數據塊,然後發起另一次調用來讀取剩下的塊。
2)存在塊已經在內存中
首先讀取那麼已經在內存中的塊,然後發起調用讀取剩下的塊,這意味著多塊讀取可能一次僅讀取一塊。例如,假定多塊讀取的上限是16,該次讀取的數據塊編號為1-16,並且編號為偶數的塊已經在內存中,那麼在這裡例子中,將會有8次的單塊讀取調用來讀取奇數編號的塊。
3)多塊讀取大小超過了操作系統限制
這時取決於你操作系統,因此是可變的。
所謂高水位線,就是表中最後一塊有數據寫入的數據塊。需要注意的是即使幾乎所有數據行都被刪除了,並且一些塊實際上已經完全變為空的了,高水位線還是保持不變。看下面的例子,當表創建並插入數據後:
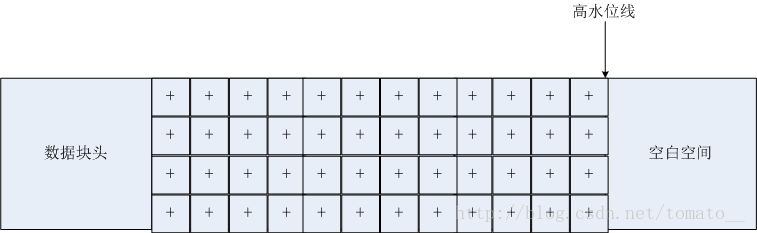
而隨著後面數據的變化(刪除和修改),表中的數據變化為:
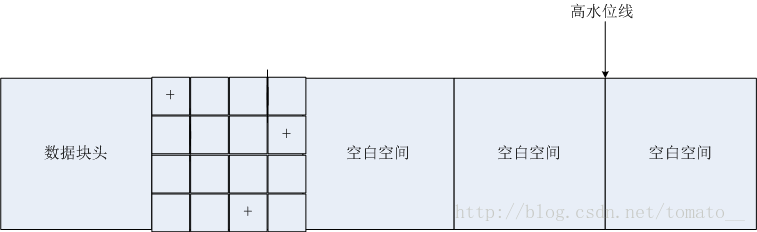
雖然很多存儲區域已經沒有數據,但高水位線任然保持不變。
那麼,高水位線對全掃描會造成什麼影響呢?
執行全掃描時,Oracle將一直讀取到位於表中高水位線的數據塊,即使它們是空的,這就意味著許多實際上不需要讀取的數據塊也被讀取了。
下面通過一個具體的實例來看,使用先前的表T2。
1)通過下面的語句判斷表所包含的數據塊數量:
select blocks from user_segments where segment_name = 'T2' 結果:24
2)確定表中有多少數據塊包含數據;
select count(distinct(dbms_rowid.rowid_block_number(rowid))) block_ct from t2 結果:17
3)執行下面的查詢,並查看trace信息(trace信息的獲取方面見Oracle性能分析1)
alter system flush buffer_cache;--清理緩存 select * from t2 where id = 0
trace信息為:
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 0.00 0.06 18 20 0 100
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 0.00 0.07 18 20 0 100
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 5
Rows Row Source Operation
------- ---------------------------------------------------
100 TABLE ACCESS FULL T2 (cr=20 pr=18 pw=0 time=35975 us)
查詢出100行數據,物理讀取的數據塊數量(disk)為18,包括一個表頭數據塊的讀取(只有17個數據塊包含數據)。執行計劃使用了全表掃描。
4)執行刪除數據的操作
delete from T2
5)重新獲取表包含的數據塊數量
select blocks from user_segments where segment_name = 'T2' 結果:24
6)獲取包含數據的數據塊數量
select count(distinct(dbms_rowid.rowid_block_number(rowid))) block_ct from t2 結果:0
7)執行查詢並查看trace信息
alter system flush buffer_cache;--清理緩存 select * from t2 where id = 0
trace信息為:
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 1 0.00 0.21 18 20 0 0
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 3 0.00 0.22 18 20 0 0
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 5
Rows Row Source Operation
------- ---------------------------------------------------
0 TABLE ACCESS FULL T2 (cr=20 pr=18 pw=0 time=214806 us)
我們可以看到查詢出的行數是0,但任然物理讀取了18個數據塊,執行計劃任然使用了全掃描。
我們已經了解了高水位線給全掃描帶來的性能問題,下面介紹了幾種降低高水位線的方法。
truncate table_name
在刪除數據時盡量使用truncate操作,降低高水位線。
alter table table_name move
注意move操作需要使用額外的表空間存儲,會鎖住表,這樣其他並發的用戶在表上執行的DML語句會產生等待。move操作會影響到表上的索引,因此索引需要rebuild。
shrink space操作,不需要任何額外的空間,但是速度要比move慢上很多。shrink命令分為下面兩種:
1)只壓縮空間不調整水位線,在業務繁忙時可以執行
alter table table_name shrink space compact
compact操作通過一系列insert、delete操作,將數據盡量排列在段的前面。在這個過程中需要在表上加RX鎖,即只在需要移動的行上加鎖。但由於涉及到rowid的改變,因此需要enable row movement。
2)調整水位線 會產生鎖,可以在業務比較少的時候執行,oracle 會記住1步驟中的操作,只調整水位線
alter table big_table shrink space
復制要保留的數據到臨時表t,drop原表,然後rename臨時表t為原表。