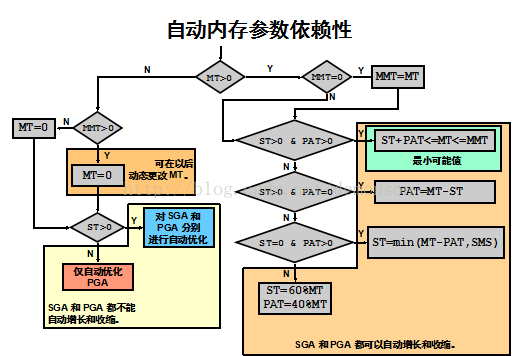
1. NESTED LOOP
對於被連接的數據子集較小的情況,nested loop連接是個較好的選擇。nested loop就是掃描一個表,每讀到一條記錄,就根據索引去另一個表裡面查找,沒有索引一般就不會是 nested loops。一般在nested loop中, 驅動表滿足條件結果集不大,被驅動表的連接字段要有索引,這樣就走nstedloop。如果驅動表返回記錄太多,就不適合nested loops了。如果連接字段沒有索引,則適合走hash join,因為不需要索引。
可用ordered提示來改變CBO默認的驅動表,可用USE_NL(table_name1 table_name2)提示來強制使用nested loop。
要點如下:
1)對於被連接的數據子集較小的情況,嵌套循環連接是個較好的選擇
2)使用USE_NL(table_name1 table_name2)可是強制CBO 執行嵌套循環連接
3)Nested loop一般用在連接的表中有索引,並且索引選擇性較好的時候
4)OIN的順序很重要,驅動表的記錄集一定要小,返回結果集的響應時間是最快的。
5)Nested loops 工作方式是從一張表中讀取數據,訪問另一張表(通常是索引)來做匹配,nested loops適用的場合是當一個關聯表比較小的時候,效率會更高。
2. HASH JOIN
hash join是CBO 做大數據集連接時的常用方式。優化器掃描小表(數據源),利用連接鍵(也就是根據連接字段計算hash 值)在內存中建立hash表,然後掃描大表,每讀到一條記錄就探測hash表一次,找出與hash表匹配的行。
當小表可以全部放入內存中,其成本接近全表掃描兩個表的成本之和。如果表很大不能完全放入內存,這時優化器會將它分割成若干不同的分區,不能放入內存的部分就把該分區寫入磁盤的臨時段,此時要有較大的臨時段從而盡量提高I/O 的性能。臨時段中的分區都需要換進內存做hash join。這時候成本接近於全表掃描小表+分區數*全表掃描大表的代價和。
至於兩個表都進行分區,其好處是可以使用parallel query,就是多個進程同時對不同的分區進行join,然後再合並。但是復雜。
使用hash join時,HASH_AREA_SIZE初始化參數必須足夠的大,如果是9i,Oracle建議使用SQL工作區自動管理,設置WORKAREA_SIZE_POLICY 為AUTO,然後調整PGA_AGGREGATE_TARGET即可。
以下條件下hash join可能有優勢:
1)兩個巨大的表之間的連接。
2)在一個巨大的表和一個小表之間的連接。
要點如下:
1)散列連接是CBO 做大數據集連接時的常用方式.
2)也可以用USE_HASH(table_name1 table_name2)提示來強制使用散列連接
3)Hash join在兩個表的數據量差別很大的時候.
4)Hash join的工作方式是將一個表(通常是小一點的那個表)做hash運算並存儲到hash列表中,從另一個表中抽取記錄,做hash運算,到hash 列表中找到相應的值,做匹配。
可用ordered提示來改變CBO默認的驅動表,可用USE_HASH(table_name1 table_name2)提示來強制使用hash join。
3. SORT MERGE JOIN
a)對連接的每個表做table access full;
b)對table access full的結果進行排序;
c)進行merge join對排序結果進行合並。
sort merge join性能開銷幾乎都在前兩步。一般是在沒有索引的情況下,9i開始已經很少出現,因為其排序成本高,大多為hash join替代。
通常情況下hash join的效果都比sort merge join要好,但是,如果行源已經被排過序,在執行sort merge join時不需要再排序,這時sort merge join的性能會優於hash join。
當全表掃描比“索引范圍掃描後再通過rowid進行表訪問”更可取的情況下,sort merge join會比nested loops性能更佳。
要點如下:
1)使用USE_MERGE(table_name1 table_name2)來強制使用排序合並連接.
2)Sort Merge join 用在沒有索引,並且數據已經排序的情況.
3)連接步驟:將兩個表排序,然後將兩個表合並。
4)通常情況下,只有在以下情況發生時,才會使用此種JOIN方式:
a)RBO模式
b)不等價關聯(>,<,>=,<=,<>)
c)bHASH_JOIN_ENABLED=false
d)數據源已排序
e)Merge Join 是先將關聯表的關聯列各自做排序,然後從各自的排序表中抽取數據,到另一個排序表中做匹配,因為merge join需要做更多的排序,所以消耗的資源更多。
f) like ,not like
通常來講,能夠使用merge join的地方,hash join都可以發揮更好的性能
可用USE_MERGE(table_name1 table_name2)提示強制使用sort merge join。
想要成為大師,必須系統學習
SQL SERVER連接oracle數據庫幾種方法
--1 方式
--查詢oracle數據庫中的表
SELECT *
FROM OPENDATASOURCE(
'MSDAORA',
'Data Source=GE160;User ID=DAIMIN;Password=DAIMIN'
)..DAIMIN.JOBS
--在sqlserver中創建與oracle數據庫中的表同名的表
select * into JOBS from
OPENDATASOURCE(
'MSDAORA',
'Data Source=GE160;User
ID=daimin;Password=daimin'
)..DAIMIN.JOBS
select * from JOBS
--2、方式
--在master數據庫中查看已經存在的鏈接服務器
select * from sysservers
EXEC sp_addlinkedserver
@server = 'GE160',
@srvproduct = 'Oracle',
@provider = 'MSDAORA',
@datasrc = 'GE160'
exec sp_addlinkedsrvlogin 'GE160', false, 'sa', 'daimin', 'daimin'
--要在企業管理器內指定登錄帳號
exec sp_dropserver GE160
select * from GE160..DAIMIN.JOBS
delete from GE160..DAIMIN.JOBS
--備注:引用ORACLE服務器上的表時,用戶名稱與表名一定要大寫字母。
SELECT *
FROM OPENQUERY(GE160, 'SELECT * FROM DAIMIN.JOBS')
--3、方式
SELECT a.*
FROM OPENROWSET('MSDAORA',
'GE160';'DAIMIN';'DAIMIN',
DAIMIN.JOBS) AS a
ORDER BY a.JOB_ID
--4、方式 ODBC
--ODBC方式比較好辦
SELECT A.*
FROM
OPENROWSET('MSDAORA','GE160';'DAIMIN';'DAIMIN', --GE160是數據源名
DAIMIN.JOBS) AS
A
ORDER BY A.JOB_ID...余下全文>>