Oracle數據庫的並行操作特性,其本質上就是強行搾取除數據庫服務器空閒資源(主要是CPU資源),對一些高負荷大數據量數據進行分治處理。並行操作是一種非確定性的優化策略,在選擇的時候需要小心對待。目前,使用並行操作特性的主要有下面幾個方面:
Parallel Query:並行查詢,使用多個操作系統級別的Server Process來同時完成一個SQL查詢;
Parallel DML:並行DML操作。類似於Parallel Query。當要對大數據量表進行DML操作,如insert、update和delete的時候,可以考慮使用;
Parallel DDL:並行DDL操作。如進行大容量數據表構建、索引rebuild等操作;
Parallel Recovery,並行恢復。當數據庫實例崩潰重新啟動,或者進行存儲介質恢復的時候,可以啟動並行恢復技術。從而達到減少恢復時間的目的;
Procedural Parallel,過程代碼並行化。對我們編寫的代碼片段、存儲過程或者函數,可以實現執行的並行化,從而加快執行效率;
1、並行查詢Parallel Query
Oracle數據庫的並行查詢是比較基礎的技術,也是OLAP和Oracle Data Warehouse經常使用的一種並行技術。同本系列前面一直強調的要素相同,在確定使用並行技術之前,要確定軟硬件的一些先決條件:
任務task必要條件。備選進行並行操作的任務task必須是一個大任務作業,比如,長時間的查詢。任務時間通常可以以分鐘、小時進行計數。只有這樣的任務和需要,才值得讓我們冒險使用並行操作方案;
資源閒置條件。只有在數據庫服務器資源存在閒置的時候,才可以考慮進行並行處理。如果經常性的繁忙,貿然使用並行只能加劇資源的爭用。
並行操作最大的風險在於並行爭用引起的效率不升反降。所以,要在確定兩個前提之後,再進行並行規劃處理。
2、環境准備
首先,准備實驗環境。由於筆者使用的一般家用PC虛擬機,所以並行度和存儲量不能反映真實條件需求,見諒。
SQL> select * from v$version where rownum<2; BANNER -------------------------------------------------------------------------------- Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - Production SQL> select count(*) from t; COUNT(*) ---------- 1160704
選擇11gR2服務器環境,數據表T總數據量超過一百萬。
首先,我們觀察一下不使用並行的執行情況。
//提取出使用游標信息;
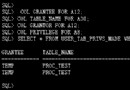
SQL> select sql_text, sql_id, version_count from v$sqlarea where sql_text like 'select count(*) from t%';
SQL_TEXT SQL_ID VERSION_COUNT
------------------------------ ------------- -------------
select count(*) from t 2jkn7rpsbj64t 2
SQL> select * from table(dbms_xplan.display_cursor('2jkn7rpsbj64t',format => 'advanced', cursor_child_no => 0));
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
SQL_ID 2jkn7rpsbj64t, child number 0
-------------------------------------
select count(*) from t
Plan hash value: 2966233522
-------------------------------------------------------------------
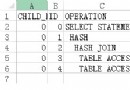
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
-------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | 4464 (100)| |
| 1 | SORT AGGREGATE | | 1 | | |
| 2 | TABLE ACCESS FULL| T | 1160K| 4464 (1)| 00:00:54 |
-------------------------------------------------------------------
該執行計劃中沒有使用並行特性,進行全表掃描。執行時間為54s。
3、並行查詢計劃
首先,我們設置相應的並行度。設置並行度有兩種方式,一種是使用hint加在特定的SQL語句上。另一種是對大對象設置並行度屬性。
前者的優點是帶有一定的強制性和針對性。就是指定特定的SQL語句進行並行處理。這樣的優點是易於控制並行度,缺點是帶有很強的強制力,當數據量偏小的時候,使用並行優勢不大。而且如果是顯示指定並行度,又會帶來移植伸縮性差的缺點。
後者通過對象的屬性指定並行度。就將並行作為一種執行手段,提供給優化器進行選擇。這樣,CBO會根據系統中資源的情況和數據的實際,進行執行計劃生成。計劃中可能是並行,也可能不是並行。這樣的優點是將並行與否交予優化器CBO去判斷,缺點是並行的濫用風險。
此處,筆者設置自動確定並行度的方式。
SQL> alter table t parallel; Table altered SQL> select count(*) from t; COUNT(*) ---------- 1160704
當啟動查詢時,Oracle中的並行伺候進程池會根據系統中的負荷和實際因素,確定分配出的並行進程數量。此時,我們可以通過視圖v$px_process來查看進程池中的連接信息。
SQL> select * from v$px_process; SERVER_NAME STATUS PID SPID SID SERIAL# ----------- --------- ---------- ------------------------ ---------- ---------- P000 AVAILABLE 25 5776 P001 AVAILABLE 26 5778
注意,並行伺候進程是一種特殊的Server Process,本質上是一種可共享的slave進程。專用連接模式下,一般的Server Process與Client Process是“同生共死”的關系,終身服務於一個Client Process。而伺候slave進程是通過進程池進行管理的,一旦啟動初始化,就會在一定時間內駐留在系統中,等待下次並行處理到來。
此時,我們檢查v$process視圖,也可以找到對應的信息。
SQL> select * from v$process; PID SPID PNAME USERNAME SERIAL# PROGRAM -------- ---------- ------------------------ ----- --------------- ---------- ------------------------------- 25 5776 P000 oracle 13 oracle@oracle11g (P000) 26 5778 P001 oracle 6 oracle@oracle11g (P001) (篇幅由於原因,予以省略……) 32 rows selected
對應的OS中,也存在相應的真實進程伺候。
[oracle@oracle11g ~]$ ps -ef | grep oracle (篇幅由於原因,予以省略……) oracle 5700 1 0 17:29 ? 00:00:02 oraclewilson (LOCAL=NO) oracle 5723 1 0 17:33 ? 00:00:00 ora_smco_wilson oracle 5764 1 2 17:40 ? 00:00:05 oraclewilson (LOCAL=NO) oracle 5774 1 0 17:42 ? 00:00:00 oraclewilson (LOCAL=NO) oracle 5776 1 0 17:43 ? 00:00:00 ora_p000_wilson oracle 5778 1 0 17:43 ? 00:00:00 ora_p001_wilson oracle 5820 1 1 17:44 ? 00:00:00 ora_w000_wilson
由於此時查詢已經結束,對應的並行會話信息,已經消失不可見。
SQL> select * from v$px_session; SADDR SID SERIAL# QCSID QCSERIAL# -------- ---------- ---------- ---------- ----------
但是,如果任務的時間長,是可以捕獲到對應信息的。
從上面的情況看,我們執行一個並行操作時,Oracle會從伺候進程池中獲取到對應的並行進程,來進行操作。當操作完成後,伺候進程還會等待一定時間,之後回收。
並行操作進程的資源消耗,通過v$px_sysstat視圖查看。
SQL> col statistic for a30; SQL> select * from v$px_process_sysstat; STATISTIC VALUE ------------------------------ ---------- Servers In Use 0 Servers Available 0 Servers Started 2 Servers Shutdown 2 Servers Highwater 2 Servers Cleaned Up 0 Server Sessions 6 Memory Chunks Allocated 4 Memory Chunks Freed 0 Memory Chunks Current 4 Memory Chunks HWM 4 Buffers Allocated 30 Buffers Freed 30 Buffers Current 0 Buffers HWM 8 15 rows selected
下面,我們檢查一下執行計劃信息。
SQL> set pagesize 10000;
SQL> select * from table(dbms_xplan.display_cursor('2jkn7rpsbj64t',format => 'advanced',cursor_child
_no => 1));
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
SQL_ID 2jkn7rpsbj64t, child number 1
-------------------------------------
select count(*) from t
Plan hash value: 3126468333
----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time | TQ |IN-OUT| PQ Distrib
----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | 2478 (100)| | | |
| 1 | SORT AGGREGATE | | 1 | | | | |
| 2 | PX COORDINATOR | | | | | | |
| 3 | PX SEND QC (RANDOM) | :TQ10000 | 1 | | | Q1,00 | P->S | QC (RAND)
| 4 | SORT AGGREGATE | | 1 | | | Q1,00 | PCWP |
| 5 | PX BLOCK ITERATOR | | 1160K| 2478 (1)| 00:00:30 | Q1,00 | PCWC |
|* 6 | TABLE ACCESS FULL| T | 1160K| 2478 (1)| 00:00:30 | Q1,00 | PCWP |
----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
6 - access(:Z>=:Z AND :Z<=:Z)
從執行計劃的條件(6 - access(:Z>=:Z AND :Z<=:Z))中,我們可以看到任務分配,之後分別進行全表掃描。最後排序計算count,合並結果的過程。
4、結論
Oracle Parallel Query是經常使用到的一種並行操作技術。相對於DDL、DML等類型操作,並行查詢更可以作為系統功能的一個步驟來進行。
進行並行查詢最大的風險就是並行濫用和失控的出現。這也是Oracle一直致力解決的問題。在Oracle11gR2中,引入了Parallel Statement Queuing(PSQ)技術特性。通常,只要並行伺候池允許,Oracle會引入盡可能多的並行進程進行操作。PSQ技術的出現,就是從資源角度加入了並行控制。
當系統繁忙的時候,PSQ會將一些要進行的並行操作進入等待狀態,防止並行環境的惡化。當環境好轉之後,等待隊列中的並行語句就進入執行狀態。這個特性就可以有效的防止並行濫用的出現。