一、索引簡介
1、索引相當於目錄
2、索引是通過一組排序後的索引鍵來取代默認的全表掃描檢索方式,從而提高檢索效率。
3、索引的創建要適度,多了會影響增刪改的效率,少了會影響查詢的效率,索引最好創建在取值分散的列上,避免對同一張表創建過多的索引
4、索引的使用對用戶來說是透明的,由系統來決定什麼時候使用索引。
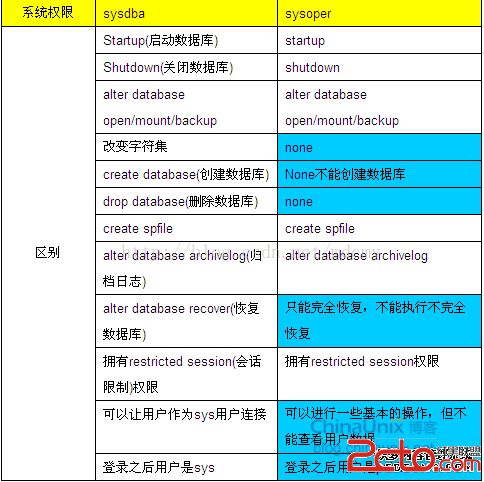
5、Oracle支持多種類型的索引,可以按列的多少、索引值是否唯一和索引數據的組織形式對索引進行分類,以滿足各種表和查詢條件的要求。(請見附件)
a. 單列索引和復合索引
b.B樹索引(create index時默認的類型)
B樹索引中所有葉子節點都具有相同的深度,所以不管查詢條件如何,查詢速度基本相同。另B樹索引能夠適應各種查詢條件,包括精確查詢、模糊查詢和比較查詢
--Unique 唯一索引 值唯一,但允許存在null,主鍵默認存在唯一索引,但列不能為null
--Non-Unique:非唯一索引,其索引值可以重復,允許為NULL。默認情況下,Oracle創建的索引是非唯一索引
--Reverse Key:反向關鍵字索引。通過在創建索引時指定“REVERSE”關鍵字,可以創建反向關鍵字索引,被索引的每個數據列中的數據都是反向存儲
的,但仍然保持原來數據列的次序
c.位圖索引(對列值范圍少,如性別 政治面貌適用,而不是默認的B樹索引)
c.函數索引
當需要經常訪問一些函數或表達式時,可以將其存儲在索引中,當下次訪問時,由於該值已經計算出來了,因此,可以大大提高那些在WHERE子句中包含該函數或
表達式的查詢操作的速度;
函數索引既可以使用B樹索引,也可以使用位圖索引。
二、管理索引的原則
使用索引應該遵循以下一些基本的原則。
1.小表不需要建立索引。
2.對於大表而言,如果經常查詢的記錄數目少於表中總記錄數目的15%時,可以創建索引。這個比例並不絕對,它與全表掃描速度成反比。
3.對於大部分列值不重復的列可建立索引。
4.對於基數大的列,適合建立B樹索引,而對於基數小的列適合建立位圖索引。
5.對於列中有許多空值,但經常查詢所有的非空值記錄的列,應該建立索引。
6.LONG和LONG RAW列不能創建索引。
7.經常進行連接查詢的列上應該創建索引。
8.在使用CREATE INDEX語句創建查詢時,將最常查詢的列放在其他列前面。
9.維護索引需要開銷,特別時對表進行插入和刪除操作時,因此要限制表中索引的數量。對於主要用於讀的表,則索引多就有好處,但是,一個表如果經常被更改,則索引應少點。
10.在表中插入數據後創建索引。如果在裝載數據之前創建了索引,那麼當插入每行時,Oracle都必須更改每個索引。
三、LONG類型(可存儲2G)主要用於不需要作字符串搜索的長串數據,如果要進行字符搜索就要用varchar2類型,存儲這麼長的請使用 pstat1.setCharacterStream()方法,資料見附件P26
四、創建索引語法如下
CREATE INDEX語句的語法如下:
CREATE [UNIQUE] | [BITMAP] INDEX index_name
ON table_name([column1 [ASC|DESC],column2
[ASC|DESC],…] | [express])
[TABLESPACE tablespace_name]
[PCTFREE n1]
[STORAGE (INITIAL n2)]
[NOLOGGING]
[NOLINE]
[NOSORT];
五、
1、查看索引信息可以在 all_indexs 表中
2、查看索引信息及引用的列 all_ind_columns
3、查看函數索引信息 all_ind_expressions
4、oracle比較智能,有時候即使創建了索引也不會使用,比如說在數據量比較少的情況下,可能就不會用索引
5、當進行全表掃描的時候,不用索引效率會更好
6、查詢可能會使用緩存,所以說如果發現執行速度變快了,不一定說明你的sql更優了,有可能是使用到了緩存而已
7、使用plsql中的“解釋計劃”功能可以比較執行計劃的消耗,進而寫出更優的sql