This queston came up on the Oracle newsgroup a few days ago:
這個問題在Oracle的新聞中心被提出了一段時間:
I have a table (call it policy) with three columns a, b and c. The table has two rows, with column c having value zero for both rows. I run the following query
有個表(表名是Policy),有三個字段:a、b、c,這個表有兩行,c列中的數據始終為0,我運行一下的sql語句
policy c;
As both the rows have a value of zero, the result should be sorted ascending by rowid, but I see the opposite; viz. the result set is sorted descending by rowid.
照理說,結果應該按照rowid來升序排序,但是相反的是,結果卻按照rowid降序排序。
Is that an issue with the version of 10g server, I am using or is it some settings of the Oracle server?
這個是10g的問題,還是我使用的問題,或者還是設置的問題?
Various people replied to say that you should never assume any ordering beyond the order you explicitly state in the order by clause. But the question does raise a couple of interesting points.
其他的人說,最好是顯式的聲明排序的條件,比如rowid desc。但是這個問題引發了一個有趣的觀點。
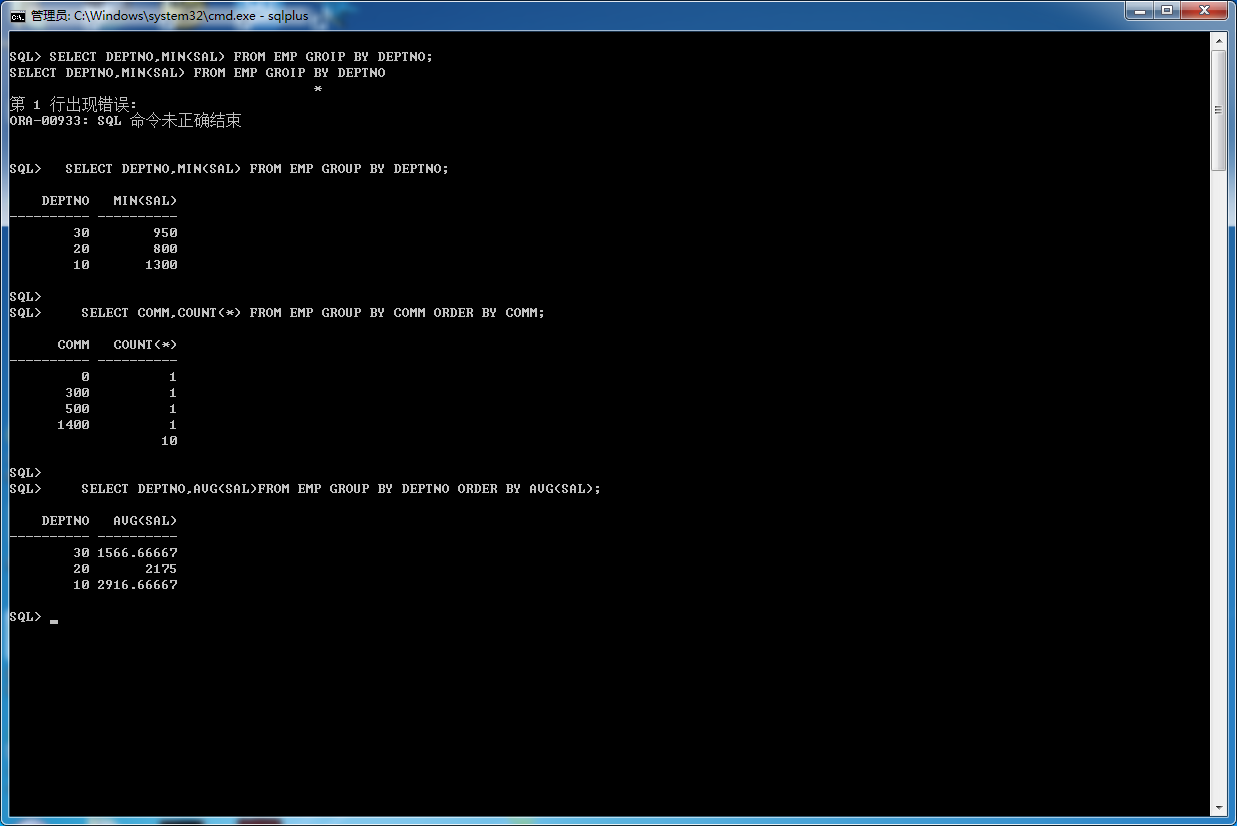
Let’s start by running the test (it’s not hard to write up a test case, so why not do so when you ask the question). The following is good enough – and I’ve appended the output of the query when running on 10.2.0.1:
當你遇到問題的時候,最好寫一個測試的例子,例如下面的例子,運行在10.2.0.1上:
t1 (a , b , c t1 (,, t1 (,, t1., t1.rowid t1
兩行數據被查詢出來,果然數據排序錯誤。
So what do you do next ? The first couple of ideas are: add a third, fourth and fifth row to see if the “descending order” observation is accurate; then try running the test on a different version of Oracle.
接下來你要怎麼做?第一個想法是,添加第三行、第四行、第五行數據,查看“descending order”是否准確,然後運行在不同版本的oracle中。
Here’s the output from 10.2.0.1, after adding more and more rows:
下面的結果集是在10.2.0.1中添加第三行、第四行、第五行數據,並查詢的結果
AAATncAAGAAABSKAAC
The results are NOT in descending order of rowid – it just looks that way in the very first case.
結果是並沒有按照rowid進行降序排序,
But here’s the output from the same test running on 9.2.0.8:
同樣的測試運行在9.2.0.8:
AAALJkAAJAAABIKAAE
在9.2.0.8中,是按照rowid進行了升序排序
The Answer
Oracle introduced a new sorting algorithm (sometimes known as the Version 2 sort, which is how it is labelled in the 10032 trace) in 10.2.
答案
Oracle 10.2引入了一個新的排序算法,稱為版本2。
The previous algorithm was effectively building an in-memory index on the incoming data using a balanced binary tree and seeking to the righ (i.e. optimised towards data that appeared in the correct order and keeping such data in the order of appearance - hence the apparent sorting of rowids in our example in 9i).
前面的例子有效的構建一個內存中索引輸入數據使用平衡二叉樹和(即優化對數據出現在正確的順序和保持這些數據出現的順序,明顯的例子就是9i的查詢結果)
The CPU and memory overheads for this algorithm are a bit fierce for large sorts, so the new algorithm does something completely different (possibly based on a variant of the heapsort, though it isn’t actually a heapsort) which is more efficient on memory and CPU. It has the side-effect though, of re-ordering incoming rows even when the data is not arriving out of order.
這個算法的cpu和內存開銷有點大,所以新的算法做了一些改變。類似於堆排序的一種變體,但不是堆排序。它也有副作用,就是重新排序行
Someone who knew their sorting algorithms really well might even be able to infer the algorithm Oracle was using by extending the test case and watching the rowids re-ordering themselves as the result set grows. But I’m not going to volunteer for that task.
人們知道他們的排序算法很好,但是我不願意做小白鼠。
If you want to disable the new sorting mechanism, there is a hidden parameter to affect it. As usual, you shouldn’t use hidden parameters without first receiving confirmation from Oracle support that you need to, but the relevant parameter is: _newsort_enabled, which defaults to true in 10g.
如果你想禁用新的排序機制,有個隱藏的參數“_newsort_enabled”,默認為true。
原文出處:http://jonathanlewis.wordpress.com/2007/06/03/sorting/
參考資料:http://blog.sina.com.cn/s/blog_6ff05a2c0100mlco.html