如何保證數據庫結構的合理性
最近重溫了下《SQL查詢凡人入門》,對裡面提到保證數據庫結構的合理性深有感觸,故總結如下,與大家分享。
數據庫中字段是表的基本結構部分,所以在調整整個表之前必須使得字段都是處於最好狀態。很多情況下,字段的選擇確定會減少很多給定表的已有問題,也能避免一些潛在的問題的產生。
1)字段名稱的調整
字段描述的是表所描述的物體的特征。如果給字段一個合適的名稱,就可以標識這個打算要描述的特征。一個有歧義的含糊不清的名稱是一個麻煩的征兆,暗含這個字段的代表含義還沒有真正明確下來。可以利用下面清單中的內容檢查每一個字段名稱。
1.對整個組織來說,這個名稱是否具有一定的說明意義?
要確保對於訪問這個字段的每個人來說這個名稱都是有描述意義的。語義有時候是非規則的,如果字段所用的詞對於不同的人群來說語義不同,那就麻煩了。就好象在大部分地區,搖頭表示的是“No”,而在印度,搖頭則表示“Yes”。
2.這個字段是否清楚沒有歧義?
比如PhoneNumber就很容易讓人誤會。描述的是哪種電話號碼?為了明確起見,如果需要記錄每一種電話號碼,那麼應創建HomePhone、WorkPhone、CellPhone這樣的字段。
另外還需要確保不會在不同的表中使用相同的字段名。如有必要,建議在相同的字段名稱前面加上一個短短的前綴。比如,Vendors表中用VendCity,Customers表中用CustCity,Employees表中用EmpCity這樣的名稱。
總之,確保數據庫中的每一個字段都有唯一的名稱,在整個數據庫結構中僅出現一次。除非這一字段被用來建立兩個表之間的關聯關系。
3.是否使用首字母的縮寫或者其他縮寫形式作為字段名稱?
如果有,請修改它!首字母的縮寫很難解釋,易被誤解。使用縮寫要非常謹慎,處理的時候也小心。如果對字段名稱有一個信息的正向補充增強作用的情況下才使用縮寫,縮寫不能損害字段本身所表示的意義。
4.是否使用了暗含或者明確標識多個特性的字段名稱?
這種字段一般很容易發現,因為有類似於“and”或“or”這樣的代表性字詞。包含反斜線符號(\)、連字符(-)、與的記號(&)的字段同樣也屬於這一類型。如果發現這樣的字段,檢查所存儲的數據,看是否需要將它們拆開成為更小的單獨字段。
5.確保字段名稱的單數形式
字段所描述的是表所代表的物體的單一的特征,所以字段名應該是單數。而另一方面,表的名稱之所以是復數,是因為它所描述的是同類對象或事件的集合。使用這一命名規則後,區分表的名稱和字段名稱就是一件很容易的事了。
2)消除粗糙的邊
修正了字段名,現在就應該轉而注意字段本身的結構了。雖然對字段的合理性已經有了相當的把握,但還是有幾點需要繼續努力來使字段結構盡可能更加合理高效。
1.確保字段描述的是表所表示的物體某一特性。
這一步可確定字段是否真的屬於這個表。如果它和這個表的關系並不密切,那就刪除它。這個規則也有一個例外情況:這個字段是用來建立這個表和數據庫中另一個表之間的關聯關系,或為了完成數據庫應用的某些任務而專門添加到表中。
2.確保字段中僅包含一個單一的值。
一個字段可能會潛在地保存相同值的幾個具體實例,這稱為多值字段。同樣地,一個字段也可能潛在地保存兩個或多個各自不同的值,這稱為多型字 段。多值字段和多型字段會給數據庫管理帶來混亂,尤其是在對這些數據進行編輯、刪除和排序時。當每一個字段存儲的是單一值時,會對保證數據完整性和信息正 確性有很大的幫助。
3.確保字段所存儲的內容不是計算結果或者一連串事件的結果。
一個設計良好的表中不允許出現計算列。主要原因是因為計算列的值本身。這裡的字段,不像電子數據表格中的一個單元,不能保存一個具體的計算 值。當計算表達式中的任何一部分改變,存儲在字段中的計算值不會隨之更新。唯一方式是手工修改或者編寫代碼年進行自動修改。然而,使用計算列的首選是在 SELECT語句中結合使用。
4.確保在整個數據庫中一個字段僅出現一次。
一個普遍錯誤是向數據庫中的好幾個表插入了相同的字段,那就會面臨數據不一致的問題。此時,改變了一個表中的這個字段而忘記了對其他表中的相 同字段進行相同的修改,就會出現數據的不一致。避免這個問題的方法微十時毫 確保整個數據庫結構中一個字段僅出現一次。(此規則的例外情況是用某一個字段來建立兩個表之間的關聯關系。)
3)多型字段的處理
識別多型字段可以先回答一個簡單問題:是否能將當前字段的值分解成更小的獨立的幾部分?如果回答“是”,那麼這就是一個多型字段。
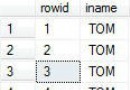
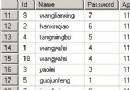
比如Customers表中有這個一個字段StreetAddress,裡面的記錄為“15127 NE 24th ,#383 ,Redmond ,WA 98052”。這個字段就可以拆分為CustAddress、CustCity、CustState和CustZipcode,分別存儲15127 NE 24th 、Redmond、WA和98052。
下面是書中調整前和調整後的表:
調整後:
有時候可能識別一個多型字段是比較困難的,比如Instruments表中有這麼一個字段IstrumentID,裡面存儲了 GUIT2201、MFX3349、AMP1001、AMP5590、SFX2227和AMP2766。乍看好象不是多型字段,仔細查看就會發現,此字段 的值中包含了兩個不同的信息:設備所屬的類別——如AMP(amplifier,擴音器)、GUIT(guitar,吉他)和 MFX(multieffects unit,音效組合)——以及這些設備的標識號碼。這兩個值應該分開保存在各自的字段中,以保證數據完整性。下圖是Instruments表:
4)多值字段的處理
多值字段的處理比多型字段相對困難一些,但是值得慶幸的是,多值字段一眼就能識別出來。幾乎毫無例外的,這一類型字段存儲的值包含許多逗號,逗號用來分隔字段中值的不同部分。
在對多值字段進行處理之前,要先明白最初想要賦予的多值字段和表之間的關系。多值字段的值和其父表中的記錄是M:M的關系:一個多值字段中的 某一個確定的值和父表中的多個記錄相關,父表中的一個記錄和多值字段中的多個值相關聯。處理這種多對多關系和其他多對多關系的方法一樣——用一個關聯表。
要創建關聯表,使用多值字段並復制原來表中的主關鍵字作為建立新表的基礎部分。給這個新的關聯表一個合適的名字,並指定這兩個字段為其組合主 關鍵字。(這種情況下,組合兩個字段中的值就能惟一標識新表中的每一個記錄。)然後就可以在一對一的基礎上對新表中的兩個字段關聯了。
比如現在有Pilots表,表中有三個字段PilotID、PilotName、Certifications,有兩個記錄分別 為:25100、John、727,737,757,MD80;25101、David、737,747,757。很注意到Certifications 是一個多值字段(存儲的值包含了逗號),先將Certifications從Pilots表中刪除,然後將根據Certifications的內容新建 Certifications表,Certifications表中有如下字段CertificationID和TypeofAircraft,包含記錄 如下:8102、Boeing 727;8103、Boeing 737;8104、Boeing 747;8105、 Boeing 757;8106、 McDonnell Douglas MD80。接著,在創建一關聯表,比如Pliot Certifications表,表中的字段分別為Pilots表的主鍵PilotID和Certifications表的主鍵 CertificationID。根據原來的記錄,Pliot Certifications表中會有如下記錄:25100、8102;25100、8103;25100、8105;25100、 8106;25100、8103;25100、8104;25101、8105。
表是創建SQL查詢的基礎。設計不好的表會導致數據完整性方面的問題,並且在多表查詢時會遇到困難。因此,必須先確保所涉及的數據表的結構盡可能高效,這樣才能方便地提取數據。
1)表名稱的調整
表創建了就應該描述一個特定的物體,如果其描述的物體超過一個,那麼就應該將其分割為幾個小的表。表的名稱必須清楚地標識所描述的物體。如果 一個表名稱是不夠明確、會產生歧義或者意義不清楚,那麼肯定對這個表所描述餓對象考慮得不是很周詳。可以通過下面各項來檢查表名稱是否合理。
1.在整個組織中此名稱是否惟一並且具有描述意義?
給數據庫中的表一個惟一的名稱,確保所描述的是不同的物體而且組織中的每一個人都能明白表所描述的是什麼。定義一個惟一的說明性的名稱雖然不是份內的工作,但這樣做還是值得的。
2.名稱是否清楚、精確、沒有歧義地標識該物體?
當表名稱意義含混不清有歧義時,就可以確定這個表描述的物體可能多於一個。“Dates”就是一個很好的說明例子,它的表名含糊不清。這時很難確定表所描述的內容,除非手邊同時有其他相關的說明資料。這種情況下,不妨將表分成多個表並且分別給予正確的命名。
3.名稱中是否有表述物理特性的詞?
避免使用這樣的字詞如“文件”、“記錄”、“表”,因為這樣會引起一定的混淆,使用這一類型的詞的表名稱看起來很像是描述多個物體。
假定有這樣的名稱“Employee_Record”,表面上,這個名稱沒有任何問題,但是當考慮到它應該描述的是什麼樣的雇員記錄的時候, 就會認識到這個名稱暗含的問題。這個名稱包含了我們盡量避免的詞,它可能描述了三個事物:雇員employees、部門departments和薪水冊 payroll。考慮到這點,可將原來的表(Employee_Record)分成三個表,沒一個表描述一個事物。
4.是否使用首字母縮寫或者其他縮寫形式作為一個表的名稱?
縮寫形式很少能表述清楚事物,首字母縮寫通常也很難解釋。
比如公司的數據庫中有表SC,不同部門可能會把這個表理解成不同的事物。人事部的人會認為它代表著Steering_Committees; 信息系統處的人相信它是System_Configurations;安全處的人會覺得是Security_Codes。這個例子就很好地說明了為什麼要 避免使用首字母縮寫和其他縮寫形式作表的名稱。
5.使用的名稱是否暗含或者明確描述了多個事物?
這種類型的名稱一般包含有“and”“or”這樣的字詞或者反斜線(\)、連字符(-)、與連接符(&)等字符。以這種方式為表命名時,必須弄清楚該表是否描述了多個事物,如果是,請將它拆分成為多個小的表,然後給每個表一個合適的名稱。
6.最後檢查每一個表的名稱,確保表名稱是復數形式。
使用復數形式是因為表所存儲的是所代表事物的具體實例的集合。
2)確保良好的結構
表結構合理是絕對有必要的,只有這樣才能有效地存儲數據,並提取到准確的信息。確保表的結構合理需要花費一些時間,但這在創建復雜的多表SQL查詢時卻會獲益不小。可以根據下面列表中的內容檢查表結構是否合理。
1.確保表所描述的是一個單一的事物。
這個已經多次提到過,但再怎麼強調其重要性也不過分。只要保證了每一個表描述一個單一事物,就會大大降低可能的數據完整性危險問題。
2.確保每一個表有一個主關鍵字。
必須給表分配一個主關鍵字,原因有二:一是主關鍵字能惟一標識表中的每一個記錄,二是主關鍵字用來建立表之間的關聯關系。如果沒有給每一個表指定主關鍵字,最終將會遇到有關數據完整性的問題和一些類型的SQL多表查詢問題。
3.確保表中沒有任何多值和多型字段。
理論上,在對字段結構進行改進後,這一問題就不會存在了。雖然如此,最後再檢查一遍,確保這樣兩種情況都不存在,仍不失為一個好主意。
4.確保表中沒有計算字段。
雖然很可能相信當前的表中不存在計算列,但也可能在字段修正時忽略了那麼一兩個。現在是時候再查看一遍並把漏掉的計算列刪除掉。
5.確保表中沒有任何不必要的復制列。
設計不好的表結構的特點之一就是它包含了其他表中的復制列。可能由於這樣一兩個原因會讓你覺得不得不添加復制列到表中,比如:提供“引用”信息,或標志一個特定類型值的多次出現。這些復制列在數據操作或信息提取時會制造很多麻煩。下面會看到如何處理這樣的復制列。
3)不必要的復制列的處理
下圖是一個包含參考信息的復制列的表。
(PS:特別說明一下,這裡的Staff表中,Staff表示的是全體職員,我剛開始以為書裡面印刷錯誤少印了復數形式。)
在這種情況下,Classes表中有StaffLastName和StaffFirstName字段,這樣查看表的人就能看到某個指定班級指 導員的姓名。然而,由於在Classes和Staff表之間已經存在1:M的關系,這兩列就屬於非必要復制列。(一個教員可以指導很多班級,而一個班級只 能由一個指定的教員指導。)StaffID建立了這兩個表之間的聯系,此聯系讓人在一個SQL查詢中可以同時從兩個表中查看數據。考慮到這點,就可以大膽 地把Classes表中的StaffLastName和StaffFirstName字段刪除,而不會有任何副作用。下面是修改後的表結構。
如果保留這些不必要的字段,隨後所出現的最主要的問題就是數據的不一致。必須要保證Classes表中的StaffLastName和StaffFirstName字段的值和Staff表中相應的部分總是匹配對應的。
比如一位女教員結婚了並打算從此將夫姓作為她的法定姓名。這時不僅要對Staff表中她的記錄作合適的修改,還要確保Classes表中所有 出現她姓名的地方都要作相應的修改。而以後有可能還有這樣的工作要做,這樣就做了很多不必要的辛苦工作。除此之外,使用關系數據庫最主要的一個前提就是在 整個數據庫中一塊數據只應該輸入一次。(例外情況即這個字段是用來建立兩個表之間的聯系。)最好的處理方式就是把數據庫中所有的復制字段刪除。
*