最近學習了一下SQL的分頁查詢,總結了以下幾種方法。
首先建立了一個表,隨意插入的一些測試數據,表結構和數據如下圖:
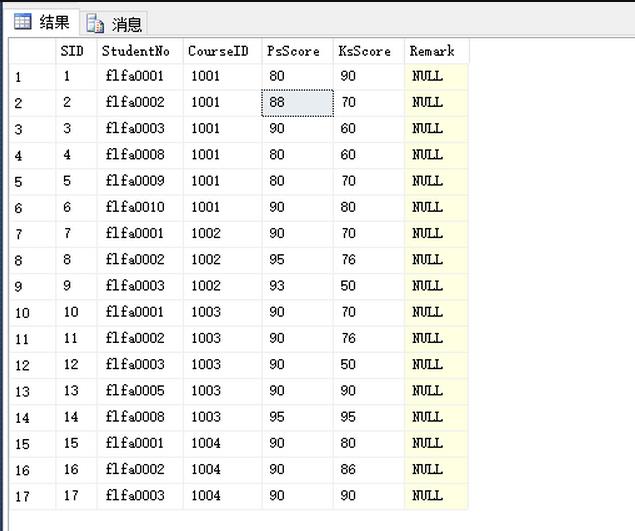
現在假設我們要做的是每頁5條數據,而現在我們要取第三頁的數據。(數據太少,就每頁5條了)
方法一:
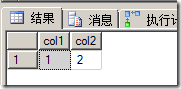
select top 5 * from [StuDB].[dbo].[ScoreInfo] where [SID] not in (select top 10 [SID] from [StuDB].[dbo].[ScoreInfo] order by [SID]) order by [SID]
結果:
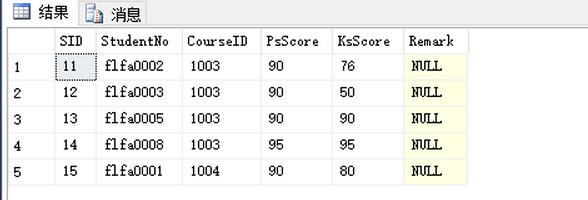
此方法是先取出前10條的SID(前兩頁),排除前10條數據的SID,然後在剩下的數據裡面取出前5條數據。
缺點就是它會遍歷表中所有數據兩次,數據量大時性能不好。
方法二:
select top 5 * from [StuDB].[dbo].[ScoreInfo] where [SID]> (select MAX(t.[SID]) from (select top 10 [SID] from [StuDB].[dbo].[ScoreInfo] order by [SID]) t ) order by [SID]
結果:
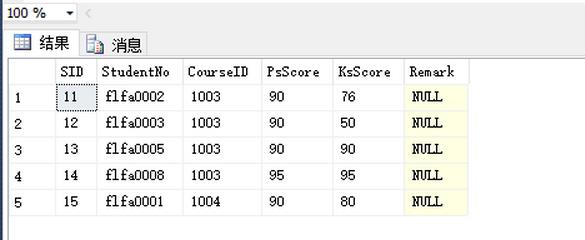
此方法是先取出前10條數據的SID,然後取出SID的最大值,再從數據裡面取出 大於 前10條SID的最大值 的前5條數據。
缺點是性能比較差,和方法一大同小異。
方法三:
select * from (select *,ROW_NUMBER() over(order by [SID]) ROW_ID from [StuDB].[dbo].[ScoreInfo]) t where t.[SID] between (5*(3-1)+1) and 5*3
結果:
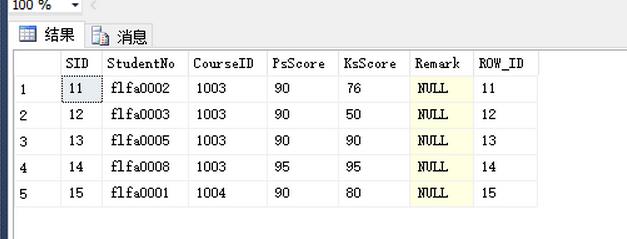
此方法的特點就是使用 ROW_NUMBER() 函數,這個方法性能比前兩種方法要好,只會遍歷一次所有的數據。適用於Sql Server 2000之後的版本(不含)。
方法四:
select * from [StuDB].[dbo].[ScoreInfo] order by [SID] offset 5*2 rows fetch next 5 rows only
結果:
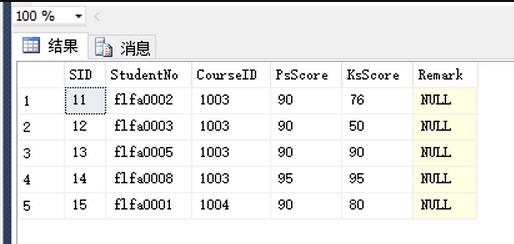
此方法適用於Sql Server 2008之後的版本(不含)。
offset 10 rows fetch next 5 rows only 這句代碼我的理解是:跳過前面10條數據(前2頁)從下一條開始取5條數據。
個人感覺這個方法比使用 ROW_NUMBER() 函數的方法要好(從代碼方面來看,代碼也少很多),至於性能方面沒有做過測試,就不說了。
不過,最後兩種方法的性能肯定是遠超前面兩種方法的,具體的還是看實用。
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持幫客之家。