SQL中經常遇到如下情況,在一張表中有兩條記錄基本完全一樣,某個或某幾個字段有些許差別,
這時候可能需要我們踢出這些有差別的數據,即兩條或多條記錄中只保留一項。
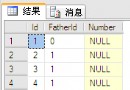
如下:表timeand
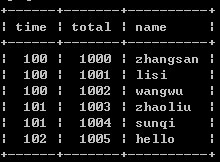
針對time字段相同時有不同total和name的情形,每當遇到相同的則只取其中一條數據,最簡單的實現方法有兩種
1、select time,max(total) as total,name from timeand group by time;//取記錄中total最大的值
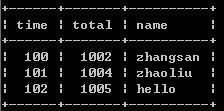
或 select time,min(total) as total,name from timeand group by time;//取記錄中total最小的值
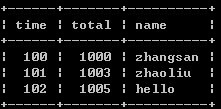
上述兩種方案都有個缺點,就是無法區分name字段的內容,所以一般用於只有兩條字段或其他字段內容完全一致的情況
2、select * from timeand as a where not exists(select 1 from timeand where a.time = time and a.total<total);
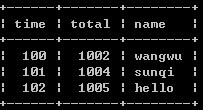
此中方案排除了方案1中name字段不准確的問題,取的是total最大的值
上面的例子中是只有一個字段不相同,假如有兩個字段出現相同呢?要求查處第三個字段的最大值該如何做呢?
其實很簡單,在原先的基礎上稍微做下修改即可:
原先的SQL語句:
select * from timeand as a where not exists(select 1 from timeand where a.time = time and a.total<total);
可修改為:
select * from timeand as a where not exists(select 1 from timeand where a.time = time and (a.total<total or (a.total=total and a.outtotal<outtotal)));
其中outtotal是另外一個字段,為Int類型
以上就是SQL中遇到多條相同內容只取一條的最簡單實現方法的全部內容,希望能給大家一個參考,也希望大家多多支持幫客之家。