有時候我們可能會把CSV中的數據導入到某個數據庫的表中,比如做報表分析的時候。
對於這個問題,我想一點也難不倒程序人員吧!但是要是SQL Server能夠完成這個任務,豈不是更好!
對,SQL Server確實有這個功能。
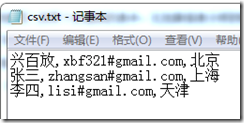
首先先讓我們看一下CSV文件,該文件保存在我的D:盤下,名為csv.txt,內容是:
現在就是SQL Server的關鍵部分了;
我們使用的是SQL Server的BULK INSERT命令,關於該命令的詳細解釋,請點擊此處;
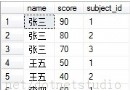
我們先在SQL Server中建立用於保存該信息的一張數據表,
CREATE TABLE CSVTable( Name NVARCHAR(MAX), Email NVARCHAR(MAX), Area NVARCHAR(MAX) )
然後執行下面的語句:
BULK INSERT CSVTable FROM 'D:\csv.txt' WITH( FIELDTERMINATOR = ',', ROWTERMINATOR = '\n' ) SELECT * FROM CSVTable
按F5,執行結果如下:
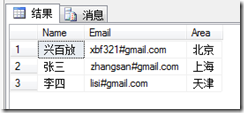
怎麼樣?是不是比用程序簡單!
但是現在有幾個問題需要考慮一下:
1,CSV文件中有的列值是用雙引號,有的列值則沒有雙引號:
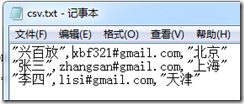
如果再次運行上面的語句,得到結果就和上一個結果不同了:
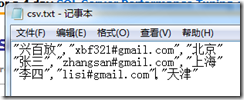
其中有的列就包含雙引號了,這應該不是我們想要的結果,要解決這個問題,我們只能利用臨時表了,先把CSV導入到臨時表中,然後在從這個臨時表中導入到最終表的過程中把雙引號去掉。
2,CSV文件的列值全部是由雙引號組成的:
這個問題要比上一個稍微復雜點,除了要先把CSV文件導入到臨時表中,還必須修改一下在把CSV文件導入到臨時表的代碼:

注意圈中的部分。
3,CSV文件的列要多於數據表的列:
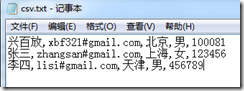
而我們的數據表只有三列,如果在執行上面的導入代碼,會產生什麼結果呢?
結果就是:
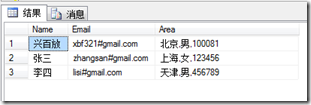
它把後邊的全部放在了Area列中了,要處理這個問題,其實也很簡單,就是我們把我們想要的列值在數據表中都按順序建立一列,而把不需要的列值,也在數據表中建立一個,只不過只是一個臨時列,在把這個數據表導入到最終表的時候,忽略這個臨時列就行了。