表值函數
SQL Server中提供了類似其他編程語言的函數,而函數的本質通常是一段代碼的封裝,並返回值。在SQL Server中,函數除了可以返回簡單的數據類型之外(Int、Varchar等),還可以返回一個集合,也就是返回一個表。
而根據是否直接返回集合或是定義後再返回集合,表值函數又分為內聯用戶定義表值函數和用戶定義表值函數(下文統稱為表值函數,省去“用戶定義”四個字)。
內聯表值函數
內聯表值函數和普通函數並無不同,唯一的區別是返回結果為集合(表),而不是簡單數據類型,一個簡單的內聯表值函數如代碼清單1所示(摘自MSDN)。
CREATE FUNCTION Sales.ufn_CustomerNamesInRegion ( @Region nvarchar(50) ) RETURNS table AS RETURN ( SELECT DISTINCT s.Name AS Store, a.City FROM Sales.Store AS s INNER JOIN Person.BusinessEntityAddress AS bea ON bea.BusinessEntityID = s.BusinessEntityID INNER JOIN Person.Address AS a ON a.AddressID = bea.AddressID INNER JOIN Person.StateProvince AS sp ON sp.StateProvinceID = a.StateProvinceID WHERE sp.Name = @Region ); GO
代碼清單1.一個簡單的表值函數
用戶定義表值函數
而用戶定義表值函數,需要在函數開始時定義返回的表結構,然後可以寫任何代碼進行數據操作,插入到定義的表結構之後進行返回,一個稍微負責的用戶定義表值函數示例如代碼清單2所示(摘自MSDN)。
CREATE FUNCTION dbo.ufnGetContactInformation(@ContactID int) RETURNS @retContactInformation TABLE ( -- Columns returned by the function ContactID int PRIMARY KEY NOT NULL, FirstName nvarchar(50) NULL, LastName nvarchar(50) NULL, JobTitle nvarchar(50) NULL, ContactType nvarchar(50) NULL ) AS -- Returns the first name, last name, job title, and contact type for the specified contact. BEGIN DECLARE @FirstName nvarchar(50), @LastName nvarchar(50), @JobTitle nvarchar(50), @ContactType nvarchar(50); -- Get common contact information SELECT @ContactID = BusinessEntityID, @FirstName = FirstName, @LastName = LastName FROM Person.Person WHERE BusinessEntityID = @ContactID; -- Get contact job title SELECT @JobTitle = CASE -- Check for employee WHEN EXISTS(SELECT * FROM Person.Person AS p WHERE p.BusinessEntityID = @ContactID AND p.PersonType = 'EM') THEN (SELECT JobTitle FROM HumanResources.Employee AS e WHERE e.BusinessEntityID = @ContactID) -- Check for vendor WHEN EXISTS(SELECT * FROM Person.Person AS p WHERE p.BusinessEntityID = @ContactID AND p.PersonType = 'VC') THEN (SELECT ct.Name FROM Person.ContactType AS ct INNER JOIN Person.BusinessEntityContact AS bec ON bec.ContactTypeID = ct.ContactTypeID WHERE bec.PersonID = @ContactID) -- Check for store WHEN EXISTS(SELECT * FROM Person.Person AS p WHERE p.BusinessEntityID = @ContactID AND p.PersonType = 'SC') THEN (SELECT ct.Name FROM Person.ContactType AS ct INNER JOIN Person.BusinessEntityContact AS bec ON bec.ContactTypeID = ct.ContactTypeID WHERE bec.PersonID = @ContactID) ELSE NULL END; -- Get contact type SET @ContactType = CASE -- Check for employee WHEN EXISTS(SELECT * FROM Person.Person AS p WHERE p.BusinessEntityID = @ContactID AND p.PersonType = 'EM') THEN 'Employee' -- Check for vendor WHEN EXISTS(SELECT * FROM Person.Person AS p WHERE p.BusinessEntityID = @ContactID AND p.PersonType = 'VC') THEN 'Vendor Contact' -- Check for store WHEN EXISTS(SELECT * FROM Person.Person AS p WHERE p.BusinessEntityID = @ContactID AND p.PersonType = 'SC') THEN 'Store Contact' -- Check for individual consumer WHEN EXISTS(SELECT * FROM Person.Person AS p WHERE p.BusinessEntityID = @ContactID AND p.PersonType = 'IN') THEN 'Consumer' -- Check for general contact WHEN EXISTS(SELECT * FROM Person.Person AS p WHERE p.BusinessEntityID = @ContactID AND p.PersonType = 'GC') THEN 'General Contact' END; -- Return the information to the caller IF @ContactID IS NOT NULL BEGIN INSERT @retContactInformation SELECT @ContactID, @FirstName, @LastName, @JobTitle, @ContactType; END; RETURN; END; GO
代碼訂單2.表值函數
為什麼要用表值函數
看起來表值函數所做的事情和存儲過程並無不同,但實際上還是有所差別。是因為表值函數可以被用於寫入其他查詢,而存儲過程不行。此外,表值函數和Apply操作符聯合使用可以極大的簡化連接操作。
如果存儲過程符合下述條件的其中一個,可以考慮重寫為表值函數。
•存儲過程邏輯非常簡單,僅僅是一個Select語句,不用視圖的原因僅僅是由於需要參數。
•存儲過程中沒有更新操作。
•存儲過程中沒有動態SQL。
•存儲過程中只返回一個結果集。
•存儲過程的主要目的是為了產生臨時結果集,並將結果集存入臨時表以供其他查詢調用。
用戶定義表值函數的問題
表值函數與內聯表值函數不同,內聯表值函數在處理的過程中更像是一個視圖,這意味著在查詢優化階段,內聯表值函數可以參與查詢優化器的優化,比如將篩選條件(Where)推到代數樹的底部,這意味著可以先Where再Join,從而可以利用索引查找降低IO從而提升性能。
讓我們來看一個簡單的例子。下面代碼示例是一個簡單的和表值函數做Join的例子:
首先我們創建表值函數,分別為內聯表值函數方式和表值函數方式,如代碼清單3所示。
--創建表值行數 CREATE FUNCTION tvf_multi_Test ( ) RETURNS @SaleDetail TABLE ( ProductId INT ) AS BEGIN INSERT INTO @SaleDetail SELECT ProductID FROM Sales.SalesOrderHeader soh INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID RETURN END --創建內聯表值函數 CREATE FUNCTION tvf_inline_Test ( ) RETURNS TABLE AS RETURN SELECT ProductID FROM Sales.SalesOrderHeader soh INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
代碼清單3.創建兩種不同的函數
現在,我們使用相同的查詢,對這兩個表值函數進行Join,代碼如代碼清單4所示。
--表值函數做Join SELECT c.personid , Prod.Name , COUNT(*) 'numer of unit' FROM Person.BusinessEntityContact c INNER JOIN dbo.tvf_multi_Test() tst ON c.personid = tst.ProductId INNER JOIN Production.Product prod ON tst.ProductId = prod.ProductID GROUP BY c.personid , Prod.Name --內聯表值函數做Join SELECT c.personid , Prod.Name , COUNT(*) 'numer of unit' FROM Person.BusinessEntityContact c INNER JOIN dbo.tvf_inline_Test() tst ON c.personid = tst.ProductId INNER JOIN Production.Product prod ON tst.ProductId = prod.ProductID GROUP BY c.personid , Prod.Name
代碼清單4.表值函數和內聯表值函數做Join
執行的成本如圖1所示。

圖1.兩種方式的成本
從IO來看,很明顯是選擇了次優的執行計劃,BusinessEntityContact選擇了121317次查找,而不是一次掃描。而內聯表函數能夠正確知道掃描一次的成本遠低於一次查找。
那問題的根源是內聯表值函數,對於SQL Server來說,和視圖是一樣的,這意味著內聯表值函數可以參與到邏輯執行計劃的代數運算(或者是代數樹優化)中,這意味著內斂表可以進一步拆分(如圖1所示,第二個內聯表的查詢,執行計劃具體知道內斂表中是SalesOrderHeader表和SalesOrderDetail表,由於查詢只選擇了一列,所以執行計劃優化直到可以無需掃描SalesOrderHeader表),對於內聯表值函數來說,執行計劃可以完整知道所涉及的表上的索引以及相關統計信息等元數據。
另一方面,表值函數,如圖1的第一部分所示,表值函數對整個執行計劃來說是一個黑箱子,既不知道統計信息,也沒有索引。執行計劃中不知道表值函數所涉及的表(圖1中為#AE4E5168這個臨時表,而不是具體的表明),因此對整個執行計劃來說該結果集SQL Server會假設返回的結果非常小,當表值函數返回的結果較多時(如本例所示),則會產生比較差的執行計劃。
因此綜上所述,在表值函數返回結果極小時,對性能可能沒有影響,但返回結果如果略多,則一定會影響執行計劃的質量。
如何處理
首先,在SQL Server中,我們要找出現存的和表值函數做Join的語句,通過挖掘執行計劃,我們可以找出該類語句,使用的代碼如代碼清單5所示。
WITH XMLNAMESPACES('http://schemas.microsoft.com/sqlserver/2004/07/showplan' AS p)
SELECT st.text,
qp.query_plan
FROM (
SELECT TOP 50 *
FROM sys.dm_exec_query_stats
ORDER BY total_worker_time DESC
) AS qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) AS st
CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) AS qp
WHERE qp.query_plan.exist('//p:RelOp[contains(@LogicalOp, "Join")]/*/p:RelOp[(@LogicalOp[.="Table-valued function"])]') = 1
代碼清單5.從執行計劃緩存中找出和表值函數做Join的查詢
結果如圖2所示。
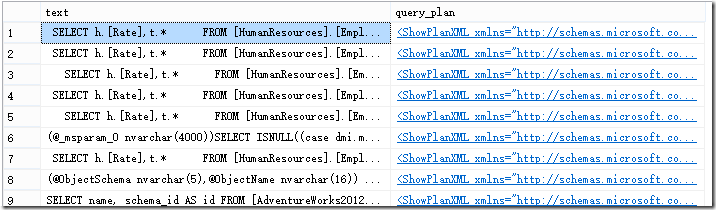
圖2.執行計劃緩存中已經存在的和表值函數做Join的查詢
小結
本文闡述了表值函數的概念,表值函數為何會影響性能以及在執行計劃緩存中找出和表值函數做Join的查詢。對於和表值函數做Apply或表值函數返回的行數非常小的查詢,或許並不影響。但對於返回結果較多的表值函數做Join,則可能產生性能問題,因此如果有可能,把表值函數重寫為內聯表值函數或將表值函數的結果存入臨時表再進行Join可提升性能。
參考資料:
http://www.brentozar.com/blitzcache/tvf-join/
http://blogs.msdn.com/b/psssql/archive/2010/10/28/query-performance-and-multi-statement-table-valued-functions.aspx?CommentPosted=true#commentmessage