在日常應用中,往往根據實際需求錄入一些值,而這些值不能直接使用,所以Sql中經常會對字段值進行一些常規的處理。這裡搜集了(提取數字、英文、中文、過濾重復字符、分割字符的方法),方便日後查詢使用。
一、判斷字段值是否有中文
復制代碼 代碼如下:
--SQL 判斷字段值是否有中文
create function fun_getCN(@str nvarchar(4000))
returns nvarchar(4000)
as
begin
declare @word nchar(1),@CN nvarchar(4000)
set @CN=''
while len(@str)>0
begin
set @word=left(@str,1)
if unicode(@word) between 19968 and 19968+20901
set @CN=@CN+@word
set @str=right(@str,len(@str)-1)
end
return @CN
end
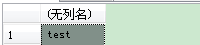
select dbo.fun_getCN('ASDKG論壇KDL')
--論壇
select dbo.fun_getCN('ASDKG論壇KDL')
--論壇
select dbo.fun_getCN('ASDKDL')
--空
二、提取數字
復制代碼 代碼如下:
IF OBJECT_ID('DBO.GET_NUMBER2') IS NOT NULL
DROP FUNCTION DBO.GET_NUMBER2
GO
CREATE FUNCTION DBO.GET_NUMBER2(@S VARCHAR(100))
RETURNS VARCHAR(100)
AS
BEGIN
WHILE PATINDEX('%[^0-9]%',@S) > 0
BEGIN
set @s=stuff(@s,patindex('%[^0-9]%',@s),1,'')
END
RETURN @S
END
GO
--測試
PRINT DBO.GET_NUMBER('呵呵ABC123ABC')
GO
--123
三、提取英文
復制代碼 代碼如下:
--提取英文
IF OBJECT_ID('DBO.GET_STR') IS NOT NULL
DROP FUNCTION DBO.GET_STR
GO
CREATE FUNCTION DBO.GET_STR(@S VARCHAR(100))
RETURNS VARCHAR(100)
AS
BEGIN
WHILE PATINDEX('%[^a-z]%',@S) > 0
BEGIN
set @s=stuff(@s,patindex('%[^a-z]%',@s),1,'')
END
RETURN @S
END
GO
--測試
PRINT DBO.GET_STR('呵呵ABC123ABC')
GO
四、提取中文
復制代碼 代碼如下:
--提取中文
IF OBJECT_ID('DBO.CHINA_STR') IS NOT NULL
DROP FUNCTION DBO.CHINA_STR
GO
CREATE FUNCTION DBO.CHINA_STR(@S NVARCHAR(100))
RETURNS VARCHAR(100)
AS
BEGIN
WHILE PATINDEX('%[^吖-座]%',@S) > 0
SET @S = STUFF(@S,PATINDEX('%[^吖-座]%',@S),1,N'')
RETURN @S
END
GO
PRINT DBO.CHINA_STR('呵呵ABC123ABC')
GO
五、過濾重復字段(多種方法)
復制代碼 代碼如下:
--過濾重復字符
IF OBJECT_ID('DBO.DISTINCT_STR') IS NOT NULL
DROP FUNCTION DBO.DISTINCT_STR
GO
CREATE FUNCTION DBO.DISTINCT_STR(@S NVARCHAR(100),@SPLIT VARCHAR(50))
RETURNS VARCHAR(100)
AS
BEGIN
IF @S IS NULL RETURN(NULL)
DECLARE @NEW VARCHAR(50),@INDEX INT,@TEMP VARCHAR(50)
IF LEFT(@S,1)<>@SPLIT
SET @S = @SPLIT+@S
IF RIGHT(@S,1)<>@SPLIT
SET @S = @S+@SPLIT
WHILE CHARINDEX(@SPLIT,@S)>0 AND LEN(@S)<>1
BEGIN
SET @INDEX = CHARINDEX(@SPLIT,@S)
SET @TEMP = LEFT(@S,CHARINDEX(@SPLIT,@S,@INDEX+LEN(@SPLIT)))
IF @NEW IS NULL
SET @NEW = ISNULL(@NEW,'')+@TEMP
ELSE
SET @NEW = ISNULL(@NEW,'')+REPLACE(@TEMP,@SPLIT,'')+@SPLIT
WHILE CHARINDEX(@TEMP,@S)>0
BEGIN
SET @S=STUFF(@S,CHARINDEX(@TEMP,@S)+LEN(@SPLIT),CHARINDEX(@SPLIT,@S,CHARINDEX(@TEMP,@S)+LEN(@SPLIT))-CHARINDEX(@TEMP,@S),'')
END
END
RETURN RIGHT(LEFT(@NEW,LEN(@NEW)-1),LEN(LEFT(@NEW,LEN(@NEW)-1))-1)
END
GO
PRINT DBO.DISTINCT_STR('A,A,B,C,C,B,C,',',')
--A,B,C
GO
--------------------------------------------------------------------
--過濾重復字符2
IF OBJECT_ID('DBO.DISTINCT_STR2') IS NOT NULL
DROP FUNCTION DBO.DISTINCT_STR2
GO
CREATE FUNCTION DBO.DISTINCT_STR2(@S varchar(8000))
RETURNS VARCHAR(100)
AS
BEGIN
IF @S IS NULL RETURN(NULL)
DECLARE @NEW VARCHAR(50),@INDEX INT,@TEMP VARCHAR(50)
WHILE LEN(@S)>0
BEGIN
SET @NEW=ISNULL(@NEW,'')+LEFT(@S,1)
SET @S=REPLACE(@S,LEFT(@S,1),'')
END
RETURN @NEW
END
GO
SELECT DBO.DISTINCT_STR2('AABCCD')
--ABCD
GO
六、根據特定字符串分割字段值
復制代碼 代碼如下:
IF OBJECT_ID('DBO.SPLIT_STR') IS NOT NULL
DROP FUNCTION DBO.SPLIT_STR
GO
CREATE FUNCTION DBO.SPLIT_STR(
@S varchar(8000), --包含多個數據項的字符串
@INDEX int, --要獲取的數據項的位置
@SPLIT varchar(10) --數據分隔符
)
RETURNS VARCHAR(100)
AS
BEGIN
IF @S IS NULL RETURN(NULL)
DECLARE @SPLITLEN int
SELECT @SPLITLEN=LEN(@SPLIT+'A')-2
WHILE @INDEX>1 AND CHARINDEX(@SPLIT,@S+@SPLIT)>0
SELECT @INDEX=@INDEX-1,@S=STUFF(@S,1,CHARINDEX(@SPLIT,@S+@SPLIT)+@SPLITLEN,'')
RETURN(ISNULL(LEFT(@S,CHARINDEX(@SPLIT,@S+@SPLIT)-1),''))
END
GO
PRINT DBO.SPLIT_STR('AA|BB|CC',2,'|')
--
GO
創建自定義函數:
use 數據庫名
go
create function 函數名
(@pno int)
returns int
as
begin
declare @a int
if not exists(select * from person where pno=@pno)
set @a=-1
else
set @a=1
return @a
end
調用函數:
use 數據庫名
go
select dbo.函數名(13250)
SQL Server 中,函數只能使用簡單的sql語句,邏輯控制語句,復雜一點的存儲過程是不能調用的,在函數裡也不能使用execute sp_executesql 或者execute 。
要不, 你就創建個 有 2個 OUTPUT 參數的存儲過程 ?