簡介
SQL Server 2014提供了眾多激動人心的新功能,但其中我想最讓人期待的特性之一就要算內存數據庫了。去年我再西雅圖參加SQL PASS Summit 2012的開幕式時,微軟就宣布了將在下一個SQL Server版本中附帶代號為Hekaton的內存數據庫引擎。現在隨著2014CTP1的到來,我們終於可以一窺其面貌。
內存數據庫
在傳統的數據庫表中,由於磁盤的物理結構限制,表和索引的結構為B-Tree,這就使得該類索引在大並發的OLTP環境中顯得非常乏力,雖然有很多辦法來解決這類問題,比如說樂觀並發控制,應用程序緩存,分布式等。但成本依然會略高。而隨著這些年硬件的發展,現在服務器擁有幾百G內存並不罕見,此外由於NUMA架構的成熟,也消除了多CPU訪問內存的瓶頸問題,因此內存數據庫得以出現。
內存的學名叫做Random Access Memory(RAM),因此如其特性一樣,是隨機訪問的,因此對於內存,對應的數據結構也會是Hash-Index,而並發的隔離方式也對應的變成了MVCC,因此內存數據庫可以在同樣的硬件資源下,Handle更多的並發和請求,並且不會被鎖阻塞,而SQL Server 2014集成了這個強大的功能,並不像Oracle的TimesTen需要額外付費,因此結合SSD AS Buffer Pool特性,所產生的效果將會非常值得期待。
SQL Server內存數據庫的表現形式
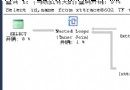
在SQL Server的Hekaton引擎由兩部分組成:內存優化表和本地編譯存儲過程。雖然Hekaton集成進了關系數據庫引擎,但訪問他們的方法對於客戶端是透明的,這也意味著從客戶端應用程序的角度來看,並不會知道Hekaton引擎的存在。如圖1所示。

圖1.客戶端APP不會感知Hekaton引擎的存在
首先內存優化表完全不會再存在鎖的概念(雖然之前的版本有快照隔離這個樂觀並發控制的概念,但快照隔離仍然需要在修改數據的時候加鎖),此外內存優化表Hash-Index結構使得隨機讀寫的速度大大提高,另外內存優化表可以設置為非持久內存優化表,從而也就沒有了日志(適合於ETL中間結果操作,但存在數據丟失的危險)
下面我們來看創建一個內存優化表:
首先,內存優化表需要數據庫中存在一個特殊的文件組,以供存儲內存優化表的CheckPoint文件,與傳統的mdf或ldf文件不同的是,該文件組是一個目錄而不是一個文件,因為CheckPoint文件只會附加,而不會修改,如圖2所示。

圖2.內存優化表所需的特殊文件組
我們再來看一下內存優化文件組的樣子,如圖3所示。

圖3.內存優化文件組
有了文件組之後,接下來我們創建一個內存優化表,如圖4所示。

圖4.創建內存優化表
目前SSMS還不支持UI界面創建內存優化表,因此只能通過T-SQL來創建內存優化表,如圖5所示。

圖5.使用代碼創建內存優化表
當表創建好之後,就可以查詢數據了,值得注意的是,查詢內存優化表需要snapshot隔離等級或者hint,這個隔離等級與快照隔離是不同的,如圖6所示。

圖6.查詢內存優化表需要加提示
此外,由創建表的語句可以看出,目前SQL Server 2014內存優化表的Hash Index只支持固定的Bucket大小,不支持動態分配Bucket大小,因此這裡需要注意。
與內存數據庫不兼容的特性
目前來說,數據庫鏡像和復制是無法與內存優化表兼容的,但AlwaysOn,日志傳送,備份還原是完整支持。
性能測試
上面扯了一堆理論,大家可能都看郁悶了。下面我來做一個簡單的性能測試,來比對使用內存優化表+本地編譯存儲過程與傳統的B-Tree表進行對比,B-Tree表如圖7所示,內存優化表+本地編譯存儲過程如圖8所示。

圖7.傳統的B-Tree表

圖8.內存優化表+本地編譯存儲過程
因此不難看出,內存優化表+本地編譯存儲過程有接近幾十倍的性能提升。
相對於磁盤,內存的數據讀寫速度要高出幾個數量級,將數據保存在內存中相比從磁盤上訪問能夠極大地提高應用的性能。同時,內存數據庫拋棄了磁盤數據管理的傳統方式,基於全部數據都在內存中重新設計了體系結構,並且在數據緩存、快速算法、並行操作方面也進行了相應的改進,所以數據處理速度比傳統數據庫的數據處理速度要快很多,一般都在10倍以上。內存數據庫的最大特點是其"主拷貝"或"工作版本" 常駐內存,即活動事務只與實時內存數據庫的內存拷貝打交道。顯然,它要求較大的內存量,但並非任何時刻整個數據庫都存放在內存,即內存數據庫系統還是要處理I/O。
內存數據庫是以犧牲內存資源為代價換取數據處理實時性的,內存數據庫和磁盤數據庫都是當今信息社會裡每個企業所必須的關系型數據庫產品,磁盤數據庫解決的是大容量存儲和數據分析問題,而內存數據庫解決的是實時處理和高並發問題。兩者的存在是相輔相成的,內存數據庫的事務實時處理性能要遠強於磁盤數據庫。但是相對的,他的數據安全方面還沒有達到磁盤數據庫比肩的地步。
內存數據庫將物理內存作為數據的第一存儲介質,而將磁盤作為備份。隨著電信業務的發展,系統對實時性的要求和對業務靈活修改的要求非常高,在此種情況下對於內存數據庫的需求也越來越高。磁盤數據庫的做法是將數據存入內存中進行處理,這種方式的可管理性及數據安全可靠性都沒有保障。而內存數據庫正是針對這一弱點進行了改進。
實際上,內存數據庫並不是一項時髦技術,其出現於上世紀60年代末,但由於市場的需求原因在90年代後期才開始發展。作為新一代數據庫,Altibase產品已經走向混合型數據庫,其版本Altibase 4.0已經有一套自帶的磁盤數據庫,用戶一旦購買了Altibase的內存數據庫,就無須再購買磁盤數據庫。它把熱數據(經常被使用的、訪問比較高的、經常要運算的數據)放在內存數據庫裡,而把歷史性數據放在磁盤數據庫裡,可為用戶進一步減少投資。
對於內存數據庫而言,可以將同樣數據庫的部分內容存放於磁盤上,而另一部分存放於內存中。用戶可以選擇將數據存儲在內存表中以提供即時的數據訪問。若訪問時間不緊急或數據存於內存中所占空間過大時,用戶可將這些數據存入磁盤表中。
比如,在手機用戶開始拔打電話時,如果應用基於內存數據庫技術的混合數據管理引擎,就通過內存表檢索其服務選項並立即驗證用戶身份,而將通話清單和計費清單歸檔到磁盤表中。從而,達到了速度與資源使用的平衡。
內存數據庫的技術,一個很重要的特點,是可以對內存中的數據實現全事務處理,這是僅僅把數據以數組等形式放在內存中完全不同的。並且,內存數據庫是與應用無關的,顯然這種體系結構具有其合理性。內存引擎可以實現查詢與存檔功能使用的是完全相同的數據庫,同時內存表與磁盤表也使用的是完全相同的存取方法。存儲的選擇,對於應用開發者而言是完全透明的。
對於內存數據庫而言,實現了數據在內存中的管理,而不僅僅是作為數據庫的緩存。不像其它將磁盤數據塊緩存到主存中的數據庫,內存數據庫的內存引擎使用了為隨機訪問內存而特別設計的數據結構和算法,這種設計使其避免了因使用排序命令而經常破壞緩存數據庫性能的問題。通過內存數據庫,減少了磁盤I/O,能夠達到了以磁盤I/O 為主的傳統數據庫無法與其相比擬的處理速度。
因此,內存數據庫技術的應用,可以大大提高數據庫的速度,這對於需要高速反應的數據庫應用,如電信、金融等提供了有力支撐。
由於把大多數數據都放在內存中進行操作,使得內存數據庫有著比磁盤數據庫高得多的性能表現,這一......余下全文>>
可信任的和可擴展的平台
線業務應用程式(LOB),是IT部門和商務部門的關鍵環節業務。能夠安全可靠的存儲,集中,管理和分配數據到用戶的關鍵是這些LOB應用程序。 SQL Server 2008提供了一個高性能的數據庫平台,一個可靠、可擴展的企業平台,且易於管理。 SQL Server 2008 R2將幫助IT部門提供了當今最先進的且熟悉的SQL Server管理工具平台,更符合成本效益的可擴展性。
利用硬件創新
SQL Server 2008的R2幫助您利用最新的硬件技術的優勢,能夠實現最大限度降低總擁有成本。微軟Windows Server 2008 R2和SQL Server 2008的R2的協同工作,使客戶能夠擴展到多達256個邏輯處理器。
此外,支持Hyper – V技術的Windows Server 2008中需要更大的處理能力以及充分利用全新的多核心系統的優勢。這意味著每個物理主機對多個虛擬系統的支持,會降低成本,同時提高了可擴展性和虛擬基礎架構的靈活性。新的Hyper – V技術的實時遷移允許兩個主機之間遷移服務器,並且不會中斷任何服務。
IT及開發效益
使管理員能夠集中監控和管理多個數據庫應用,實例或服務器,加快開發和應用的部署和提供更好的支持,通過支持Hyper- V功能的Windows Server 2008 R2實現在線遷移。
管理自我服務的商務智能
擴展功能強大的BI工具為所有Excel與SQL Server PowerPivot用戶和授權用戶的商業類新的積累和分享功能強大的商務智能解決方案,同時還使IT監控和管理用戶所生成的BI解決方案。