In與Exists這兩個函數是差不多的,但由於優化方案不同,通常NOT Exists要比NOT IN要快,因為NOT EXISTS可以使用結合算法二NOT IN就不行了,而EXISTS則不如IN快,因為這時候IN可能更多的使用結合算法。
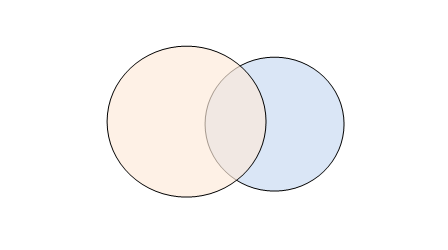
如圖,現在有兩個數據集,左邊表示#tempTable1,右邊表示#tempTable2。現在有以下問題:
1.求兩個集的交集?
2.求tempTable1中不屬於集#tempTable2的集?
先創建兩張臨時表:
create table #tempTable1
(
argument1 nvarchar(50),
argument2 varchar(20),
argument3 datetime,
argument4 int
);
insert into #tempTable1(argument1,argument2,argument3,argument4)
values('preacher001','13023218757',GETDATE()-1,1);
insert into #tempTable1(argument1,argument2,argument3,argument4)
values('preacher002','23218757',GETDATE()-2,2);
insert into #tempTable1(argument1,argument2,argument3,argument4)
values('preacher003','13018757',GETDATE()-3,3);
insert into #tempTable1(argument1,argument2,argument3,argument4)
values('preacher004','13023257',GETDATE()-4,4);
insert into #tempTable1(argument1,argument2,argument3,argument4)
values('preacher005','13023218',GETDATE()-5,5);
insert into #tempTable1(argument1,argument2,argument3,argument4)
values('preacher006','13023218',GETDATE()-6,6);
insert into #tempTable1(argument1,argument2,argument3,argument4)
values('preacher007','13023218',GETDATE()-7,7);
insert into #tempTable1(argument1,argument2,argument3,argument4)
values('preacher008','13023218',GETDATE()-8,8);
create table #tempTable2
(
argument1 nvarchar(50),
argument2 varchar(20),
argument3 datetime,
argument4 int
);
insert into #tempTable2(argument1,argument2,argument3,argument4)
values('preacher001','13023218757',GETDATE()-1,1);
insert into #tempTable2(argument1,argument2,argument3,argument4)
values('preacher0010','23218757',GETDATE()-10,10);
insert into #tempTable2(argument1,argument2,argument3,argument4)
values('preacher003','13018757',GETDATE()-3,3);
insert into #tempTable2(argument1,argument2,argument3,argument4)
values('preacher004','13023257',GETDATE()-4,4);
insert into #tempTable2(argument1,argument2,argument3,argument4)
values('preacher009','13023218',GETDATE()-9,9);
比如,我現在以#tempTable1和#tempTable2的argument1作為參照
1.求兩集的交集:
1)in 方式
select * from #tempTable2 where argument1 in (select argument1 from #tempTable1)
2)exists 方式
select * from #tempTable2 t2 where exists (select * from #tempTable1 t1 where t1.argument1=t2.argument1)
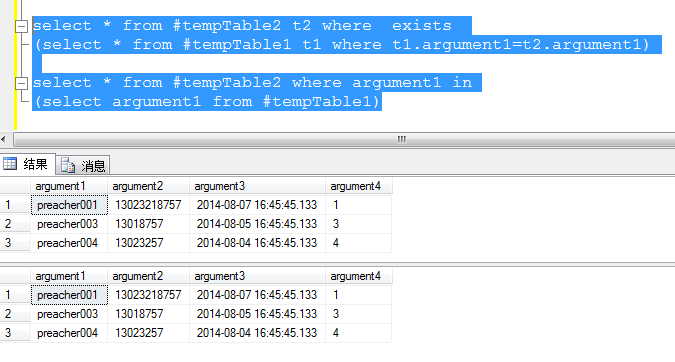
2.求tempTable1中不屬於集#tempTable2的集
1)in 方式
select * from #tempTable1 where argument1 not in (select argument1 from #tempTable2)
2)exists 方式
select * from #tempTable1 t1 where not exists (select * from #tempTable2 t2 where t1.argument1=t2.argument1)
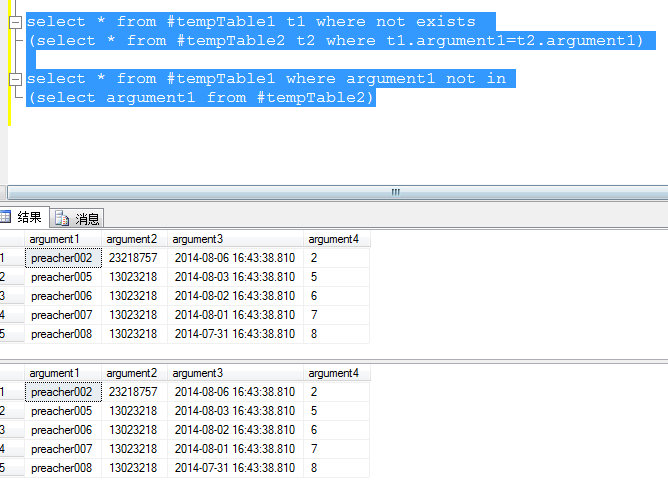
IN 其實與等於相似,比如in(1,2) 就是 = 1 or = 2的一種簡單寫法,所以一般在元素少的時候使用IN,如果多的話就用exists
exists的用法跟in不一樣,一般都需要和子表進行關聯,而且關聯時,需要用索引,這樣就可以加快速度。
你的SQL語句用NOT EXISTS可以寫成
select MC001 from BOMMC WHERE NOT EXISTS (SELECT MD001 FROM BOMMD where BOMMC.MC001 = BOMMD.MD001)
in 和 exists主要區別就是對null處理
如果沒有null值,in 和 exists是等同的。如果不等同,說明查詢的內容裡有null值。
請仔細分析下面四個例子就知道了。
select 1
where 2 in (1,null)
select 1
where 2 not in (1,null)
select 1
where exists(select null)
select 1
where not exists(select null)