數據庫優化包含以下三部分,數據庫自身的優化,數據庫表優化,程序操作優化.此文為第二部分
優化①:設計規范化表,消除數據冗余
數據庫范式是確保數據庫結構合理,滿足各種查詢需要、避免數據庫操作異常的數據庫設計方式。滿足范式要求的表,稱為規范化表,范式產生於20世紀70年代初,一般表設計滿足前三范式就可以,在這裡簡單介紹一下前三范式
先給大家看一下百度百科給出的定義:
第一范式(1NF)無重復的列
所謂第一范式(1NF)是指在關系模型中,對域添加的一個規范要求,所有的域都應該是原子性的,即數據庫表的每一列都是不可分割的原子數據項,而不能是集合,數組,記錄等非原子數據項。
第二范式(2NF)屬性
在1NF的基礎上,非碼屬性必須完全依賴於碼[在1NF基礎上消除非主屬性對主碼的部分函數依賴]
第三范式(3NF)屬性
在1NF基礎上,任何非主屬性不依賴於其它非主屬性[在2NF基礎上消除傳遞依賴]
通俗的給大家解釋一下(可能不是最科學、最准確的理解)
第一范式:屬性(字段)的原子性約束,要求屬性具有原子性,不可再分割;
第二范式:記錄的惟一性約束,要求記錄有惟一標識,每條記錄需要有一個屬性來做為實體的唯一標識。
第三范式:屬性(字段)冗余性的約束,即任何字段不能由其他字段派生出來,在通俗點就是:主鍵沒有直接關系的數據列必須消除(消除的辦法就是再創建一個表來存放他們,當然外鍵除外)
如果數據庫設計達到了完全的標准化,則把所有的表通過關鍵字連接在一起時,不會出現任何數據的復本(repetition)。標准化的優點是明顯的,它避免了數據冗余,自然就節省了空間,也對數據的一致性(consistency)提供了根本的保障,杜絕了數據不一致的現象,同時也提高了效率。
優化②:適當的冗余,增加計算列
數據庫設計的實用原則是:在數據冗余和處理速度之間找到合適的平衡點
滿足范式的表一定是規范化的表,但不一定是最佳的設計。很多情況下會為了提高數據庫的運行效率,常常需要降低范式標准:適當增加冗余,達到以空間換時間的目的。比如我們有一個表,產品名稱,單價,庫存量,總價值。這個表是不滿足第三范式的,因為“總價值”可以由“單價”乘以“數量”得到,說明“金額”是冗余字段。但是,增加“總價值”這個冗余字段,可以提高查詢統計的速度,這就是以空間換時間的作法。合理的冗余可以分散數據量大的表的並發壓力,也可以加快特殊查詢的速度,冗余字段可以有效減少數據庫表的連接,提高效率。
其中"總價值"就是一個計算列,在數據庫中有兩種類型:數據列和計算列,數據列就是需要我們手動或者程序給予賦值的列,計算列是源於表中其他的數據計算得來,比如這裡的"總價值"
在SQL中創建計算列:
復制代碼 代碼如下:
create table table1
(
number decimal(18,4),
price money,
Amount as number*price --這裡就是計算列
)
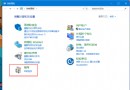
也可以再表設計中,直接手動添加或修改列屬性即可:如下圖 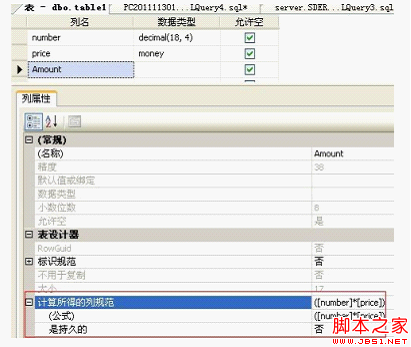
是否持久性,我們也需要注意:
如果是'否',說明這列是虛擬列,每次查詢的時候計算一次,而且那麼它是不可以用來做check,foreign key或not null約束。
如果是'是',就是真實的列,不需要每次都計算,可以再此列上創建索引等等。
優化③:索引
索引是一個表優化的重要指標,在表優化中占有極其重要的成分,所以將單獨寫一章”SQL索引一步到位“去告訴大家如何建立和優化索引
優化④:主鍵和外鍵的必要性
主鍵與外鍵的設計,在全局數據庫的設計中,占有重要地位。 因為:主鍵是實體的抽象,主鍵與外鍵的配對,表示實體之間的連接。
主鍵:根據第二范式,需要有一個字段去標識這條記錄,主鍵無疑是最好的標識,但是很多表也不一定需要主鍵,但是對於數據量大,查詢頻繁的數據庫表,一定要有主鍵,主鍵可以增加效率、防止重復等優點。
主鍵的選擇也比較重要,一般選擇總的長度小的鍵,小的鍵的比較速度快,同時小的鍵可以使主鍵的B樹結構的層次更少。
主鍵的選擇還要注意組合主鍵的字段次序,對於組合主鍵來說,不同的字段次序的主鍵的性能差別可能會很大,一般應該選擇重復率低、單獨或者組合查詢可能性大的字段放在前面。
外鍵:外鍵作為數據庫對象,很多人認為麻煩而不用,實際上,外鍵在大部分情況下是很有用的,理由是:外鍵是最高效的一致性維護方法
數據庫的一致性要求,依次可以用外鍵、CHECK約束、規則約束、觸發器、客戶端程序,一般認為,離數據越近的方法效率越高。
謹慎使用級聯刪除和級聯更新,級聯刪除和級聯更新作為SQL SERVER 2000當年的新功能,在2005作了保留,應該有其可用之處。我這裡說的謹慎,是因為級聯刪除和級聯更新有些突破了傳統的關於外鍵的定義,功能有點太過強大,使用前必須確定自己已經把握好其功能范圍,否則,級聯刪除和級聯更新可能讓你的數據莫名其妙的被修改或者丟失。從性能看級聯刪除和級聯更新是比其他方法更高效的方法。
優化⑤:存儲過程、視圖、函數的適當使用
很多人習慣將復雜操作都放在應用程序層,但如果你要優化數據訪問性能,將SQL代碼移植到數據庫上(使用存儲過程,視圖,函數和觸發器)也是一個很大的改進原因如下:
1. 存儲過程減少了網絡傳輸、處理及存儲的工作量,且經過編譯和優化,執行速度快,易於維護,且表的結構改變時,不影響客戶端的應用程序
2、使用存儲過程,視圖,函數有助於減少應用程序中SQL復制的弊端,因為現在只在一個地方集中處理SQL
3、使用數據庫對象實現所有的TSQL有助於分析TSQL的性能問題,同時有助於你集中管理TSQL代碼,更好的重構TSQL代碼
優化⑥:傳說中的‘三少原則'
①:數據庫的表越少越好
②:表的字段越少越好
③:字段中的組合主鍵、組合索引越少越好
當然這裡的少是相對的,是減少數據冗余的重要設計理念。
優化⑦:分割你的表,減小表尺寸
如果你發現某個表的記錄太多,例如超過一千萬條,則要對該表進行水平分割。水平分割的做法是,以該表主鍵的某個值為界線,將該表的記錄水平分割為兩個表。
如果你若發現某個表的字段太多,例如超過八十個,則垂直分割該表,將原來的一個表分解為兩個表
優化⑧:字段設計原則
字段是數據庫最基本的單位,其設計對性能的影響是很大的。需要注意如下:
A、數據類型盡量用數字型,數字型的比較比字符型的快很多。
B、 數據類型盡量小,這裡的盡量小是指在滿足可以預見的未來需求的前提下的。
C、 盡量不要允許NULL,除非必要,可以用NOT NULL+DEFAULT代替。
D、少用TEXT和IMAGE,二進制字段的讀寫是比較慢的,而且,讀取的方法也不多,大部分情況下最好不用。
E、 自增字段要慎用,不利於數據遷移