先來看看什麼是書簽查找:
當優化器所選擇的非聚簇索引只包含查詢請求的一部分字段時,就需要一個查找(lookup)來檢索其他字段來滿足請求。對一個有聚簇索引的表來說是一個鍵查找(key lookup),對一個堆表來說是一個RID查找(RID lookup)。這種查找即是——書簽查找。
書簽查找根據索引的行定位器從表中讀取數據。因此,除了索引頁面的邏輯讀取外,還需要數據頁面的邏輯讀取。
從索引的行定位器到從表中讀取數據這之間會產生一些額外的開銷,本文就來解決這個開銷。
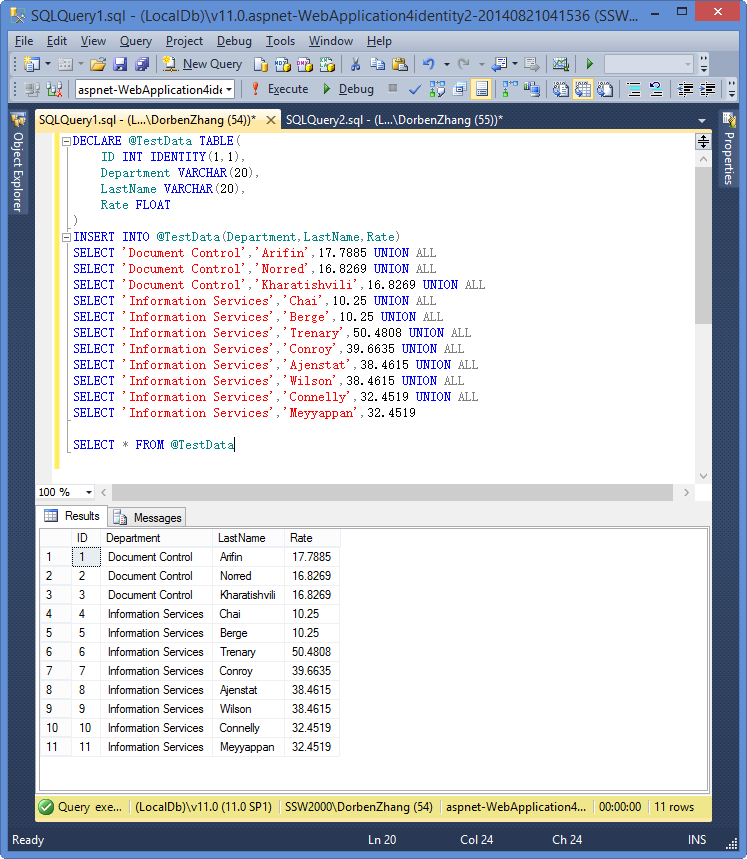
先看下我的測試表結構: 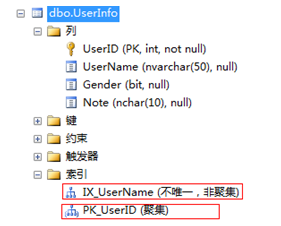
其中可以看出 有一個 聚簇索引 PK_UserID 和一個 非聚簇索引IX_UserName。
看看產生書簽 查找的效果:
select UserName,Gender from dbo.UserInfo where UserName='userN600'
按上面的 SQL 產生執行計劃 可以看出, 會產生一個書簽查找(Key Lookup),如下圖 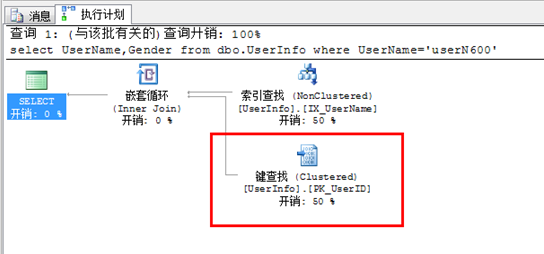
如果把上面的 SQL 改寫成
select UserName from dbo.UserInfo where UserName='userN600' 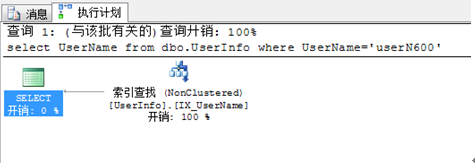
可以看出 書簽查找 沒有了。
本SQL 產生書簽查找的 主要原因是 本SQL 優化器會選擇 非聚簇索引IX_UserName,來執生SQL 。IX_UserName 索引不包含 Gender 這個字段 於是產生個從索引到 數據表的 一個 查找 即 書簽查找。
解決書簽查找:
方法一、使用一個 聚簇索引
對於聚簇索引, 索引的葉子頁面和表的數據頁面相同,因此,當讀取聚簇索引 鍵列的值時,數據引擎可以讀取其它列的值而不需要任何行定位,這樣就解決了書簽查找。
對於這句SQL ( select UserName,Gender from dbo.UserInfo where UserName='userN600')解決了書簽查找的辦法就是在UserName 上 建聚簇索引 ,因為一個表只有一個聚簇索引 ,這就意味著刪除現有聚簇索引(PK_UserID),將會造成其它從表 中的外鍵約束 要發生更改,這需要考一些相關的工作,可能嚴重影響依賴於現有聚簇索引的其它查詢。
方法二、使用一個 覆蓋索引
覆蓋索引 是在所有為滿足SQL 查詢不用到達基本表所需的列 建立的非聚簇索引。如果查詢遇到一個索引並且完全不需要引用底層數據表,那麼 該索引可以被認為是 覆蓋索引。
對於這句SQL ( select UserName,Gender from dbo.UserInfo where UserName='userN600') 解決書簽查找的辦法就是 在非聚簇索引IX_UserName 裡包含 Gender 字段。
也就是在 建索引時 用INCLUDE 語句,具體操作如下 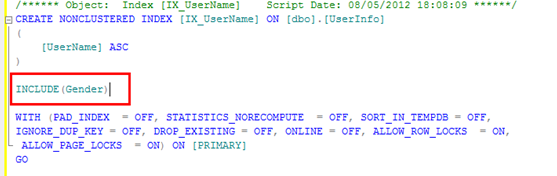
用INCLUDE 最好在 以下情況下使用:
1、不希望增加索引鍵的大小,但是仍然可以建一個 覆蓋索引;
2、打算索引一種不能被索引的數據類型(除了文本、NTEXT和圖像);
3、已經超過了一個索引的關鍵字列的最大數量
方法三、使用 索引連接
索引連接 是使用多個索引之間一個索引交叉來完全覆蓋一個查詢。如果覆蓋索引變的非常寬,那麼就可以考慮索引連接。
對於這句SQL ( select UserName,Gender from dbo.UserInfo where UserName='userN600' and Gender=1)可以在 Gender 上 建一個非聚簇索引就行了。
對於這個例 子,可能 SQL 優化器並沒有同時 選 用非聚簇索引IX_UserName 和 我們新建立在Gender 上的索引,這時我們可以告知 SQL 優化器 同時使用 這個兩上索引,操作如下
select Gender,UserName from UserInfo with(index (IX_Gender,IX_UserName)) where UserName='jins' and Gender=0
好了就寫這麼多吧.