據了解絕大多數開發人員對於索引的理解都是一知半解,局限於大多數日常工作沒有機會、也什麼沒有必要去關心、了解索引,實在哪天某個查詢太慢了找到查詢條件建個索引就ok,哪天又有個查詢慢了,再建立個索引就是,或者干脆把整個查詢SQL直接發給DBA,讓DBA直接幫忙優化了,所以造成的狀況就是開發人員對於索引的理解、認識很局限,以下就把我個人對於索引的理解及淺薄認識和大家分享下,希望能解除一些大家的疑惑,一起走出索引的誤區
誤區1.在表上建立了索引,在查詢時用到了索引的列,索引就一定會生效
首先明確下這樣的觀點是錯誤的,SQL Server查詢優化器是基於開銷進行選擇的優化器,通過一系列復雜判斷來決定是否使用索引、使用什麼類型索引、使用那個索引。SQL Server內部維護著索引列上的數據的統計,統計信息會隨著索引列內容的變化而變化,索引的有效期完全取決於索引列上的統計信息,隨著數據的變化關於索引的檢索機制也隨之變化。對於查詢優化器來說始終保持查詢開銷最低始終是其的不二選擇,如果一個非聚集索引的列上有大量的重復值,那麼這個索引就不會有什麼存在的意義,這也是為什麼不建議在類似性別,bit類型上面建立非聚集索引的原因。
說到這裡可能會有人疑惑,我在性別列上建一個索引,性別只有兩個值男、女,當我我們查詢條件中有性別這個字段時最起碼會過濾掉一半的數據,能大幅縮小我們需要檢索的數據范圍,怎麼會沒用呢?(事實上這也是我曾經困惑的地方),對我們理解的沒錯,比如說Users表性別列Gender上建立索引IX_Gender,執行select Gender from Users where Gender='男' ,這個查詢效率非常高而且也成功使用了索引IX_Gender,然而我們這樣寫SQL的時候少之又少,更多的我們會寫這樣的SQL:select UserID,UserName,Phone,Email from Users where Gender='男' 這時再去看看查詢計劃根本沒用使用索引IX_Gender,而是進行了一個聚集索引掃描或者表掃描,查詢條件where Gender='男' 明明在IX_Gender裡面定義了,為什麼沒使用呢,這一切罪惡的根源就在於書簽查找(RID、鍵查找),好了關於書簽查找不是我們要討論的話題,在這裡只想告訴大家,索引不是萬能的,索引不是創建了就一定有效。
誤區2.聚集索引掃描用到了聚集索引索引,所以性能很高
一般來說我們可以認為聚集索引是效率最高的索引,但聚集索引掃描絕不代表高效,本質上聚集索引掃描就是表掃描,一般出現掃描字樣時代表缺少索引或者索引無效,所以我們日常應用中應該避免在查詢計劃中看到掃描字樣,更多的出現聚集索引查找、索引查找才真正的使用到了索引,才是王道。
誤區3.聚集索引掃描(表掃描)是全表掃描,所以只要出現了表掃描就一定代表性能低下
在誤區2中我們說到應該盡量避免出現聚集索引掃描或者表掃描,這是我們必須要堅持的原則,但這並不代表這出現表掃描就一定性能低下,有些情況下表掃描反而比索引查找有著更高的效率(一般出現在返回數據量較大,出現大量書簽查找的情況下)
誤區4.查詢計劃中看到了鍵查找或者RID查找時有著很高的性能
鍵查找和RID查找統稱為書簽查找,和錯誤認識正好相反,出現書簽查找反而代表著性能低下,有些情況下甚至有著比表掃描更低的效率,因此我們應該盡量避免書簽查找。在返回數據量較小時,書簽查找對性能影響不大,若返回數據量較大,書簽查找會嚴重影響查詢性能,因此我們建立索引時應該盡量覆蓋要返回的所有列,當然索引列數是有限的而且也不能單純的為了避免書簽查找而在索引中包含大量的列,可以使用覆蓋索引來解決書簽查找問題,或者需要大數據量返回時盡量使用聚集索引;同時這也是為什麼常聽說的不要使用select *,而只選擇需要的列進行輸出,因為select *很容易導致書簽查找,畢竟我們不打可能在所有列上建立索引,也不可能所有查詢都使用聚集索引(使用聚集索引和表掃描時不存在書簽查找)
誤區5.查詢開銷統計中的邏輯讀次數是讀取的記錄數
天真的我曾經也這麼認為,查詢計劃中邏輯讀次數就是讀取的記錄數,然而看我們的查詢4.1全表掃描返回830行數據,為啥邏輯讀只有22次,而查詢4.5同樣是返回830行數據,邏輯讀為啥1724次呢,一次讀取一條的話邏輯讀22次最多返回22行數據,邏輯讀1724次的話應該返回1724條數據吧,有點小暈,這裡解釋下邏輯讀次數是指讀取的頁面數,一個面8KB,8個頁面構成一個區64KB,對於我們的示例表來說22個頁面足以存下所有數據,所以表掃描時只需讀取22次就可以了,那查詢4.5為啥讀取了1724次呢,就算一個頁面就一條數據按理說最多800多次也可以讀取完畢了,這是因為Sql Server對數據讀取的最小單位就是頁,哪怕讀取一條數據也需要讀取整頁數據,而非聚集索引的讀是隨機讀哪怕多條記錄在同一頁上也會導致多次重復讀取,外加書簽查找導致了這麼多的邏輯讀,這也是為什麼非聚集索引不適合讀取大量數據的原因之一。
我們以Northwind數據庫表Orders表為示例進行下演示
1.先將Orders表的索引全部刪除
4.在OrderID上面創建聚集索引,索引列為OrderID
復制代碼 代碼如下:
create unique clustered index IX_OrderID on Orders(OrderID)
3.在Orders表上創建非聚集索引IX_OrderDate
create index IX_OrderDate on Orders(OrderDate)
4.設置查詢分析器選中包含實際的執行計劃(右鍵-->包含實際的執行計劃),打開IO統計,並依次執行以下查詢
復制代碼 代碼如下:
set statistics io on
select * from Orders
select * from Orders where OrderDate<='1996-7-10'
select * from Orders where OrderDate<='1997-1-1'
--強制使用索引IX_OrderDate 查詢日期1997-1-1
select * from Orders with(index=IX_OrderDate) where OrderDate<='1997-1-1'
--強制使用索引IX_OrderDate查詢日2000-1-1
select * from Orders with(index=IX_OrderDate) where OrderDate<='2001-1-1'
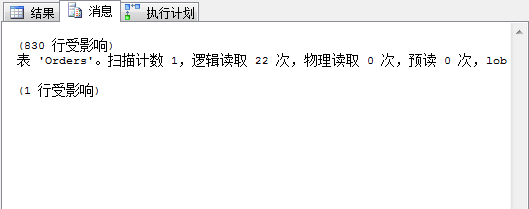
4.1 執行 select * from Orders 的查詢開銷及查詢計劃
可以看到執行的聚集索引掃描,邏輯讀22次,沒有使用索引,返回行數830行
4.2 執行 select * from Orders where OrderDate<='1996-7-10' 的查詢開銷借查詢計劃
可以看到成功使用了在OrderDate上面建立的索引IX_OrderDate,邏輯讀次數為14,返回行數6行
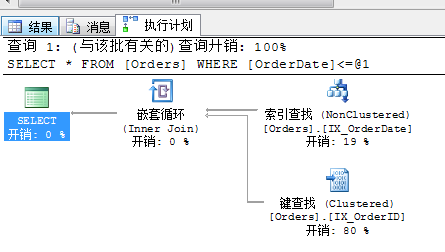
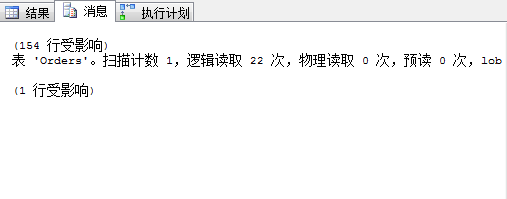
4.3 執行 select * from Orders where OrderDate<='1997-1-1' 的查詢開銷及查詢計劃
可以看到雖然我們在OrderDate上面建立了索引IX_OrderDate,但執行計劃並沒有使用索引IX_OrderDate而是執行了一個聚集索引掃描,邏輯讀次數22而這個查詢與4.2的區別僅僅在於OrderDate的值不一樣,返回行數154行
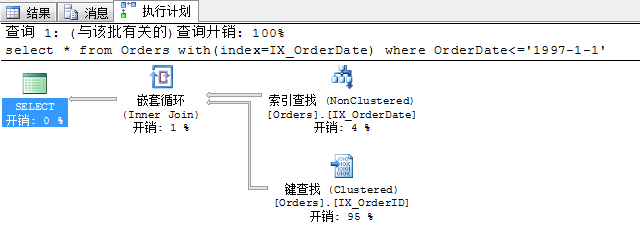
4.4 執行 select * from Orders with(index=IX_OrderDate) where OrderDate<='1997-1-1' 的查詢開銷及查詢計劃
可以看到查詢條件和4.3完全一致,我們強制使用了IX_OrderDate,返回記錄數和4.3完全一致,但邏輯讀達到了328次,返回行數154行
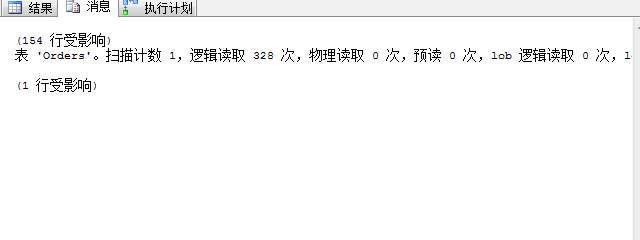
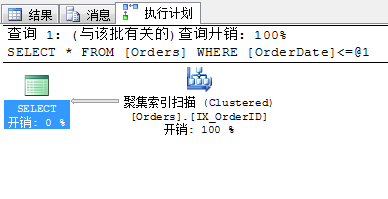
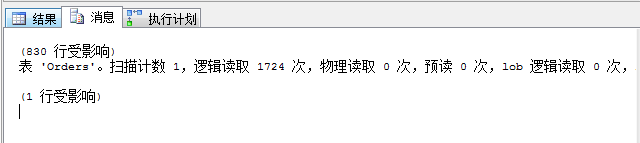
4.5 執行 select * from Orders with(index=IX_OrderDate) where OrderDate<='2001-1-1' 查詢開銷及查詢計劃
同樣我們強制使用了索引IX_OrderDate,查詢條件進行改變,邏輯讀達到了1724次,返回行數數830行
通過對比以上查詢我們可以知道雖然我們建立了索引,但索引並不總是有效,強制使用索引只會帶來更低的效率,查詢優化器會根據索引列的統計信息自動選擇最優的查詢計劃進行執行。查詢4.3和4.4查詢條件完全一樣,雖然我們建立了索引IX_OrderDate,但查詢優化器並沒有采用而是選擇了開銷更低的聚集索引掃描,在我們強制使用了索引後查詢開銷反而激增從邏輯讀22次達到了328次,而我們僅僅查詢到了154行數據;在查詢4.5中我們繼續強制使用索引,改變查詢條件的值,在返回830行數據的情況下邏輯讀次數達到了1724次,而返回相同數據的查詢4.1僅僅執行了22次邏輯讀。
困惑:通過查詢4.1我們知道Orders表一共才有830條數據,為什麼我們在查詢4.5中強制使用索引後邏輯讀達到了恐怖的1724次呢,即便一條數據讀取一次也才不過830次啊。
解惑:查詢4.5強制使用索引後,查詢優化器首先去到索引IX_OrderDate上面檢索,然後在根據索引IX_OrderDate去找聚集索引指針,根據聚集索引指針去聚簇索引葉子節點(實際數據行)查找數據(書簽查找),才導致了更大的查詢開銷。
結論:
1.索引不是萬能的,查詢列上建立了索引不代表就一定會使用索引(參見結論2)
2.絕大多數情況下查詢優化器會根據索引列上的數據統計信息自動選擇最優的執行計劃,而且查詢計劃會隨著數據量變化而變化,所以如果不是有必要不要使用索引提示來強制使用某索引
3.聚集索引掃描、表掃描不代表一定低效(表掃描不存在書簽查找,使用非聚集索引返回大量行時,若存在書簽查找反而不如表掃描性能高)
4.索引查找不一定高效(非聚集索引查找時容易出現書簽查找)
5.書簽查找會降低查詢效率,尤其是大范圍讀取數據時會嚴重影響效率,所以應該盡量避免書簽查找或出現書簽查找時盡量返回較少的數據行
6.需要注意下查詢開銷統計裡的邏輯讀是指讀取的頁面數而不是數據行數
示例中采用的語句及數據僅作為演示使用,實際開發應用中要比示例的數據復雜的多,同一個查詢在不同的環境下可能產生完全相反的結果,如何應用好還主要在於我們個人的認識和理解,希望有幸看到本文的朋友能借此加深一些對索引的理解和認識,走出索引的誤區,開發出高性能的應用。
本人不是DBA,只是一名普通的開發人員,以上均為實際工作中的一些經驗、體會,鑒於本人水平非常有限,有說的不對或理解不到位的地方還望各位大神給予指正,以免誤導他人,不勝感激。
後續會繼續寫一些關於Sql Server查詢性能優化方面的實踐經驗,主要包含以下幾方面
Sql Server查詢性能優化之建立合理的索引
Sql Server查詢性能優化之避免書簽查找
Sql Server查詢性能優化之復用查詢計劃
Sql Server查詢性能優化之選擇合適的字段類型
附上用的數據表:DemoDB.rar
從Northwind數據庫分離出來的,僅用了其中的Orders表
此文章屬懶惰的肥兔原創