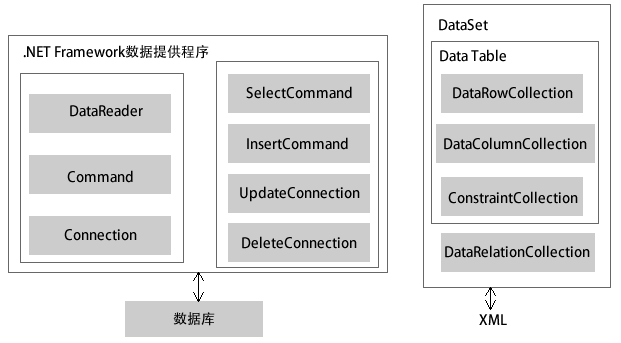
本文主要向大家介紹的是正確優化SQL Server數據庫的經驗總結,其中包括在對其進行優化的實際操作中值得大家注意的地方描述,以及對SQL語句進行優化的最基本原則,以下就是文章的主要內容描述。
優化數據庫的注意事項:
1、關鍵字段建立索引。
2、使用存儲過程,它使SQL變得更加靈活和高效。
3、備份數據庫和清除垃圾數據。
4、SQL語句語法的優化。(可以用Sybase的SQL Expert,可惜我沒找到unexpired的序列號)
5、清理刪除日志。
SQL語句優化的基本原則:
1、使用索引來更快地遍歷表。
缺省情況下建立的索引是非群集索引,但有時它並不是最佳的。在非群集索引下,數據在物理上隨機存放在數據頁上。合理的索引設計要建立在對各種查詢的分析和預測上。
一般來說:
①.有大量重復值、且經常有范圍查詢(between, >,< ,>=,< =)和order by、group by發生的列,可考慮建立群集索引
②.經常同時存取多列,且每列都含有重復值可考慮建立組合索引;
③.組合索引要盡量使關鍵查詢形成索引覆蓋,其前導列一定是使用最頻繁的列。
2、IS NULL 與 IS NOT NULL
不能用null作索引,任何包含null值的列都將不會被包含在索引中。即使索引有多列這樣的情況下,只要這些列中有一列含有null,該列就會從索引中排除。也就是說如果某列存在空值,即使對該列建索引也不會提高性能。任何在where子句中使用is null或is not null的語句優化器是不允許使用索引的。
3、IN和EXISTS
EXISTS要遠比IN的效率高。裡面關系到full table scan和range scan。幾乎將所有的IN操作符子查詢改寫為使用EXISTS的子查詢。
4、在海量查詢時盡量少用格式轉換。
5、當在SQL SERVER 2000中
如果存儲過程只有一個參數,並且是OUTPUT類型的,必須在調用這個存儲過程的時候給這個參數一個初始的值,否則會出現調用錯誤。
6、ORDER BY和GROPU BY
使用ORDER BY和GROUP BY短語,任何一種索引都有助於SELECT的性能提高。注意如果索引列裡面有NULL值,Optimizer將無法優化。
7、任何對列的操作都將導致表掃描,它包括SQL Server數據庫函數、計算表達式等等,查詢時要盡可能將操作移至等號右邊。
8、IN、OR子句常會使用工作表,使索引失效。如果不產生大量重復值,可以考慮把子句拆開。拆開的子句中應該包含索引。
9、SET SHOWPLAN_ALL>10、謹慎使用游標
在某些必須使用游標的場合,可考慮將符合條件的數據行轉入臨時表中,再對臨時表定義游標進行操作,這樣可使性能得到明顯提高。
注釋:所謂的優化就是WHERE子句利用了索引,不可優化即發生了表掃描或額外開銷。經驗顯示,SQL Server數據庫性能的最大改進得益於邏輯的數據庫設計、索引設計和查詢設計方面。反過來說,最大的性能問題常常是由其中這些相同方面中的不足引起的。
其實SQL優化的實質就是在結果正確的前提下,用優化器可以識別的語句,充份利用索引,減少表掃描的I/O次數,盡量避免表搜索的發生。其實SQL的性能優化是一個復雜的過程,上述這些只是在應用層次的一種體現,深入研究還會涉及SQL Server數據庫層的資源配置、網絡層的流量控制以及操作系統層的總體設計。