復制代碼 代碼如下:
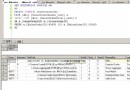
create table tb(id int, value varchar(10))
insert into tb values(1, 'aa')
insert into tb values(1, 'bb')
insert into tb values(2, 'aaa')
insert into tb values(2, 'bbb')
insert into tb values(2, 'ccc')
go
create function [dbo].[f_str](@id int) returns nvarchar(1000)
as
begin
declare @str nvarchar(1000)
set @str = ''
select @str = @str + ',' + cast(value as nvarchar(900)) from tb where id = @id
set @str = right(@str , len(@str) - 1)
return @str
end
go
--調用函數
select id , value = dbo.f_str(id) from tb group by id
運行結果: 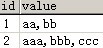
本來在上面的函數中所有的nvarchar都是varchar類型的,並且上面函數的紅色處在調用cast方法時,並未指定長度。朋友測試後發現,結果會在30個字符 時截斷,原來以為是varchar和nvarchar的區別,我試著將varchar改成了nvarchar,朋友測試的結果是在54個字符處截斷。我查了下,是varchar的默認長度問題,見sql server聯機叢書中下面的說明:
char 和 varchar
固定長度 (char) 或可變長度 (varchar) 字符數據類型。
char[(n)]
長度為 n 個字節的固定長度且非 Unicode 的字符數據。n 必須是一個介於 1 和 8,000 之間的數值。存儲大小為 n 個字節。char 在 SQL-92 中的同義詞為 character。
varchar[(n)]
長度為 n 個字節的可變長度且非 Unicode 的字符數據。n 必須是一個介於 1 和 8,000 之間的數值。存儲大小為輸入數據的字節的實際長度,而不是 n 個字節。所輸入的數據字符長度可以為零。varchar 在 SQL-92 中的同義詞為 char varying 或 character varying。
注釋
如果沒有在數據定義或變量聲明語句中指定 n,則默認長度為 1。如果沒有使用 CAST 函數指定 n,則默認長度為 30。
將為使用 char 或 varchar 的對象被指派數據庫的默認排序規則,除非用 COLLATE 子句另外指派了特定的排序規則。該排序規則控制用於存儲字符數據的代碼頁。
支持多語言的站點應考慮使用 Unicode nchar 或 nvarchar 數據類型以盡量減少字符轉換問題。如果使用 char 或 varchar:
如果希望列中的數據值大小接近一致,請使用 char。
如果希望列中的數據值大小顯著不同,請使用 varchar。
如果執行 CREATE TABLE 或 ALTER TABLE 時 SET ANSI_PADDING 為 OFF,則一個定義為 NULL 的 char 列將被作為 varchar 處理。
當排序規則代碼頁使用雙字節字符時,存儲大小仍然為 n 個字節。根據字符串的不同,n 個字節的存儲大小可能小於 n 個字符。