先看一般的數據插入方法,假設我們向上表中插入100000 條數據:
復制代碼 代碼如下:
CREATE TABLE #tempTable([Item ID] [bigint], [Item Name] nvarchar(30))
DECLARE @counter int
SET @counter = 1
WHILE (@counter < 100000)
BEGIN
INSERT INTO #tempTable VALUES (@counter, 'Hammer')
SET @counter = @counter + 1
END
SELECT * FROM #tempTable
DROP TABLE #tempTable
新的插入方法會使用已經插入的數據來進行下一條記錄的操作,原理如下:
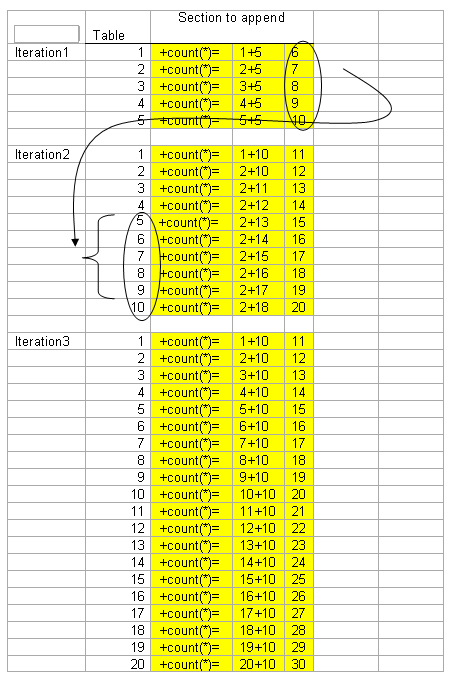
那麼看看我的新insert代碼:
復制代碼 代碼如下:
CREATE TABLE #tempTable([Item ID] [bigint], [Item Name] nvarchar(30))
INSERT INTO #tempTable VALUES (1, 'Hammer')
WHILE((SELECT COUNT(*) FROM #tempTable) < 100000)
BEGIN
INSERT INTO #tempTable ([Item ID], [Item Name])
(SELECT [Item ID] + (SELECT COUNT(*) FROM #tempTable), 'Hammer' FROM #tempTable)
END
SELECT * FROM #tempTable
DROP TABLE #tempTable
用第一種方法可能需要幾十分鐘插入100000數據,但是用第二種只要4秒鐘。再改進下,2秒鐘就完成:
復制代碼 代碼如下:
CREATE TABLE #tempTable([Item ID] [bigint], [Item Name] nvarchar(30))
INSERT INTO #tempTable VALUES (1, 'Hammer')
DECLARE @counter int
SET @counter = 1
WHILE(@counter <= 17)
BEGIN
INSERT INTO #tempTable ([Item ID], [Item Name])
(SELECT [Item ID] + (SELECT COUNT(*) FROM #tempTable), 'Hammer' FROM #tempTable)
SET @counter = @counter + 1
END
SELECT * FROM #tempTable
DROP TABLE #tempTable