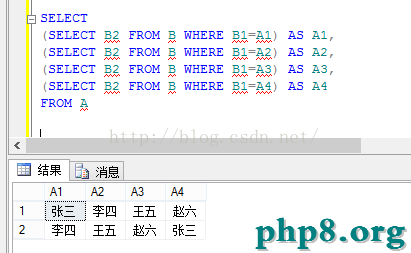
在sqlserver中若何應用CTE處理龐雜查訊問題。本站提示廣大學習愛好者:(在sqlserver中若何應用CTE處理龐雜查訊問題)文章只能為提供參考,不一定能成為您想要的結果。以下是在sqlserver中若何應用CTE處理龐雜查訊問題正文
字符串是編程時觸及到的最多的一種數據構造,對字符串停止操作的需求簡直無處不在。好比斷定一個字符串能否是正當的Email地址,固然可以編程提取@前後的子串,再分離斷定能否是單詞和域名,但如許做不只費事,並且代碼難以復用。
正則表達式是一種用來婚配字符串的強無力的兵器。它的設計思惟是用一種描寫性的說話來給字符串界說一個規矩,但凡相符規矩的字符串,我們就以為它“婚配”了,不然,該字符串就是不正當的。
所以我們斷定一個字符串能否是正當的Email的辦法是:
由於正則表達式也是用字符串表現的,所以,我們要起首懂得若何用字符來描寫字符。
在正則表達式中,假如直接給出字符,就是准確婚配。用\d可以婚配一個數字,\w可以婚配一個字母或數字,所以:
.可以婚配隨意率性字符,所以:
'py.'可以婚配'pyc'、'pyo'、'py!'等等。
要婚配變長的字符,在正則表達式中,用*表現隨意率性個字符(包含0個),用+表現至多一個字符,用?表現0個或1個字符,用{n}表現n個字符,用{n,m}表現n-m個字符:
來看一個龐雜的例子:\d{3}\s+\d{3,8}。
我們來從左到右解讀一下:
綜合起來,下面的正則表達式可以婚配以隨意率性個空格離隔的帶區號的德律風號碼。
假如要婚配'010-12345'如許的號碼呢?因為'-'是特別字符,在正則表達式中,要用'\'本義,所以,下面的正則是\d{3}\-\d{3,8}。
然則,依然沒法婚配'010 - 12345',由於帶有空格。所以我們須要更龐雜的婚配方法。
進階
要做更准確地婚配,可以用[]表現規模,好比:
A|B可以婚配A或B,所以[P|p]ython可以婚配'Python'或許'python'。
^表現行的開首,^\d表現必需以數字開首。
$表現行的停止,\d$表現必需以數字停止。
你能夠留意到了,py也能夠婚配'python',然則加上^py$就釀成了整行婚配,就只能婚配'py'了。
re模塊
有了預備常識,我們便可以在Python中應用正則表達式了。Python供給re模塊,包括一切正則表達式的功效。因為Python的字符串自己也用\本義,所以要特殊留意:
s = 'ABC\\-001' # Python的字符串 # 對應的正則表達式字符串釀成: # 'ABC\-001'
是以我們激烈建議應用Python的r前綴,就不消斟酌本義的成績了:
s = r'ABC\-001' # Python的字符串 # 對應的正則表達式字符串不變: # 'ABC\-001'
先看看若何斷定正則表達式能否婚配:
>>> import re
>>> re.match(r'^\d{3}\-\d{3,8}$', '010-12345')
<_sre.SRE_Match object at 0x1026e18b8>
>>> re.match(r'^\d{3}\-\d{3,8}$', '010 12345')
>>>
match()辦法斷定能否婚配,假如婚配勝利,前往一個Match對象,不然前往None。罕見的斷定辦法就是:
test = '用戶輸出的字符串' if re.match(r'正則表達式', test): print 'ok' else: print 'failed'
切分字符串
用正則表達式切分字符串比用固定的字符更靈巧,請看正常的切分代碼:
>>> 'a b c'.split(' ')
['a', 'b', '', '', 'c']
嗯,沒法辨認持續的空格,用正則表達式嘗嘗:
>>> re.split(r'\s+', 'a b c') ['a', 'b', 'c']
不管若干個空格都可以正常朋分。參加,嘗嘗:
>>> re.split(r'[\s\,]+', 'a,b, c d') ['a', 'b', 'c', 'd']
再參加;嘗嘗:
>>> re.split(r'[\s\,\;]+', 'a,b;; c d') ['a', 'b', 'c', 'd']
假如用戶輸出了一組標簽,下次記得用正則表達式來把不標准的輸出轉化成准確的數組。
分組
除簡略地斷定能否婚配以外,正則表達式還有提取子串的壯大功效。用()表現的就是要提取的分組(Group)。好比:
^(\d{3})-(\d{3,8})$分離界說了兩個組,可以直接從婚配的字符串中提掏出區號和當地號碼:
>>> m = re.match(r'^(\d{3})-(\d{3,8})$', '010-12345')
>>> m
<_sre.SRE_Match object at 0x1026fb3e8>
>>> m.group(0)
'010-12345'
>>> m.group(1)
'010'
>>> m.group(2)
'12345'
假如正則表達式中界說了組,便可以在Match對象上用group()辦法提掏出子串來。
留意到group(0)永久是原始字符串,group(1)、group(2)……表現第1、2、……個子串。
提取子串異常有效。來看一個更殘暴的例子:
>>> t = '19:05:30'
>>> m = re.match(r'^(0[0-9]|1[0-9]|2[0-3]|[0-9])\:(0[0-9]|1[0-9]|2[0-9]|3[0-9]|4[0-9]|5[0-9]|[0-9])\:(0[0-9]|1[0-9]|2[0-9]|3[0-9]|4[0-9]|5[0-9]|[0-9])$', t)
>>> m.groups()
('19', '05', '30')
這個正則表達式可以直接辨認正當的時光。然則有些時刻,用正則表達式也沒法做到完整驗證,好比辨認日期:
'^(0[1-9]|1[0-2]|[0-9])-(0[1-9]|1[0-9]|2[0-9]|3[0-1]|[0-9])$'
關於'2-30','4-31'如許的不法日期,用正則照樣辨認不了,或許說寫出來異常艱苦,這時候就須要法式合營辨認了。
貪心婚配
最初須要特殊指出的是,正則婚配默許是貪心婚配,也就是婚配盡量多的字符。舉例以下,婚配出數字前面的0:
>>> re.match(r'^(\d+)(0*)$', '102300').groups()
('102300', '')
因為\d+采取貪心婚配,直接把前面的0全體婚配了,成果0*只能婚配空字符串了。
必需讓\d+采取非貪心婚配(也就是盡量少婚配),能力把前面的0婚配出來,加個?便可以讓\d+采取非貪心婚配:
>>> re.match(r'^(\d+?)(0*)$', '102300').groups()
('1023', '00')
編譯
當我們在Python中應用正則表達式時,re模塊外部會干兩件工作:
假如一個正則表達式要反復應用幾千次,出於效力的斟酌,我們可以預編譯該正則表達式,接上去反復應用時就不須要編譯這個步調了,直接婚配:
>>> import re
# 編譯:
>>> re_telephone = re.compile(r'^(\d{3})-(\d{3,8})$')
# 應用:
>>> re_telephone.match('010-12345').groups()
('010', '12345')
>>> re_telephone.match('010-8086').groups()
('010', '8086')
編譯後生成Regular Expression對象,因為該對象本身包括了正則表達式,所以挪用對應的辦法時不消給出正則字符串。
小結
正則表達式異常壯大,要在短短的一節裡講完是弗成能的。要講清晰正則的一切內容,可以寫一本厚厚的書了。假如你常常碰到正則表達式的成績,你能夠須要一本正則表達式的參考書。
請測驗考試寫一個驗證Email地址的正則表達式。版本一應當可以驗證出相似的Email:
[email protected] [email protected] Try
版本二可以驗證並提掏出帶名字的Email地址:
<Tom Paris> [email protected]