深刻進修SQL Server聚合函數算法優化技能。本站提示廣大學習愛好者:(深刻進修SQL Server聚合函數算法優化技能)文章只能為提供參考,不一定能成為您想要的結果。以下是深刻進修SQL Server聚合函數算法優化技能正文
Sql server聚合函數在現實任務中應對各類需求應用的照樣很普遍的,關於聚合函數的優化天然也就成了一個重點,一個法式優化的好欠好直接決議了這個法式的聲明周期。Sql server聚合函數對一組值履行盤算並前往單一的值。聚合函數對一組值履行盤算,並前往單個值。除 COUNT 之外,聚合函數都邑疏忽空值。 聚合函數常常與 SELECT 語句的 GROUP BY 子句一路應用。
一.寫在後面
假如有對Sql server聚合函數不熟或許忘卻了的可以看我之前的一片博客。
本文中一切數據演示都是用Microsoft官方示例數據庫:Northwind,至於Northwind年夜家也能夠在網高低載。
二.Sql server標量聚合
2.1.概念:在只包括聚合函數的 SELECT 語句列列表中指定的一種聚合函數(如 MIN()、MAX()、COUNT()、SUM() 或 AVG())。當列列表只包括聚合函數時,則成果集只具有一個行給出聚合值,該值由與 WHERE 子句謂詞相婚配的源行盤算獲得。
2.2.摸索標量聚合:
我們先用Sql server的"包含現實的履行籌劃"來看看一個簡略的流聚合COUNT()來看看內外數據一切的行數。

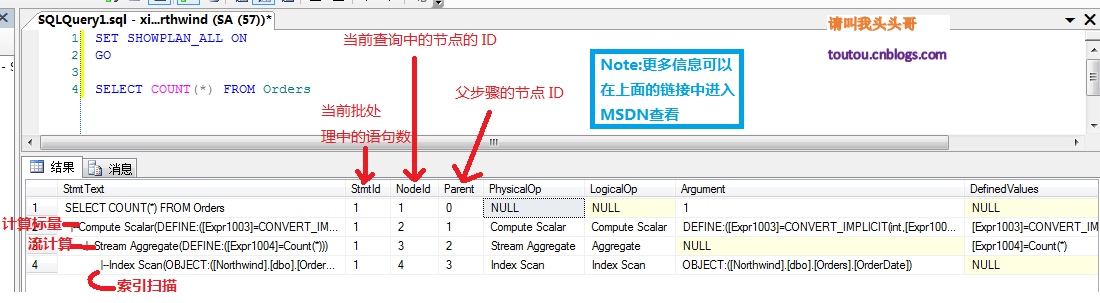
再經由過程SET SHOWPLAN_ALL ON(關於輸入中包括的列更多信息可以在鏈接中檢查)來看看有關語句履行情形的具體信息,並估量語句對資本的需求。
經由過程SET SHOWPLAN_ALL ON我們來看看COUNT()詳細做了那些工作:
2.3.標量聚合優化技能:
我們經由過程兩個比擬簡略的sql查詢來看看他們的差別
SELECT COUNT(DISTINCT ShipCity) FROM OrdersSELECT COUNT(DISTINCT OrderID) FROM Orders
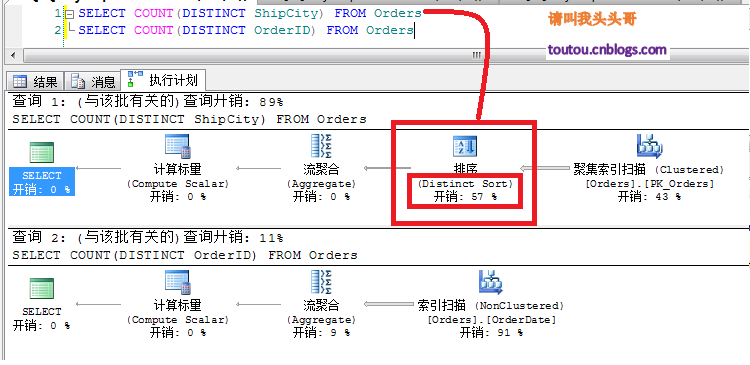
從上圖中可以看到,其實這兩個查詢從語句下去說沒甚麼太年夜的差別,然則為何開支會紛歧樣,一個是查詢城市一個是查詢定單號。這是由於其實DISTINCT關於OrderID查詢來講,是沒有甚麼意義的,由於OrderID是主鍵,是不會有反復的。而ShipCity是會有反復的,Sql server的去重機制在去重的時刻,會有一個排序的進程。這個排序照樣比擬消費資本的。
關於數據量比擬年夜的表其實不是很建議對年夜表排序或許對年夜表的某個反復次數多的字段去重運算。所以我們這裡可以對ShipCity停止優化一下。可以對ShipCity創立一個非集合索引。
CREATE INDEX Index_ShipCity On Orders(ShipCity desc)go
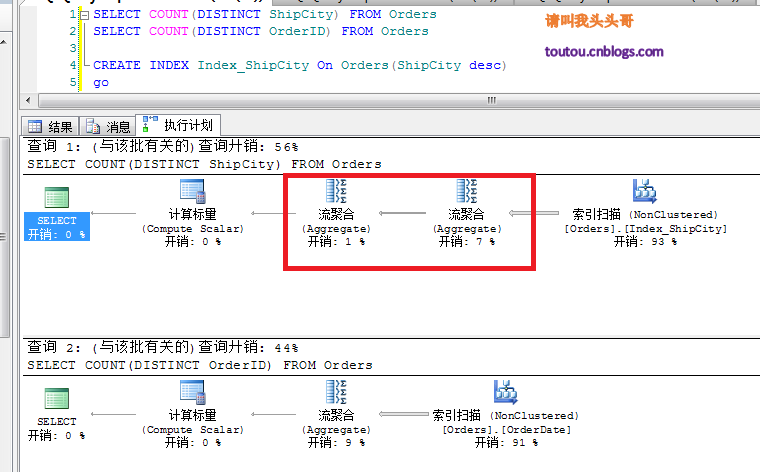
從上圖中可以看到,加了索引今後COUNT(DISTINCT ShipCity)的查詢釀成了兩個流聚合,而沒有了排序,節儉了開支。
總結:關於標量聚合從下面的例子年夜家可以看到,標量聚合優缺陷很顯著:
三.Sql server哈希聚合
3.1.概念:
哈希(Hash,普通翻譯做“散列”,也有直接音譯為“哈希”的,就是把隨意率性長度的輸出(又叫做預映照, pre-image),經由過程散列算法,變換成固定長度的輸入,該輸入就是散列值。這類轉換是一種緊縮映照,也就是,散列值的空間平日遠小於輸出的空間,分歧的輸出能夠會散列成雷同的輸入,所以弗成能從散列值來獨一切實其實定輸出值。簡略的說就是一種將隨意率性長度的新聞緊縮到某一固定長度的新聞摘要的函數。)
哈希聚合的外部完成辦法和哈希銜接的完成機制一樣,須要哈希函數的外部運算,構成分歧的哈希值,順次並行掃描數據構成聚合值。
3.2.配景:
為懂得決流聚合的缺乏,應對年夜數據的操作,所以哈希聚合就出生了。
3.3.剖析:
來看看兩個簡略的查詢。

ShipCountry和CustomerID的分組查詢看上去很相似,然則為何履行籌劃會分歧呢?這是由於ShipCountry包括了年夜量的反復值,CustomerID反復值異常少,所以Sql server體系給ShipCountry推送的哈希聚合,而CustomerID推送的是流聚合。也就是說Sql server體系會靜態的依據查詢的情形選擇適合的聚合方法。所以我們在做SQL優化的時刻不克不及僅依據SQL語句來優化,還得聯合詳細數據散布的情況。
四.運算進程監控目標
4.1.監控元素:
可視化檢查運轉時光T-sql語句查詢時光占用內存T-sql語句查詢IO
4.2.可視化檢查運轉時光: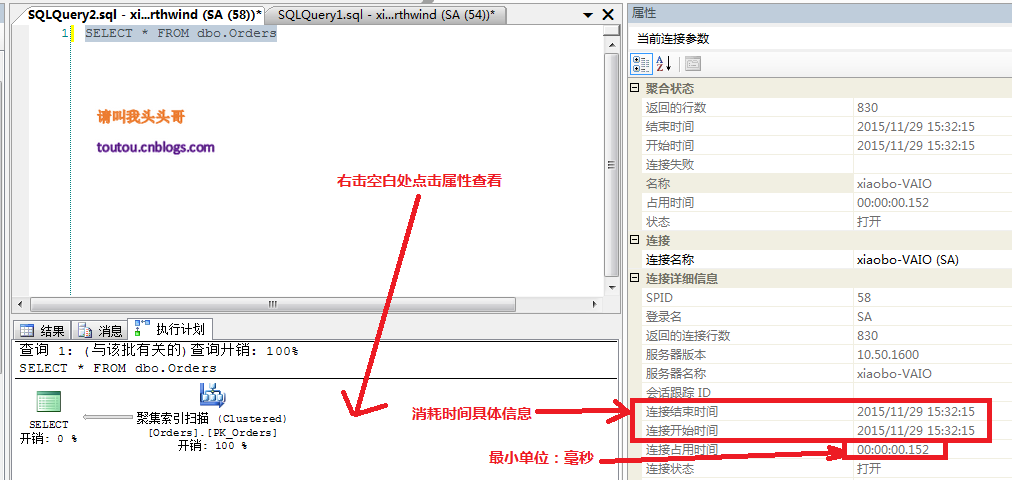
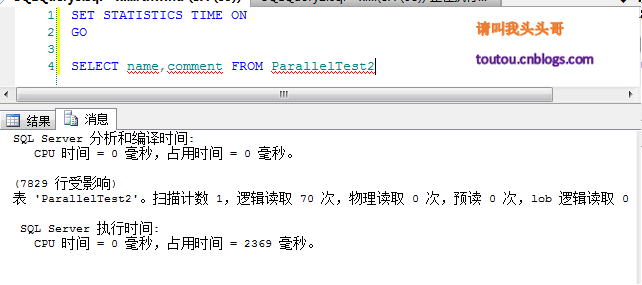
4.3.T-sql語句查詢時光:
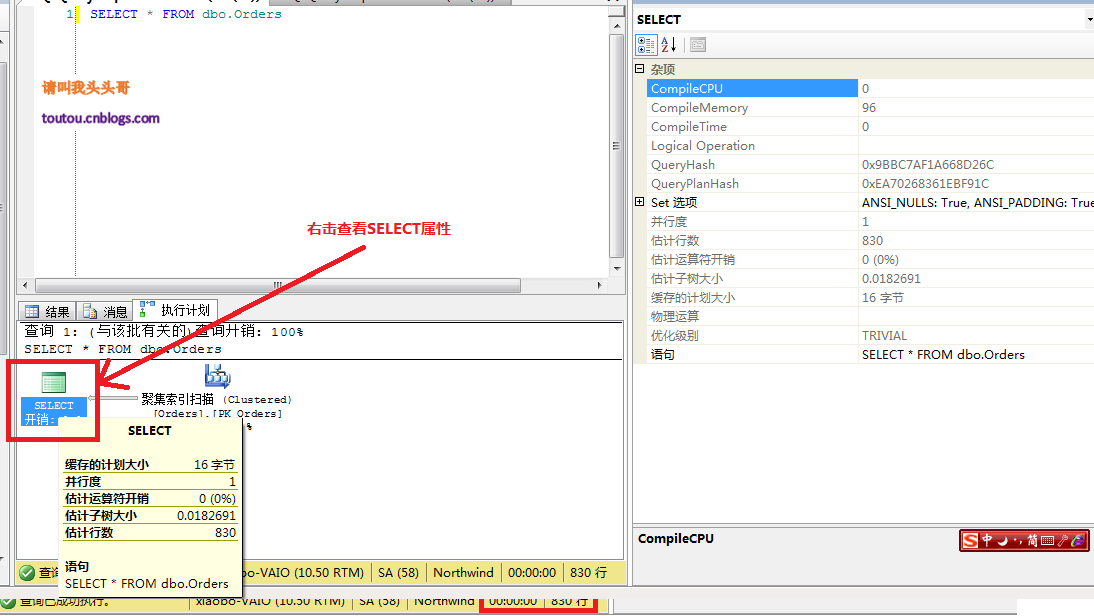
4.4.占用內存:
4.5.T-sql語句查詢IO:

關於監控元素還有許多,這裡就羅列幾個。
SQL Server 聚合函數算法優化技能差不多就引見到這裡,願望對年夜家優化聚合函數算法有所贊助。