經由過程格局優越的SQL進步效力和精確性。本站提示廣大學習愛好者:(經由過程格局優越的SQL進步效力和精確性)文章只能為提供參考,不一定能成為您想要的結果。以下是經由過程格局優越的SQL進步效力和精確性正文
格局優越的SQL其實不會比雜亂無章的SQL運轉後果更好。數據庫其實不怎樣關懷SQL語句中你把逗號放到了字段名的後面照樣前面。為了你本身思緒清晰,應當做一個有用率的SQL編寫者,我建議你遵照以下這些格局規矩。在本文中我將分享若何經由過程格局優越的SQL語句晉升臨盆率。我界說的效力指的是能從SQL 輸入精確的成果,而且代碼清楚易於懂得、修正和調試。我只列出了“SELECT”語句,由於我寫的SQL語句99%都是查詢語句。格局化SQL代碼長短常特性化的事,我也很清晰因人而異,開辟者都以為本身的格局化規矩是最公道的。
樣例成績
上面是一個典范的SQL運用場景,營業報表的數據來自三張表,客戶表、發賣表和地區表。基於2015年一月份的數據,該報表須要展現在每一個行政區內的客戶總數和銷量總數。該需求經由過程一個簡略的SQL語句便可以完成,須要聯系關系查詢三張表。
數據能夠湧現的成績
固然SQL很簡略,但包管你的成果准確依然是真實的症結,由於有上面一些緣由能夠招致毛病:
數據能夠來自分歧的數據源。也就是說你不克不及包管這幾個表之間的完全性。詳細舉例來講,你不克不及假定客戶表中一切的郵政編碼都是有用的郵政編碼,而且必定在地區表中存在。
錄入客戶表數據的運用能夠捕捉到未經歷證的所在數據,能夠會包含毛病的郵政編碼。
郵政編碼表能夠不是完全的。新宣布的郵政編碼能夠沒有在宣布後實時導入到表中。


第一准繩
對我來講,比擬於編寫清楚易讀的SQL,從SQL獲得准確的成果才是第一要務。我要做的第一件事就是編寫上面的SQL語句來獲得客戶總數。在我寫完全個語句以後我會再調劑它。
我寫的第一個語句是如許的:
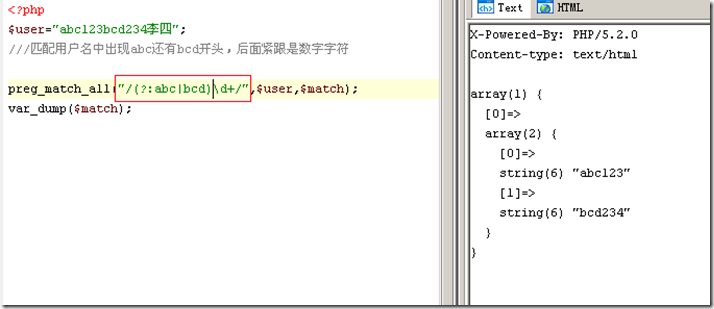
SELECTCOUNT(DISTINCT cust_id) as count_customersFROMcustomers Result: count_customers “10”
這個查詢很主要,由於它牢牢環繞第一准繩。由於沒有SQL治理查詢,也就沒有依附,我曉得這就是客戶數目的准確成果。我把這個成果記上去,由於我總須要拿這個數字來權衡前面的SQL(能否准確),在本文前面也會屢次提到。
下一步要做的事就是添加需要的字段和表完成查詢。我特地把“添加”這個詞高亮標注出來,由於依據我的規矩,我會在運用第一准繩時把能獲得雷同成果的查詢正文失落。上面就是我終究格局化的查詢語句。
格局化SQL
上面就是依據我的格局化思緒推舉的格局化SQL。
SELECT 0 ,c.cust_post_code ,p.location ,COUNT(DISTINCT c.cust_id) number_customers ,SUM(s.total_amount) as total_sales FROM customers c JOIN post_codes p ON c.cust_post_code = p.post_code JOIN sales s ON c.cust_id = s.cust_id WHERE 1=1 AND s.sales_date BETWEEN ‘2015-01-01' AND ‘2015-01-31' —AND s.order_id = 5 GROUP BY c.cust_post_code ,p.location
老是應用表別號
時光會證實這麼做是有需要的。假如你沒有對SQL語句頂用到的每一個字段應用別號,在未來某個時刻能夠會給這個查詢語句添加出去其余同名字段。到那時刻你的查詢甚至報表就會發生毛病(湧現了重名字段名)。
逗號放到字段之前
在調試或許測試我的查詢語句時,這麼做可以便利地正文失落某個字段,而不須要修正其它行,一切的逗號都沒出缺少或過剩。不這麼做的話你能夠總要調劑逗號能力包管語句准確。假如你常常要調試語句,這麼做會帶來極年夜便利,效力會更高。這個做法對“SELECT”部門和“GROUP BY”子句部門異樣實用。
在開辟時我應用“SELECT 0”作為語句的開端,遷徙到正式情況時它很輕易刪除失落。如許我們便可以在前面一切字段後面都寫都好了。沒有這個“0”的話,假如我想正文失落第一個字段(本例中是“c.cust_post_code”),我就必需處置前面的逗號成績。我必需暫時正文失落它,未來還要加回來。在“GROUP BY”語句中也是一樣的。這個“0”是額定加的。
把“JOIN”放到自力行
把“JOIN”語句放到自力行有以下利益:
這麼做很輕易看到本查詢語句觸及的一切表,只須要看轉動“JOIN”語句便可以了。
應用“JOIN”比擬於在“WHERE”子句中列出一切表和表達式關系,可以把一切邏輯關系都放到一個處所。我們弗成能老是吧“JOIN”語句放到一行中,然則至多應當放到一路。
這麼做的話要正文失落“JOIN”語句也是絕對輕易的。這在調試時異常有效,你能夠須要曉得能否是“JOIN”惹起了數據成績。
列形式編纂
在處置年夜量字段的情形時,列形式編纂異常便利。上面是我已經做過的第一個靜態GIF展現,你可以正文失落一切非集合字段。我應用了列形式編纂,而不只僅是正文失落字段:
創立全體索引
在應用字段較多的UNION語句時:
正文失落“GROUP BY”子句的字段清單

測試查詢成果
我必需應用外銜接“OUTER”列出一切客戶,由於不是一切客戶的郵政編碼都在地區內外有響應的郵政編碼。我可以經由過程包括和消除分歧字段和表重復操作來確保我查詢的成果與最開端誰人查詢(零丁查詢客戶的誰人語句)成果雷同,這實際上是對第一准繩的遵照。
SELECT0,c.cust_post_code—,p.location,COUNT(DISTINCT c.cust_id) number_customers,SUM(s.total_amount) as total_salesFROMcustomers c—LEFT OUTER JOIN post_codes p ON c.cust_post_code = p.post_codeJOIN sales s ON c.cust_id = s.cust_idWHERE1=1AND s.sales_date BETWEEN ‘2015-01-01' AND ‘2015-01-31'—AND c.cust_post_code = 2000—AND p.post_code = 200GROUP BYc.cust_post_code—,p.location
像如許的SQL對我來講意味著我必需寫自力的測試來檢討數據。經由過程正文失落的那幾行語句我可使用第一准繩驗證我查詢數據的精確性。這麼做進步了我的效力和報表。
以上就是本文的全體內容,願望對年夜家的進修有所贊助。