深刻剖析SqlServer查詢籌劃。本站提示廣大學習愛好者:(深刻剖析SqlServer查詢籌劃)文章只能為提供參考,不一定能成為您想要的結果。以下是深刻剖析SqlServer查詢籌劃正文
關於SQL Server的優化來講,優化查詢能夠是很罕見的工作。因為數據庫的優化,自己也是一個觸及面比擬的廣的話題, 是以本文只談優化查詢時若何看懂SQL Server查詢籌劃。究竟我對SQL Server的熟悉無限,若有毛病,也懇請您在發明後實時批駁斧正。
起首,翻開【SQL Server Management Studio】,輸出一個查詢語句看看SQL Server是若何顯示查詢籌劃的吧。
解釋:本文所演示的數據庫,是我為一個演示法式公用預備的數據庫,可以在此網頁中下載。
select v.OrderID, v.CustomerID, v.CustomerName, v.OrderDate, v.SumMoney, v.Finished from OrdersView as v where v.OrderDate >= '2010-12-1' and v.OrderDate < '2011-12-1';
個中,OrdersView是一個視圖,其界說以下:
SELECT dbo.Orders.OrderID, dbo.Orders.CustomerID, dbo.Orders.OrderDate,
dbo.Orders.SumMoney, dbo.Orders.Finished,
ISNULL(dbo.Customers.CustomerName, N'') AS CustomerName
FROM dbo.Orders LEFT OUTER JOIN
dbo.Customers ON dbo.Orders.CustomerID = dbo.Customers.CustomerID
關於前一句查詢,SQL Server給出的查詢籌劃以下(點擊對象欄上的【顯示估量的履行籌劃】按鈕):

從這個圖中,我們至多可以獲得3個有效的信息:
1. 哪些履行步調消費的本錢比擬高。明顯,最左邊的二個步調的本錢是比擬高的。
2. 哪些履行步調發生的數據量比擬多。關於每一個步調所發生的數據量, SQL Server的履行籌劃是用【線條粗細】來表現的,是以也很輕易地從分辯出來。
3. 每步履行了甚麼樣的舉措。
關於一個比擬慢的查詢來講,我們平日要曉得哪些步調的本錢比擬高,進而,可以測驗考試一些改良的辦法。 普通來講,假如您不克不及經由過程:進步硬件機能或許調劑OS,SQL Server的設置之類的方法來處理成績,那末剩下的可選辦法平日也只要以下這些了:
1. 為【scan】這類操作增長響應字段的索引。
2. 有時重建索引也許也是有用的,詳細情況請參考後文。
3. 調劑語句構造,引誘SQL Server采取其它的查詢計劃去履行。
4. 調劑表構造(分表或許分區)。
上面再來講說一些很主要的實際常識,這些內容關於履行籌劃的懂得是很有贊助的。
回到頂部SQL Server 查找記載的辦法
說到這裡,不能不說SQL Server的索引了。SQL Server有二種索引:集合索引和非集合索引。兩者的差異在於:【集合索引】直接決議了記載的寄存地位, 或許說:依據集合索引可以直接獲得到記載。【非集合索引】保留了二個信息:1.響應索引字段的值,2.記載對應集合索引的地位(假如表沒有集合索引則保留記載指針)。 是以,假如能經由過程【集合索引】來查找記載,明顯也是最快的。
SQL Server 會有以下辦法來查找您須要的數據記載:
1. 【Table Scan】:遍歷全部表,查找一切婚配的記載行。這個操作將會一行一行的檢討,固然,效力也是最差的。
2. 【Index Scan】:依據索引,從表中過濾出來一部門記載,再查找一切婚配的記載行,明顯比第一種方法的查找規模要小,是以比【Table Scan】要快。
3. 【Index Seek】:依據索引,定位(獲得)記載的寄存地位,然後獲得記載,是以,比起前二種方法會更快。
4. 【Clustered Index Scan】:和【Table Scan】一樣。留意:不要認為這裡有個Index,就以為紛歧樣了。 其實它的意思是說:按集合索引來逐行掃描每行記載,由於記載就是按集合索引來次序寄存的。 而【Table Scan】只是說:要掃描的表沒有集合索引罷了,是以這二個操作實質上也是一樣的。
5. 【Clustered Index Seek】:直接依據集合索引獲得記載,最快!
所以,當發明某個查詢比擬慢時,可以起首檢討哪些操作的本錢比擬高,再看看那些操作在查找記載時, 是否是【Table Scan】或許【Clustered Index Scan】,假如確切和這二種操作類型有關,則要斟酌增長索引來處理了。 不外,增長索引後,也會影響數據表的修正舉措,由於修正數據表時,要更新響應字段的索引。所以索引過量,也會影響機能。 還有一種情形是不合適增長索引的:某個字段用0或1表現的狀況。例如能夠有絕年夜多半是1,那末此時加索引基本就沒成心義。 這時候只能斟酌為0或許1這二種情形離開來保留了,分表或許分區都是不錯的選擇。
假如不克不及經由過程增長索引和調劑表來處理,那末可以嘗嘗調劑語句構造,引誘SQL Server采取其它的查詢計劃去履行。 這類辦法請求: 1.對語句所要完成的功效很清晰, 2.對要查詢的數據表構造很清晰, 3.對相干的營業配景常識很清晰。 假如能經由過程這類辦法去處理,固然也是很好的處理辦法了。不外,有時SQL Server比擬智能,即便你調劑語句構造,也不會影響它的履行籌劃。
若何比擬二個雷同功效的SQL語句的機能利害呢,我建議采取二種辦法: 1. 直接把二個查詢語句放在【SQL Server Management Studio】,然後去看它們的【履行籌劃】,SQL Server會以百分比的方法告知你二個查詢的【查詢開支】。 這類辦法簡略,平日也是可以參考的,不外,有時也會禁絕,詳細緣由請接著往下看(能夠索引統計信息過舊)。
2. 依據真實的法式挪用,寫響應的測試代碼去挪用:這類辦法就費事一些,然則它更能代表示實挪用情形, 獲得的成果也是更具有參考價值的,是以也是值得的。
回到頂部SQL Server Join 方法
在SQL Server中,每一個join敕令,都邑在外部履行時采取三種更詳細的方法來運轉:
1. 【Nested Loops join】,假如一個聯接輸出很小,而另外一個聯接輸出很年夜並且已在其聯接列上創立了索引, 則索引 Nested Loops 銜接是最快的聯接操作,由於它們須要的 I/O 和比擬都起碼。
嵌套輪回聯接也稱為“嵌套迭代”,它將一個聯接輸出用作內部輸出表(顯示為圖形履行籌劃中的頂端輸出),將另外一個聯接輸出用作外部(底端)輸出表。內部輪回逐行處置內部輸出表。外部輪回會針對每一個內部行履行,在外部輸出表中搜刮婚配行。可以用上面的偽碼來懂得:
foreach(row r1 in outer table)
foreach(row r2 in inner table)
if( r1, r2 相符婚配前提 )
output(r1, r2);
最簡略的情形是,搜刮時掃描全部表或索引;這稱為“純真嵌套輪回聯接”。假如搜刮時應用索引,則稱為“索引嵌套輪回聯接”。假如將索引生成為查詢籌劃的一部門(並在查詢完成後立刻將索引損壞),則稱為“暫時索引嵌套輪回聯接”。查詢優化器斟酌了一切這些分歧情形。
假如內部輸出較小而外部輸出較年夜且事後創立了索引,則嵌套輪回聯接特別有用。在很多大事務中(如那些只影響較小的一組行的事務),索引嵌套輪回聯接優於歸並聯接和哈希聯接。但在年夜型查詢中,嵌套輪回聯接平日不是最好選擇。
2. 【Merge Join】,假如兩個聯接輸出其實不小但已在兩者聯接列上排序(例如,假如它們是經由過程掃描已排序的索引取得的),則歸並聯接是最快的聯接操作。假如兩個聯接輸出都很年夜,並且這兩個輸出的年夜小差不多,則事後排序的歸並聯接供給的機能與哈希聯接鄰近。然則,假如這兩個輸出的年夜小相差很年夜,則哈希聯接操作平日快很多。
歸並聯接請求兩個輸出都在歸並列上排序,而歸並列由聯接謂詞的等效 (ON) 子句界說。平日,查詢優化器掃描索引(假如在恰當的一組列上存在索引),或在歸並聯接的上面放一個排序運算符。在少少數情形下,固然能夠有多個等效子句,但只用個中一些可用的等效子句取得歸並列。
因為每一個輸出都已排序,是以 Merge Join 運算符將從每一個輸出獲得一行並將其停止比擬。例如,關於內聯接操作,假如行相等則前往。假如行不相等,則放棄值較小的行並從該輸出取得另外一行。這一進程將反復停止,直隨處理完一切的行動止。
歸並聯接操作可所以慣例操作,也能夠是多對多操作。多對多歸並聯接應用暫時表存儲行(會影響效力)。假如每一個輸出中有反復值,則在處置個中一個輸出中的每一個反復項時,另外一個輸出必需重繞到反復項的開端地位。 可以創立獨一索引告知SQL Server不會有反復值。
假如存在駐留謂詞,則一切知足歸並謂詞的行都將對該駐留謂詞取值,而只前往那些知足該駐留謂詞的行。
歸並聯接自己的速度很快,但假如須要排序操作,選擇歸並聯接就會異常費時。但是,假如數據量很年夜且可以或許從現有 B 樹索引中取得預排序的所需數據,則歸並聯接平日是最快的可用聯接算法。
3. 【Hash Join】,哈希聯接可以有用處置未排序的年夜型非索引輸出。它們對龐雜查詢的中央成果很有效,由於: 1. 中央成果未經索引(除非曾經顯式保留到磁盤上然後創立索引),並且平日不為查詢籌劃中的下一個操作停止恰當的排序。 2. 查詢優化器只估量中央成果的年夜小。因為關於龐雜查詢,估量能夠有很年夜的誤差,是以假如中央成果比預期的年夜很多,則處置中央成果的算法不只必需有用並且必需過度弱化。
哈希聯接可以削減應用非標准化。非標准化普通經由過程削減聯接操作取得更好的機能,雖然如許做有冗余之險(如紛歧致的更新)。哈希聯接則削減應用非標准化的須要。哈希聯接使垂直分區(用零丁的文件或索引代表單個表中的幾組列)得以成為物理數據庫設計的可行選項。
哈希聯接有兩種輸出:生成輸出和探測輸出。查詢優化器指派這些腳色,使兩個輸出中較小的誰人作為生成輸出。
哈希聯接用於多種設置婚配操作:外部聯接;左內部聯接、右內部聯接和完整內部聯接;左半聯接和右半聯接;交集;結合和差別。另外,哈希聯接的某種變形可以停止反復刪除和分組,例如 SUM(salary) GROUP BY department。這些修正對生成和探測腳色只應用一個輸出。
哈希聯接又分為3個類型:內存中的哈希聯接、Grace 哈希聯接和遞歸哈希聯接。
內存中的哈希聯接:哈希聯接先掃描或盤算全部生成輸出,然後在內存中生成哈希表。依據盤算得出的哈希鍵的哈希值,將每行拔出哈希存儲桶。假如全部生成輸出小於可用內存,則可以將一切行都拔出哈希表中。生成階段以後是探測階段。一次一行地對全部探測輸出停止掃描或盤算,並為每一個探測行盤算哈希鍵的值,掃描響應的哈希存儲桶並生成婚配項。
Grace 哈希聯接:假如生成輸出年夜於內存,哈希聯接將分為幾步停止。這稱為“Grace 哈希聯接”。每步都分為生成階段和探測階段。起首,消費全部生成和探測輸出並將其分區(應用哈希鍵上的哈希函數)為多個文件。對哈希鍵應用哈希函數可以包管隨意率性兩個聯接記載必定位於雷同的文件對中。是以,聯接兩個年夜輸出的義務簡化為雷同義務的多個較小的實例。然後將哈希聯策應用於每對分區文件。
遞歸哈希聯接:假如生成輸出異常年夜,以致於尺度內部歸並的輸出須要多個歸並級別,則須要多個分區步調和多個分區級別。假如只要某些分區較年夜,則只需對那些分區應用附加的分區步調。為了使一切分區步調盡量快,將應用年夜的異步 I/O 操作以便單個線程就可以使多個磁盤驅動器忙碌任務。
在優化進程中不克不及一直肯定應用哪一種哈希聯接。是以,SQL Server 開端時應用內存中的哈希聯接,然後依據生成輸出的年夜小逐步轉換到 Grace 哈希聯接和遞歸哈希聯接。
假如優化器毛病地估計兩個輸出中哪一個較小並由此肯定哪一個作為生成輸出,生成腳色和探測腳色將靜態反轉。哈希聯接確保應用較小的溢出文件作為生成輸出。這一技巧稱為“腳色反轉”。至多一個文件溢出到磁盤後,哈希聯接中才會產生腳色反轉。
解釋:您也能夠顯式的指定聯接方法,SQL Server會盡可能尊敬您的選擇。好比你可以如許寫:inner loop join, left outer merge join, inner hash join
然則,我照樣建議您不要如許做,由於SQL Server的選擇根本上都是准確的,不信您可以試一下。
好了,說了一年夜堆實際器械,再來個現實的例子說明一下吧。
回到頂部更詳細履行進程
後面,我給出一張圖片,它反應了SQL Server在履行某個查詢的履行籌劃,但它反應的信息能夠不太過細,固然,您可以把鼠標目標挪動某個節點上,會有以下信息湧現:

恰好,我裝的是中文版的,下面都是漢字,我也不多說了。我要說的是另外一種方法的履行進程,比這個包括更多的履行信息, 並且是現實的履行情形。(固然,您也能夠持續應用圖形方法,在運轉查詢前點擊對象欄上的【包含現實的履行籌劃】按鈕)
讓我們再次回到【SQL Server Management Studio】,輸出以下語句,然後履行。
set statistics profile on select v.OrderID, v.CustomerID, v.CustomerName, v.OrderDate, v.SumMoney, v.Finished from OrdersView as v where v.OrderDate >= '2010-12-1' and v.OrderDate < '2011-12-1';
留意:如今加了一句,【set statistics profile on 】,獲得的成果以下:
可以從圖片上看到,履行查詢後,獲得二個表格,下面的表格顯示了查詢的成果,上面的表格顯示了查詢的履行進程。比擬本文的第一張圖片, 這張圖片能夠在直不雅上不太友愛,然則,它能反應更多的信息,並且特別在比擬龐雜的查詢時,能夠看起來更輕易,由於關於龐雜的查詢,【履行籌劃】的步調太多,圖形方法會形成圖形過年夜,不輕易不雅察。 並且這張履行進程表格能反應2個很有價值的數據(前二列)。
照樣來看看這個【履行進程表格】吧。我來挑幾個主要的說一下。
【Rows】:表現在一個履行步調中,所發生的記載條數。(真實數據,非預期)
【Executes】:表現某個履行步調被履行的次數。(真實數據,非預期)
【Stmt Text】:表現要履行的步調的描寫。
【EstimateRows】:表現要預期前往若干行數據。
在這個【履行進程表格】中,關於優化查詢來講,我以為前三列是比擬主要的。關於前二列,我下面也說明了,意思也很清晰。 前二列的數字也年夜致反應了那些步調所花的本錢,關於比擬慢的查詢中,應當留心它們。 【Stmt Text】會告知你每一個步調做了甚麼工作。關於這類表格,它所要表達的實際上是一種樹型信息(一行就表現在圖形方法下的一個節點), 所以,我建議從最內層開端去讀它們。做為示例,我來說明一下這張表格它所表達的履行進程。
第5行:【Clustered Index Seek(OBJECT:([MyNorthwind].[dbo].[Customers].[PK_Customers]), SEEK:([MyNorthwind].[dbo].[Customers].[CustomerID]=[MyNorthwind].[dbo].[Orders].[CustomerID]) ORDERED FORWARD)】, 意思是說,SQL Server在對表Customers做Seek操作,並且是依照【Clustered Index Seek】的方法,對應的索引是【PK_Customers】,seek的值起源於[Orders].[CustomerID]
第4行:【Clustered Index Scan(OBJECT:([MyNorthwind].[dbo].[Orders].[PK_Orders]), WHERE:([MyNorthwind].[dbo].[Orders].[OrderDate]>='2010-12-01 00:00:00.000' AND [MyNorthwind].[dbo].[Orders].[OrderDate]<'2011-12-01 00:00:00.000'))】, 意思是說,SQL Server在對表Customers做Scan操作,即:最差的【表掃描】的方法,緣由是,OrderDate列上沒有索引,所以只能如許了。
第3行:【Nested Loops(Left Outer Join, OUTER REFERENCES:([MyNorthwind].[dbo].[Orders].[CustomerID]))】, 意思是說,SQL Server把第5行和第4行發生的數據用【Nested Loops】的方法聯接起來,個中Outer表是Orders,要聯接的婚配操作也在第5行中指出了。
第2行:【Compute Scalar(DEFINE:([Expr1006]=isnull([MyNorthwind].[dbo].[Customers].[CustomerName],N'')))】, 意思是說,要履行一個isnull()函數的挪用。詳細緣由請參考本文前部門中給出視圖界說代碼。
第1行:【SELECT [v].[OrderID],[v].[CustomerID],[v].[CustomerName],[v].[OrderDate],[v].[SumMoney],[v].[Finished] FROM [OrdersView] [v] WHERE [v].[OrderDate]>=@1 AND [v].[OrderDate]<@2】, 平日第1行就是全部查詢,表現它的前往值。
回到頂部索引統計信息:查詢籌劃的選擇根據
後面一向說到【履行籌劃】,既然是籌劃,就表現要在詳細履行前就可以肯定上去的操作計劃。那末SQL Server是若何選擇一個履行籌劃的呢? SQL Server怎樣曉得甚麼時刻該用索引或許用哪一個索引呢? 關於SQL Server來講,每當要履行一個查詢時,都要起首檢討這個查詢的履行籌劃能否存在緩存中,假如沒有,就要生成一個履行籌劃, 詳細在發生履行籌劃時,其實不是看有哪些索引可用(隨機選擇),而是會參考一種被稱為【索引統計信息】的數據。 假如您細心地看一下後面的履行籌劃或許履行進程表格,會發明SQL Server能預估每一個步調所發生的數據量, 恰是由於SQL Server能預估這些數據量,SQL Server能力選擇一個它以為最適合的辦法去履行查詢進程, 此時【索引統計信息】就可以告知SQL Server這些信息。 說到這裡,您是否是有點獵奇呢,為了讓您對【索引統計信息】有個理性的熟悉,我們來看看【索引統計信息】是個甚麼模樣的。 請在【SQL Server Management Studio】,輸出以下語句,然後履行。
dbcc show_statistics (Products, IX_CategoryID)
獲得的成果以下圖:
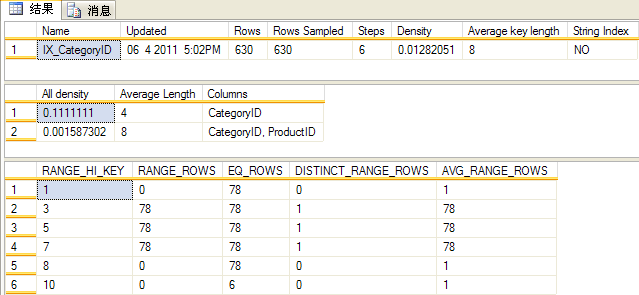
起首,照樣說明一下敕令:【dbcc show_statistics】這個敕令可以顯示我們想曉得的【索引統計信息】,它須要二個參數,1. 表名,2. 索引名
再來看看敕令的成果,它有三個表格構成:
1. 第一個表格,它列出了這個索引統計信息的重要信息。
2. 第二個表格,它列出各類字段組合的選擇性,數據越小表現反復越性越小,固然選擇性也就越高。
3. 第三個表格,數據散布的直方圖,SQL Server就是靠它預估一些履行步調的數據量。
為了能讓您更好的懂得這些數據,特別是第三組,請看下圖:
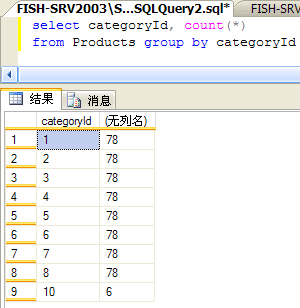
其時我在填充測試數據時,有意把CategoryId分為1到8(10是後光降時加的),每組填充了78條數據。所以【索引統計信息】的第三個表格的數據也都是准確的, 也恰是依據這些統計信息,SQL Server能力對每一個履行步調預估響應的數據量,從而影響Join之類的選擇。固然了,在選擇Join方法時, 也要參考第二個表格中字段的選擇性。SQL Server在為查詢生成履行籌劃時, 查詢優化器將應用這些統計信息並聯合相干的索引來評價每種計劃的開支來選擇最好的查詢籌劃。
再來個例子解釋一下統計信息關於查詢籌劃的主要性。起首多加點數據,請看以下代碼:
declare @newCategoryId int; insert into dbo.Categories (CategoryName) values(N'Test statistics'); set @newCategoryId = scope_identity(); declare @count int; set @count = 0; while( @count < 100000 ) begin insert into Products (ProductName, CategoryID, Unit, UnitPrice, Quantity, Remark) values( cast(newid() as nvarchar(50)), @newCategoryId, N'個', 100, @count +1, N''); set @count = @count + 1; end go update statistics Products; go
再來看看索引統計信息:

再來看看統一個查詢,但由於查詢參數值分歧時,SQL Server選擇的履行籌劃:
select p.ProductId, t.Quantity from Products as p left outer join [Order Details] as t on p.ProductId = t.ProductId where p.CategoryId = 26; -- 26 就是最新發生的CategoryId,是以這個查詢會前往10W筆記錄 select p.ProductId, t.Quantity from Products as p left outer join [Order Details] as t on p.ProductId = t.ProductId where p.CategoryId = 6; -- 這個查詢會前往95筆記錄
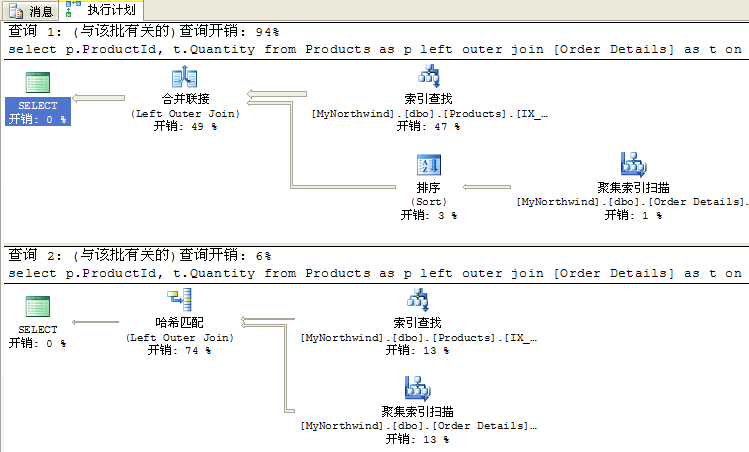
從上圖可以看出,因為CategoryId的參數值分歧,SQL Server會選擇完整分歧的履行籌劃。統計信息主要性在這裡表現的很清晰吧。
創立統計信息後,數據庫引擎對列值(依據這些值創立統計信息)停止排序, 並依據這些值(最多 200 個,按距離分離隔)創立一個“直方圖”。直方圖指定有若干行准確婚配每一個距離值, 有若干行在距離規模內,和距離中值的密度年夜小或反復值的產生率。
SQL Server 2005 引入了對 char、varchar、varchar(max)、nchar、nvarchar、nvarchar(max)、text 和 ntext 列創立的統計信息搜集的其他信息。這些信息稱為“字符串摘要”,可以贊助查詢優化器估量字符串形式中查詢謂詞的選擇性。 查詢中有 LIKE 前提時,應用字符串摘要可以更精確地估量成果集年夜小,其實不斷優化查詢籌劃。 這些前提包含諸如 WHERE ProductName LIKE '%Bike' 和 WHERE Name LIKE '[CS]heryl' 之類的前提。
既然【索引統計信息】這麼主要,那末它會在甚麼時刻生成或許更新呢?現實上,【索引統計信息】是不消我們手工去保護的, SQL Server會主動去保護它們。並且在SQL Server中也有個參數來掌握這個更新方法:
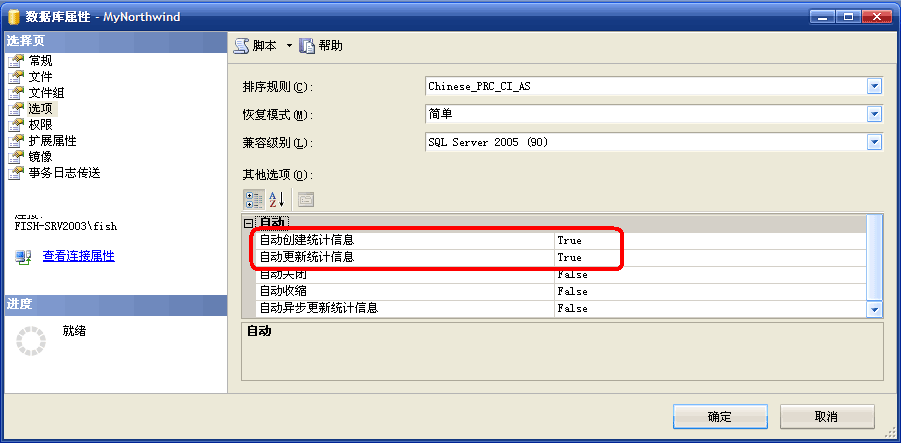
統計信息主動功效任務方法
創立索引時,查詢優化器主動存儲有關索引列的統計信息。別的,當 AUTO_CREATE_STATISTICS 數據庫選項設置為 ON(默許值)時, 數據庫引擎主動為沒有效於謂詞的索引的列創立統計信息。
跟著列中數據產生變更,索引和列的統計信息能夠會過時,從而招致查詢優化器選擇的查詢處置辦法不是最好的。 例如,假如創立一個包括一個索引列和 1,000 行數據的表,每行在索引列中的值都是獨一的, 則查詢優化器將把該索引列視為搜集查詢數據的好辦法。假如更新列中的數據後存在很多反復值, 則該列不再是用於查詢的幻想候選列。然則,查詢優化器依然依據索引的過時散布統計信息(基於更新前的數據),將其視為好的候選列。
當 AUTO_UPDATE_STATISTICS 數據庫選項設置為 ON(默許值)時,查詢優化器會在表中的數據產生變更時主動按期更新這些統計信息。 每當查詢履行籌劃中應用的統計信息沒有經由過程針對以後統計信息的測試時就會啟動統計信息更新。 采樣是在各個數據頁上隨機停止的,取自表或統計信息所需列的最小非集合索引。 從磁盤讀取一個數據頁後,該數據頁上的一切行都被用來更新統計信息。 慣例情形是:在年夜約有 20% 的數據行產生變更時更新統計信息。然則,查詢優化器一直確保采樣的行數盡可能少。 關於小於 8 MB 的表,則一直停止完全掃描來搜集統計信息。
采樣數據(而不是剖析一切數據)可以將統計信息主動更新的開支降至最低。 在某些情形下,統計采樣沒法取得表中數據的准確特點。可使用 UPDATE STATISTICS 語句的 SAMPLE 子句和 FULLSCAN 子句, 掌握按逐一表的方法手動更新統計信息時采樣的數據量。FULLSCAN 子句指定掃描表中的一切數據來搜集統計信息, 而 SAMPLE 子句用來指定采樣的行數百分比或采樣的行數
在 SQL Server 2005 中,數據庫選項 AUTO_UPDATE_STATISTICS_ASYNC 供給了統計信息異步更新功效。 當此選項設置為 ON 時,查詢不期待統計信息更新,便可停止編譯。而過時的統計信息置於隊列中, 由後台過程中的任務線程來更新。查詢和任何其他並發查詢都經由過程應用現有的過時統計信息立刻編譯。 因為不存在期待更新後的統計信息的延遲,是以查詢呼應時光可猜測;然則過時的統計信息能夠招致查詢優化器選擇低效的查詢籌劃。 在更新後的統計信息停當後啟動的查詢將應用那些統計信息。這能夠會招致從新編譯緩存的籌劃(取決於較舊的統計信息版本)。 假如在統一個顯式用戶事務中湧現某些數據界說說話 (DDL) 語句(例如,CREATE、ALTER 和 DROP 語句),則沒法更新異步統計信息。
AUTO_UPDATE_STATISTICS_ASYNC 選項設置於數據庫級別,並肯定用於數據庫中一切統計信息的更新辦法。 它只實用於統計信息更新,而沒法用於以異步方法創立統計信息。只要將 AUTO_UPDATE_STATISTICS 設置為 ON 時, 將此選項設置為 ON 才有用。默許情形下,AUTO_UPDATE_STATISTICS_ASYNC 選項設置為 OFF。
從以上解釋中,我們可以看出,關於年夜表,照樣有能夠存在統計信息更新不實時的時刻,這時候,便可能會影響查詢優化器的斷定了。
有些人能夠有個經歷:關於一些慢的查詢,他們會想到重建索引來測驗考試處理。其實如許做是有事理的。 由於,在某些時刻一個查詢忽然變慢了,能夠和統計信息更新不實時有關,進而會影響查詢優化器的斷定。 假如此時重建索引,便可以讓查詢優化器曉得最新的數據散布,天然便可以避開這個成績。 還記得我後面用【set statistics profile on】顯示的履行進程表格嗎?留意哦,誰人表格就顯示每一個步調的現實數據量和預估的數據量。要不要重建索引,其實我們可以用【set statistics profile on】來看一下,假如現實數據量和預估的數據量的差值比擬年夜, 那末我們可以斟酌手工去更新統計信息,然後再去嘗嘗。
回到頂部優化視圖查詢
再來講說優化視圖查詢,固然視圖也是由一個查詢語句界說的,實質上也是一個查詢,但它和普通的查詢語句在優化時,照樣有所差別的。 這裡重要的差別在於,視圖固然是由一個查詢語句界說的,但假如只去剖析這個查詢界說,能夠獲得的意義不年夜,由於視圖多半時刻就不是直接應用, 而是在應用前,會加上where語句,或許放在其它語句中供from子句所應用。上面照樣舉個例子吧,在我的演示數據庫中有個視圖OrdersView,界說代碼後面有。 我們來看看,假如直接應用這個視圖,會有甚麼樣的履行籌劃出來:

從這個視圖可以看出,SQL Server會對表Orders做全表掃描,應當是很低效的。再來看看上面這個查詢:
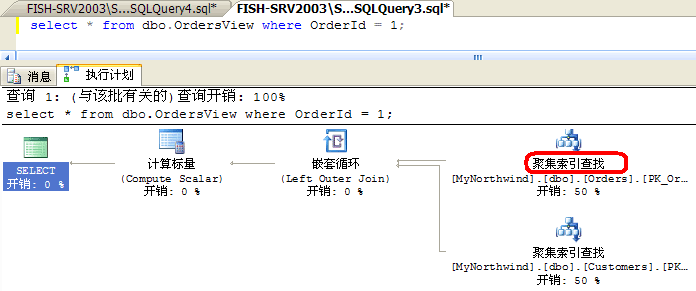
從這個履行籌劃可以看出,與下面誰人就紛歧樣了。前一個查詢中對Orders表的查找是應用【Clustered Index Scan】的方法, 而如今在應用【Clustered Index Seek】的方法了,最左邊二個步調的本錢的百分比也產生了轉變。如許就足以解釋,優化視圖時, 最好能依據現實需求,運用分歧的過濾前提,再來決議若何去優化。
再來一個由三個查詢構成的情形來看看這個視圖的履行籌劃。
select * from dbo.OrdersView where OrderId = 1; select * from dbo.OrdersView where CustomerId = 1; select * from dbo.OrdersView where OrderDate >= '2010-12-1' and OrderDate < '2011-12-1';

很顯著,關於統一個視圖,在分歧的過濾前提下,履行籌劃的差異很顯著。
推舉浏覽-MSDN文章
索引統計信息
http://msdn.microsoft.com/zh-cn/library/ms190397(SQL.90).aspx
查詢優化建議
http://msdn.microsoft.com/zh-cn/library/ms188722(SQL.90).aspx
用於對運轉慢的查詢停止剖析的清單
http://msdn.microsoft.com/zh-cn/library/ms177500(SQL.90).aspx
邏輯運算符和物理運算符援用
http://msdn.microsoft.com/zh-cn/library/ms191158(SQL.90).aspx