sql2000報錯Successfully re-opened the local eventlog處理辦法。本站提示廣大學習愛好者:(sql2000報錯Successfully re-opened the local eventlog處理辦法)文章只能為提供參考,不一定能成為您想要的結果。以下是sql2000報錯Successfully re-opened the local eventlog處理辦法正文
比來,我參加了Cloudera,在這之前,我在盤算生物學/基因組學上曾經任務了差不多10年。我的剖析任務重要是應用Python說話和它很棒的迷信盤算棧來停止的。但Apache Hadoop的生態體系年夜部門都是用Java來完成的,也是為Java預備的,這讓我很末路火。所以,我的優等年夜事項成了尋覓一些Python可以用的Hadoop框架。
在這篇文章裡,我會把我小我對這些框架的一些有關迷信的意見寫上去,這些框架包含:
終究,在我的看來,Hadoop的數據流(streaming)是最快也是最通明的選項,並且最合適於文本處置。mrjob最合適於在Amazon EMR上疾速任務,然則會有明顯的機能喪失。dumbo 關於年夜多半龐雜的任務都很便利(對象作為鍵名(key)),然則依然比數據流(streaming)要慢。
請持續往下浏覽,以懂得完成細節,機能和功效的比擬。
一個風趣的成績
為了測試分歧的框架,我們不會做“統計詞數”的試驗,轉而去轉化谷歌圖書N-元數據。 N-元朝表一個n個詞組成的元組。這個n-元數據集供給了谷歌圖書文集中以年份分組的一切1-,2-,3-,4-,5-元記載的統計數量。 在這個n-元數據集中的每行記載都由三個域組成:n-元,年份,不雅測次數。(您可以或許在http://books.谷歌.com/ngrams獲得數據)。
我們願望去匯總數據以不雅測統計任何一對互相鄰近的詞組合所湧現的次數,並以年份分組。試驗成果將使我們可以或許斷定出能否有詞組合在某一年中比正常情形湧現的更加頻仍。假如統計時,有兩個詞在四個詞的間隔內湧現過,那末我們界說兩個詞是“鄰近”的。 或等價地,假如兩個詞在2-,3-或許5-元記載中湧現過,那末我們也界說它們是”鄰近“的。 一次,試驗的終究產品會包括一個2-元記載,年份和統計次數。
有一個奧妙的處所必需強調。n-元數據集中每一個數據的值都是經由過程全部谷歌圖書語料庫來盤算的。從道理下去說,給定一個5-元數據集,我可以經由過程簡略地聚合准確的n-元來盤算出4-元、3-元和2-元數據集。例如,當5-元數據集包括
(the, cat, in, the, hat) 1999 20 (the, cat, is, on, youtube) 1999 13 (how, are, you, doing, today) 1986 5000
時,我們可以將它聚合為2-元數據集以得出以下記載
(the, cat) 1999 33 // 也就是, 20 + 13
但是,現實運用中,只要在全部語料庫中湧現了40次以上的n元組才會被統計出去。所以,假如某個5元組達不到40次的阈值,那末Google也供給構成這個5元組的2元組數據,這個中有一些也許可以或許到達阈值。出於這個緣由,我們用相鄰詞的二元數據,隔一個詞的三元組,隔兩個詞的四元組,以此類推。換句話說,與給定二元組比擬,三元組多的只是最外層的詞。除對能夠的稀少n元數據更敏感,只用n元組最外層的詞還有助於防止反復盤算。總的來講,我們將在2元、3元、4元和5元數據集長進行盤算。
MapReduce的偽代碼來完成這個處理計劃相似如許:
def map(record): (ngram, year, count) = unpack(record) // 確保word1為字典第一個字 (word1, word2) = sorted(ngram[first], ngram[last]) key = (word1, word2, year) emit(key, count) def reduce(key, values): emit(key, sum(values))
硬件
這些MapReduce組件在一個年夜約20GB的隨機數據子集上履行。完全的數據集涵蓋1500個文件;我們用這個劇本拔取一個隨機子集。文件名堅持完全,這一點相當主要,由於文件名肯定了數據塊的n-元中n的值。
Hadoop集群包括5個應用CentOS 6.2 x64的虛擬節點,每一個都有4個CPU,10GB RAM,100GB硬盤容量,而且運轉CDH4。集群每次可以或許履行20個並交運算,每一個組件可以或許履行10個加速器。
集群上運轉的軟件版本以下:
Hadoop:2.0.0-cdh4.1.2 Python:2.6.6 mrjob:0.4-dev dumbo:0.21.36 hadoopy:0.6.0 pydoop:0.7(PyPI)庫中包括最新版本 java:1.6
完成
年夜多半Python框架都封裝了Hadoop Streaming,還有一些封裝了Hadoop Pipes,也有些是基於本身的完成。上面我會分享一些我應用各類Python對象來寫Hadoop jobs的經歷,並會附上一份機能和特色的比擬。我比擬感興致的特色是易於上手和運轉,我不會去優化某個零丁的軟件的機能。
在處置每個數據集的時刻,都邑有一些破壞的記載。關於每筆記錄,我們要檢討能否有錯並辨認毛病的品種,包含缺乏字段和毛病的N元年夜小。關於後一種情形,我們必需曉得記載地點的文件名以便肯定該有的N元年夜小。
一切代碼可以從 GitHub 取得。
Hadoop Streaming
Hadoop Streaming 供給了應用其他可履行法式來作為Hadoop的mapper或許reduce的方法,包含尺度Unix對象和Python劇本。這個法式必需應用劃定的語義從尺度輸出讀取數據,然後將成果輸入到尺度輸入。直接應用Streaming 的一個缺陷是當reduce的輸出是按key分組的時刻,依然是一行行迭代的,必需由用戶來辨識key與key之間的界線。
上面是mapper的代碼:
#! /usr/bin/env python
import os
import re
import sys
# determine value of n in the current block of ngrams by parsing the filename
input_file = os.environ['map_input_file']
expected_tokens = int(re.findall(r'([\d]+)gram', os.path.basename(input_file))[0])
for line in sys.stdin:
data = line.split('\t')
# perform some error checking
if len(data) < 3:
continue
# unpack data
ngram = data[0].split()
year = data[1]
count = data[2]
# more error checking
if len(ngram) != expected_tokens:
continue
# build key and emit
pair = sorted([ngram[0], ngram[expected_tokens - 1]])
print >>sys.stdout, "%s\t%s\t%s\t%s" % (pair[0], pair[1], year, count)
上面是reducer:
#! /usr/bin/env python
import sys
total = 0
prev_key = False
for line in sys.stdin:
data = line.split('\t')
curr_key = '\t'.join(data[:3])
count = int(data[3])
# found a boundary; emit current sum
if prev_key and curr_key != prev_key:
print >>sys.stdout, "%s\t%i" % (prev_key, total)
prev_key = curr_key
total = count
# same key; accumulate sum
else:
prev_key = curr_key
total += count
# emit last key
if prev_key:
print >>sys.stdout, "%s\t%i" % (prev_key, total)
Hadoop流(Streaming)默許用一個tab字符朋分健(key)和值(value)。由於我們也用tab字符朋分了各個域(field),所以我們必需經由過程傳遞給Hadoop上面三個選項來告知它我們數據的健(key)由前三個域組成。
-jobconf stream.num.map.output.key.fields=3 -jobconf stream.num.reduce.output.key.fields=3
要履行Hadoop義務敕令
hadoop jar /usr/lib/hadoop-0.20-mapreduce/contrib/streaming/hadoop-streaming-2.0.0-mr1-cdh4.1.2.jar \
-input /ngrams \
-output /output-streaming \
-mapper mapper.py \
-combiner reducer.py \
-reducer reducer.py \
-jobconf stream.num.map.output.key.fields=3 \
-jobconf stream.num.reduce.output.key.fields=3 \
-jobconf mapred.reduce.tasks=10 \
-file mapper.py \
-file reducer.py
留意,mapper.py和reducer.py在敕令中湧現了兩次,第一次是告知Hadoop要履行著兩個文件,第二次是告知Hadoop把這兩個文件分發給集群的一切節點。
Hadoop Streaming 的底層機制很簡略清楚。與此相反,Python以一種不通明的方法履行他們本身的序列化/反序列化,而這要消費更多的資本。 並且,假如Hadoop軟件曾經存在,Streaming就可以運轉,而不須要再在下面設置裝備擺設其他的軟件。更不消說還能傳遞Unix 敕令或許Java類稱號作 mappers/reducers了。
Streaming缺陷是必需要手工操作。用戶必需本身決議若何將對象轉化為為成鍵值對(好比JSON 對象)。關於二進制數據的支撐也欠好。並且如下面說過的,必需在reducer手工監控key的界限,這很輕易失足。
mrjob
mrjob是一個開放源碼的Python框架,封裝Hadoop的數據流,並積極開辟Yelp的。因為Yelp的運作完整在亞馬遜收集辦事,mrjob的整合與EMR是使人難以相信的滑膩和輕易(應用 boto包)。
mrjob供給了一個Python的API與Hadoop的數據流,並許可用戶應用任何對象作為鍵和映照器。默許情形下,這些對象被序列化為JSON對象的外部,但也有支撐pickle的對象。有無其他的二進制I / O格局的開箱即用,但有一個機制來完成自界說序列化。
值得留意的是,mrjob仿佛成長的異常快,並有很好的文檔。
一切的Python框架,看起來像偽代碼完成:
#! /usr/bin/env python
import os
import re
from mrjob.job import MRJob
from mrjob.protocol import RawProtocol, ReprProtocol
class NgramNeighbors(MRJob):
# mrjob allows you to specify input/intermediate/output serialization
# default output protocol is JSON; here we set it to text
OUTPUT_PROTOCOL = RawProtocol
def mapper_init(self):
# determine value of n in the current block of ngrams by parsing filename
input_file = os.environ['map_input_file']
self.expected_tokens = int(re.findall(r'([\d]+)gram', os.path.basename(input_file))[0])
def mapper(self, key, line):
data = line.split('\t')
# error checking
if len(data) < 3:
return
# unpack data
ngram = data[0].split()
year = data[1]
count = int(data[2])
# more error checking
if len(ngram) != self.expected_tokens:
return
# generate key
pair = sorted([ngram[0], ngram[self.expected_tokens - 1]])
k = pair + [year]
# note that the key is an object (a list in this case)
# that mrjob will serialize as JSON text
yield (k, count)
def combiner(self, key, counts):
# the combiner must be separate from the reducer because the input
# and output must both be JSON
yield (key, sum(counts))
def reducer(self, key, counts):
# the final output is encoded as text
yield "%s\t%s\t%s" % tuple(key), str(sum(counts))
if __name__ == '__main__':
# sets up a runner, based on command line options
NgramNeighbors.run()
mrjob只須要裝置在客戶機上,個中在功課的時刻提交。上面是要運轉的敕令:
export HADOOP_HOME="/usr/lib/hadoop-0.20-mapreduce" ./ngrams.py -r hadoop --hadoop-bin /usr/bin/hadoop --jobconf mapred.reduce.tasks=10 -o hdfs:///output-mrjob hdfs:///ngrams
編寫MapReduce的任務長短常直不雅和簡略的。但是,有一個嚴重的外部序列化籌劃所發生的本錢。最有能夠的二進制籌劃將須要完成的用戶(例如,為了支撐typedbytes)。也有一些內置的適用法式日記文件的解析。最初,mrjob許可用戶寫多步調的MapReduce的任務流程,在那邊從一個MapReduce功課的中央輸入被主動用作輸出到另外一個MapReduce任務。
(注:其他的完成都異常類似,除包詳細的完成,他們都能被找到here.。)
dumbo
dumbo 是別的一個應用Hadoop流包裝的框架。dumbo湧現的較早,本應當被很多人應用,但因為缺乏文檔,形成開辟艱苦。這也是不如mcjob的一點。
dumbo經由過程typedbytes履行序列化,能許可更簡練的數據傳輸,也能夠更天然的經由過程指定JavaInputFormat讀取SequenceFiles或許其他格局的文件,好比,dumbo也能夠履行Python的egg和Java的JAR文件。
在我的印象中, 我必需要手動裝置dumbo中的每個節點, 它只要在typedbytes和dumbo以eggs情勢創立的時刻能力運轉。 就像他會由於onMemoryErrors終止一樣,他也會由於應用組合器停滯。
運轉dumbo義務的代碼是:
dumbo start ngrams.py \
-hadoop /usr \
-hadooplib /usr/lib/hadoop-0.20-mapreduce/contrib/streaming \
-numreducetasks 10 \
-input hdfs:///ngrams \
-output hdfs:///output-dumbo \
-outputformat text \
-inputformat text
hadoopy
hadoopy 是別的一個兼容dumbo的Streaming封裝。異樣,它也應用typedbytes序列化數據,並直接把 typedbytes 數據寫到HDFS。
它有一個很棒的調試機制, 在這類機制下它可以直接把新聞寫到尺度輸入而不會攪擾Streaming進程。它和dumbo很類似,但文檔要好很多。文檔中還供給了與 Apache HBase整合的內容。
用hadoopy的時刻有兩種發發來啟動jobs:
必需在Python法式中啟動hadoopy job,它沒有內置的敕令行對象。
我寫了一個劇本經由過程launch_frozen的方法啟動hadoopy
python launch_hadoopy.py
用launch_frozen運轉以後,我在每一個節點上都裝置了hadoopy然後用launch辦法又運轉了一遍,機能顯著好很多。
pydoop
與其他框架比擬,pydoop 封裝了Hadoop的管道(Pipes),這是Hadoop的C++ API。 正由於此,該項目宣稱他們可以或許供給加倍豐碩的Hadoop和HDFS接口,和一樣好的機能。我沒有驗證這個。然則,有一個利益是可以用Python完成一個Partitioner,RecordReader和RecordWriter。一切的輸出輸入都必需是字符串。
最主要的是,我不克不及勝利的從PIP或許源代碼構建pydoop。
其他
當地java
最初,我應用新的Hadoop Java API接話柄施了MR義務,編譯完成後,如許來運轉它:
hadoop jar /root/ngrams/native/target/NgramsComparison-0.0.1-SNAPSHOT.jar NgramsDriver hdfs:///ngrams hdfs:///output-native
關於計數器的特殊解釋
在我的MR jobs的最後完成裡,我用計數器來跟蹤監控不良記載。在Streaming裡,須要把信息寫到stderr。現實證實這會帶來不容疏忽的額定開支:Streaming job花的時光是原生java job的3.4倍。這個框架異樣有此成績。
將用Java完成的MapReduce job作為機能基准。 Python框架的值是其絕對於Java的機能目標的比率。

Java顯著最快,,Streaming要多花一半時光,Python框架花的時光更多。從mrjob mapper的profile數據來看,它在序列化/反序列化上消費了年夜量時光。dumbo和hadoopy在這方面要好一點。假如用了combiner 的話dumbo 還可以更快。
特色比擬
年夜多來自各自軟件包中的文檔和代碼庫。
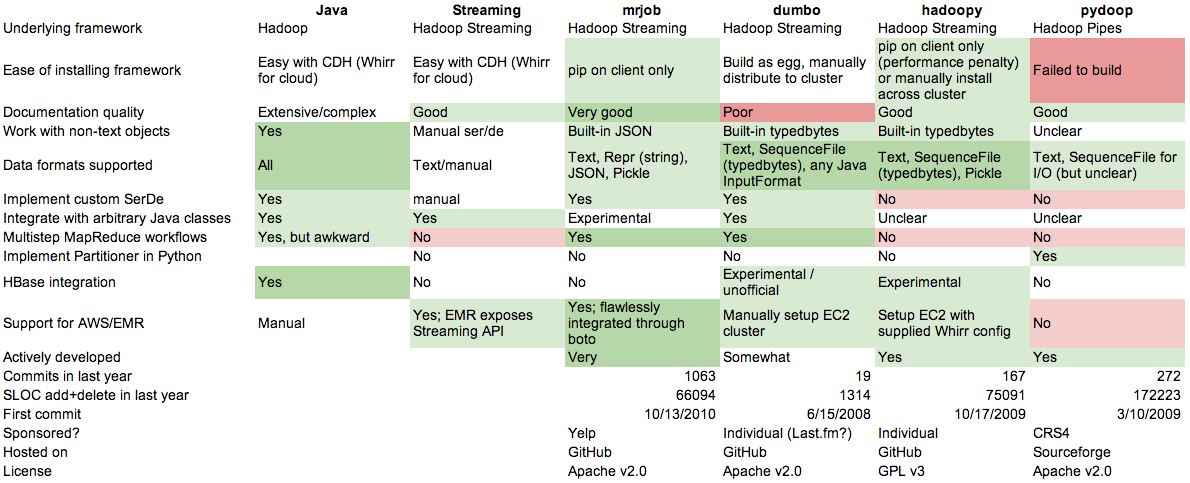
結論
Streaming是最快的Python計劃,這面面沒有任何魔力。然則在用它來完成reduce邏輯的時刻,和有許多龐雜對象的時刻要特殊當心。
一切的Python框架看起來都像是偽碼,這異常棒。
mrjob更新快,成熟的易用,用它來組織多步MapReduce的任務流很輕易,還可以便利地應用龐雜對象。它還可以無縫應用EMR。然則它也是履行速度最慢的。
還有一些不是很風行的 Python 框架,他們的重要優勢是內置了關於二進制格局的支撐,但假如有需要話,這個完整可以由用戶代碼來本身完成。
就今朝來看:
假如你在理論中有本身的熟悉,或是發明本文有毛病,請在答復裡提出。