SqlServer數據庫提醒 “tempdb” 的日記已滿 成績處理計劃。本站提示廣大學習愛好者:(SqlServer數據庫提醒 “tempdb” 的日記已滿 成績處理計劃)文章只能為提供參考,不一定能成為您想要的結果。以下是SqlServer數據庫提醒 “tempdb” 的日記已滿 成績處理計劃正文
Oracle查詢語句
select * from scott.emp ;
1.--dense_rank()剖析函數(查找每一個部分工資最高前三名員工信息)
select * from (select deptno,ename,sal,dense_rank() over(partition by deptno order by sal desc) a from scott.emp) where a<=3 order by deptno asc,sal desc ;
成果:

--rank()剖析函數(運轉成果與上語句雷同)
select * from (select deptno,ename,sal,rank() over(partition by deptno order by sal desc) a from scott.emp ) where a<=3 order by deptno asc,sal desc ;
成果:
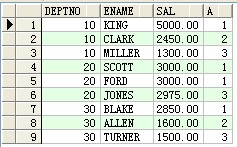
--row_number()剖析函數(運轉成果與上雷同)
select * from(select deptno,ename,sal,row_number() over(partition by deptno order by sal desc) a from scott.emp) where a<=3 order by deptno asc,sal desc ;
--rows unbounded preceding 剖析函數(顯示各部分的積聚工資總和)
select deptno,sal,sum(sal) over(order by deptno asc rows unbounded preceding) 積聚工資總和 from scott.emp ;
成果:
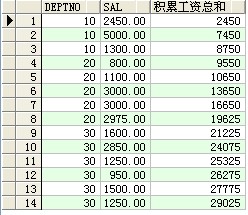
--rows 整數值 preceding(顯示每最初4筆記錄的匯總值)
select deptno,sal,sum(sal) over(order by deptno rows 3 preceding) 每4匯總值 from scott.emp ;
成果:
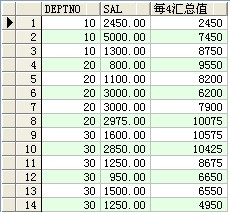
--rows between 1 preceding and 1 following(統計3筆記錄的匯總值【以後記載居中】)
select deptno,ename,sal,sum(sal) over(order by deptno rows between 1 preceding and 1 following) 匯總值 from scott.emp ;
成果:

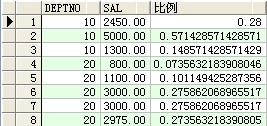
--ratio_to_report(顯示員工工資及占該部分總工資的比例)
select deptno,sal,ratio_to_report(sal) over(partition by deptno) 比例 from scott.emp ;
成果:
--檢查一切用戶
select * from dba_users ;
select count(*) from dba_users ;
select * from all_users ;
select * from user_users ;
select * from dba_roles ;
--檢查用戶體系權限
select * from dba_sys_privs ;
select * from user_users ;
--檢查用戶對象或腳色權限
select * from dba_tab_privs ;
select * from all_tab_privs ;
select * from user_tab_privs ;
--檢查用戶或腳色所具有的腳色
select * from dba_role_privs ;
select * from user_role_privs ;
-- rownum:查詢10至12信息
select * from scott.emp a where rownum<=3 and a.empno not in(select b.empno from scott.emp b where rownum<=9);
成果:

--not exists;查詢emp表在dept表中沒有的數據
select * from scott.emp a where not exists(select * from scott.dept b where a.empno=b.deptno) ;
成果:

--rowid;查詢反復數據信息
select * from scott.emp a where a.rowid>(select min(x.rowid) from scott.emp x where x.empno=a.empno);
--依據rowid來分頁(一萬條數據,查詢10000至9980時光年夜概在0.03秒閣下)
select * from scott.emp where rowid in(select rid from(select rownum rn,rid from(select rowid rid,empno from scott.emp order by empno desc) where rownum<10)where rn>=1)order by empno desc ;
成果:

--依據剖析函數分頁(一萬條數據,查詢10000至9980時光年夜概在1.01秒閣下)
select * from(select a.*,row_number() over(order by empno desc) rk from scott.emp a ) where rk<10 and rk>=1;
成果:

--rownum分頁(一萬條數據,查詢10000至9980時光年夜概在0.01秒閣下)
select * from(select t.*,rownum rn from(select * from scott.emp order by empno desc)t where rownum<10) where rn>=1;
select * from(select a.*,rownum rn from (select * from scott.emp) a where rownum<=10) where rn>=5 ;
--left outer join:左銜接
select a.*,b.* from scott.emp a left outer join scott.dept b on a.deptno=b.deptno ;
--right outer join:右銜接
select a.*,b.* from scott.emp a right outer join scott.dept b on a.deptno=b.deptno ;
--inner join
select a.*,b.* from scott.emp a inner join scott.dept b on a.deptno=b.deptno ;
--full join
select a.*,b.* from scott.emp a full join scott.dept b on a.deptno=b.deptno ;
select a.*,b.* from scott.emp a,scott.dept b where a.deptno(+)=b.deptno ;
select distinct ename,sal from scott.emp a group by sal having ;
select * from scott.dept ;
select * from scott.emp ;
--case when then end (穿插報表)
select ename,sal,case deptno when 10 then '管帳部' when 20 then '研討部' when 30 then '發賣部' else '其他部分' end 部分 from scott.emp ;
成果:

select ename,sal,case when sal>0 and sal<1500 then '一級工資' when sal>=1500 and sal<3000 then '二級工資' when sal>=3000 and sal<4500 then '三級工資' else '四級工資' end 工資品級 from scott.emp order by sal desc ;
成果:

--穿插報表是應用分組函數與case構造一路完成
select 姓名,sum(case 課程 when '數學' then 分數 end)數學,sum(case 課程 when '汗青' then 分數 end)汗青 from 先生 group by 姓名 ;
--decode 函數
select 姓名,sum(decode(課程,'數學',分數,null))數學,sum(decode(課程,'語文',分數,null))語文,sum(decode(課程,'汗青','分數',null))汗青 from 先生 group by 姓名 ;
--level。。。。connect by(條理查詢)
select level,emp.* from scott.emp connect by prior empno = mgr order by level ;
成果:

--sys_connect_by_path函數
select ename,sys_connect_by_path(ename,'/') from scott.emp start with mgr is null connect by prior empno=mgr ;
成果:

--start with connect by prior 語法
select lpad(ename,3*(level),'')姓名,lpad(ename,3*(level),'')姓名 from scott.emp where job<>'CLERK' start with mgr is null connect by prior mgr = empno ;
--level與prior症結字
select level,emp.* from scott.emp start with ename='SCOTT' connect by prior empno=mgr;
select level,emp.* from scott.emp start with ename='SCOTT' connect by empno = prior mgr ;
成果:
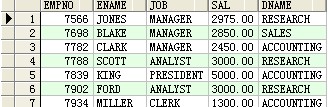
--等值銜接
select empno,ename,job,sal,dname from scott.emp a,scott.dept b where a.deptno=b.deptno and (a.deptno=10 or sal>2500);
成果:
--非等值銜接
select a.ename,a.sal,b.grade from scott.emp a,scott.salgrade b where a.sal between b.losal and b.hisal ;
成果:
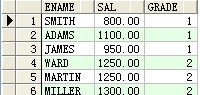
--自銜接
select a.ename,a.sal,b.ename from scott.emp a,scott.emp b where a.mgr=b.empno ;
成果:

--左外銜接
select a.ename,a.sal,b.ename from scott.emp a,scott.emp b where a.mgr=b.empno(+);
成果:

--多表銜接
select * from scott.emp ,scott.dept,scott.salgrade where scott.emp.deptno=scott.dept.deptno and scott.emp.sal between scott.salgrade.losal and scott.salgrade.hisal ;
成果:

select * from scott.emp a join scott.dept b on a.deptno=b.deptno join scott.salgrade s on a.sal between s.losal and s.hisal where a.sal>1000;
select * from(select * from scott.emp a join scott.dept b on a.deptno=b.deptno where a.sal>1000) c join scott.salgrade s on c.sal between s.losal and s.hisal ;
--單行子查詢
select * from scott.emp a where a.deptno=(select deptno from scott.dept where loc='NEW YORK');
select * from scott.emp a where a.deptno in (select deptno from scott.dept where loc='NEW YORK');
成果:

--單行子查詢在 from 後
select scott.emp.*,(select deptno from scott.dept where loc='NEW YORK') a from scott.emp ;
--應用 in ,all,any 多行子查詢
--in:表現等於查詢出來的對應數據
select ename,job,sal,deptno from scott.emp where job in(select distinct job from scott.emp where deptno=10);
--all:表現年夜於一切括號中查詢出來的對應的數據信息
select ename,sal,deptno from scott.emp where sal>all(select sal from scott.emp where deptno=30);
--any:表現年夜於括號查詢出來的個中隨意率性一個便可(只隨機一個)
select ename,sal,deptno from scott.emp where sal>any(select sal from scott.emp where deptno=30);
--多列子查詢
select ename,job,sal,deptno from scott.emp where(deptno,job)=(select deptno,job from scott.emp where ename='SCOTT');
select ename,job,sal,deptno from scott.emp where(sal,nvl(comm,-1)) in(select sal,nvl(comm,-1) from scott.emp where deptno=30);
--非成比較較
select ename,job,sal,deptno from scott.emp where sal in(select sal from scott.emp where deptno=30) and nvl(comm,-1) in(select nvl(comm,-1) from scott.emp where deptno=30);
--其他子查詢
select ename,job,sal,deptno from scott.emp where exists(select null from scott.dept where scott.dept.deptno=scott.emp.deptno and scott.dept.loc='NEW YORK');
select ename,job,sal from scott.emp join(select deptno,avg(sal) avgsal,null from scott.emp group by deptno) dept on emp.deptno=dept.deptno where sal>dept.avgsal ;
create table scott.test(
ename varchar(20),
job varchar(20)
);
--drop table test ;
select * from scott.test ;
--Insert與子查詢(表間數據的拷貝)
insert into scott.test(ename,job) select ename,job from scott.emp ;
--Update與子查詢
update scott.test set(ename,job)=(select ename,job from scott.emp where ename='SCOTT' and deptno ='10');
--創立表時,還可以指定列名
create table scott.test_1(ename,job) as select ename,job from scott.emp ;
select * from scott.test_1 ;
--delete與子查詢
delete from scott.test where ename in('');
--歸並查詢
--union語法(歸並且去除反復行,且排序)
select ename,sal,deptno from scott.emp where deptno>10 union select ename,sal,deptno from scott.emp where deptno<30 ;
select a.deptno from scott.emp a union select b.deptno from scott.dept b ;
--union all(直接將兩個成果聚集並,不排序)
select ename,sal,deptno from scott.emp where deptno>10 union all select ename,sal,deptno from scott.emp where deptno<30 ;
select a.deptno from scott.emp a union all select b.deptno from scott.dept b ;
--intersect:取交集
select ename,sal,deptno from scott.emp where deptno>10 intersect select ename,sal,deptno from scott.emp where deptno<30;
--顯示部分工資總和高於雇員工資總和三分之一的部分名及工資總和
select dname as 部分,sum(sal) as 工資總和 from scott.emp a,scott.dept b where a.deptno=b.deptno group by dname having sum(sal)>(select sum(sal)/3 from scott.emp c,scott.dept d where c.deptno=d.deptno);
成果:
![]()
--應用with獲得以上異樣的成果
with test as (select dname ,sum(sal) sumsal from scott.emp ,scott.dept where scott.emp.deptno=scott.dept.deptno group by dname) select dname as 部分,sumsal as 工資總和 from scott.test where sumsal>(select sum(sumsal)/3 from scott.test);
成果:
![]()
--剖析函數
select ename,sal,sum(sal) over(partition by deptno order by sal desc) from scott.emp ;
--rows n preceding(窗口兒句一)
select deptno,sal,sum(sal) over(order by sal rows 5 preceding) from scott.emp ;
成果:

--rum(..) over(..)..
select sal,sum(1) over(order by sal) aa from scott.emp ;
select deptno,ename,sal,sum(sal) over(order by ename) 持續乞降,sum(sal) over() 總和,100*round(sal/sum(sal) over(),4) as 份額 from scott.emp;
成果:

select deptno,ename,sal,sum(sal) over(partition by deptno order by ename) 部分持續乞降,sum(sal) over(partition by deptno) 部分總和,100*round(sal/sum(sal) over(),4) as 總份額 from scott.emp;
成果:

select deptno,sal,rank() over (partition by deptno order by sal),dense_rank() over(partition by deptno order by sal) from scott.emp order by deptno ;
成果;

select * from (select rank() over(partition by 課程 order by 分數 desc) rk,剖析函數_rank.* from 剖析函數_rank) where rk<=3 ;
--dense_rank():有反復的數字不跳著分列
--row_number()
select deptno,sal,row_number() over(partition by deptno order by sal) rm from scott.emp ;
成果:
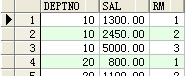
--lag()和lead()
select deptno,sal,lag(sal) over(partition by deptno order by sal) 上一個,lead(sal) over(partition by deptno order by sal) from scott.emp ;
成果:

--max(),min(),avg()
select deptno,sal,max(sal) over(partition by deptno order by sal)最年夜,min(sal) over(partition by deptno order by sal)最小,avg(sal) over(partition by deptno order by sal)均勻 from scott.emp ;
成果:
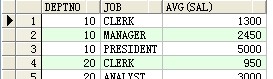
--first_value(),last_value()
select deptno,sal,first_value(sal) over(partition by deptno)最前,last_value(sal) over(partition by deptno )最初 from scott.emp ;
成果:
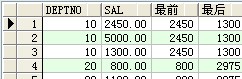
--分組彌補 group by grouping sets
select deptno ,sal,sum(sal) from scott.emp group by grouping sets(deptno,sal);
select null,sal,sum(sal) from scott.emp group by sal union all select deptno,null,sum(sal) from scott.emp group by deptno ;
成果:

--rollup
select deptno,job,avg(sal) from scott.emp group by rollup(deptno,job) ;
--懂得rollup等價於
select deptno,job,avg(sal) from scott.emp group by deptno,job union select deptno ,null,avg(sal) from scott.emp group by deptno union select null,null,avg(sal) from scott.emp ;
成果:
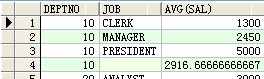
select deptno,job,avg(sal) a from scott.emp group by cube(deptno,job) ;
--懂得CUBE
select deptno,job,avg(sal) from scott.emp group by cube(deptno,job) ;
--等價於
select deptno,job,avg(sal) from scott.emp group by grouping sets((deptno,job),(deptno),(job),());
成果:
--查詢工資不在1500至2850之間的一切雇員名及工資
select ename,sal from scott.emp where sal not in(select sal from scott.emp where sal between 1500 and 2850 );
--部分10和30中的工資跨越1500的雇員名及工資
select deptno,ename,sal from scott.emp a where a.deptno in(10,30) and a.sal>1500 order by sal desc ;
成果:
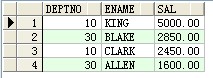
--在1981年2月1日至1981年5月1日之間雇傭的雇員名,崗亭及雇傭日期,並以雇傭日期前後次序排序
select ename as 姓名,job as 崗亭,hiredate as 雇傭日期 from scott.emp a where a.hiredate between to_date('1981-02-01','yyyy-mm-dd') and to_date('1981-05-01','yyyy-mm-dd') order by a.hiredate asc ;
成果:

select * from scott.emp where hiredate >to_date('1981-02-01','yyyy-MM-dd');
--查詢取得補貼的一切雇傭名,工資及補貼額,並以工資和補貼的降序排序
select ename,sal,comm from scott.emp a where a.comm > all(0) order by comm desc;
--工資低於1500的員工增長10%的工資,工資在1500及以上的增長5%的工資並按工資高下排序(降序)
select ename as 員工姓名,sal as 補發前的工資,case when sal<1500 then (sal+sal*0.1) else (sal+sal*0.05) end 補貼後的工資 from scott.emp order by sal desc ;
成果:
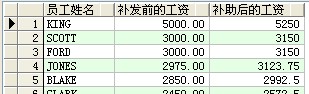
--查詢公司天天,每個月,每季度,每一年的資金收入數額
select sum(sal/30) as 天天發的工資,sum(sal) as 每個月發的工資,sum(sal)*3 as 每季度發的工資,sum(sal)*12 as 每一年發的工資 from scott.emp;
成果:
![]()
--查詢一切員工的均勻工資,總計工資,最高工資和最低工資
select avg(sal) as 均勻工資,sum(sal) as 總計工資,max(sal) as 最高工資,min(sal) as 最低工資 from scott.emp;
成果:
![]()
--每種崗亭的雇員總數戰爭均工資
select job as 崗亭,count(job) as 崗亭雇員總數,avg(sal) as 均勻工資 from scott.emp group by job order by 均勻工資 desc;
成果:
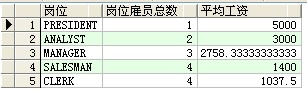
--雇員總數和取得補貼的雇員數
select count(*) as 公司雇員總數,count(comm) as 取得補貼的雇員人數 from scott.emp ;
--治理者的總人數
--雇員工資的最年夜差額
select max(sal),min(sal),(max(sal) - min(sal)) as 員工工資最年夜差額 from scott.emp ;
--每一個部分的均勻工資
select deptno,avg(sal) from scott.emp a group by a.deptno;
成果:
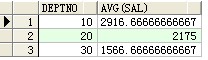
--查詢每一個崗亭人數跨越2人的一切人員信息
select * from scott.emp a,(select c.job,count(c.job) as sl from scott.emp c group by c.job ) b where b.sl>2 and a.job=b.job;
成果:

select * from scott.emp a where a.empno in(select mgr from scott.emp ) and (select count(mgr) from scott.emp)>2 ;
成果:
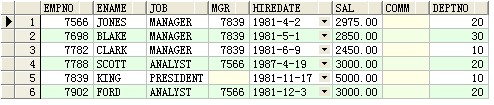
--處置反復行數據信息(刪除,查找,修正)
select * from a1 a where not exists (select b.rd from (select rowid rd,row_number() over(partition by LOAN, BRANCH order by BEGIN_DATE desc) rn from a1) b where b.rn = 1 and a.rowid = b.rd);
--查詢emp表數據信息反復成績
select * from scott.emp a where exists(select b.rd from(select rowid rd,row_number() over(partition by ename,job,mgr,hiredate,sal,comm,deptno order by empno asc) rn from scott.emp) b where b.rn=1 and a.rowid=b.rd);
--initcap:前往字符串,字符串第一個字母年夜寫
select initcap(ename) Upp from scott.emp ;
成果:
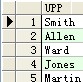
--ascii:前往與指定的字符對應的十進制數
select ascii(a.empno) as 編號,ascii(a.ename) as 姓名,ascii(a.job) as 崗亭 from scott.emp a ;
成果:
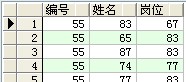
--chr:給出整數,前往對應的字符
select chr(ascii(ename)) as 姓名 from scott.emp ;
成果:

--concat:銜接字符串
select concat(a.ename,a.job)|| a.empno as 字符銜接 from scott.emp a;
成果:

--instr:在一個字符串中搜刮指定的字符,前往發明指定的字符的地位
select instr(a.empno,a.mgr,1,1) from scott.emp a ;
--length:前往字符串的長度
select ename,length(a.ename) as 長度,a.job,length(a.job) as 長度 from scott.emp a ;
--lower:前往字符串,並將所前往的字符小寫
select a.ename as 年夜寫,lower(a.ename) as 小寫 from scott.emp a ;
成果:
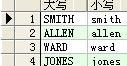
--upper:前往字符串,並將前往字符串都年夜寫
select lower(a.ename) as 小寫名字,upper(a.ename) as 年夜寫名字 from scott.emp a ;
成果:
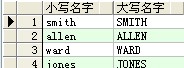
--rpad:在列的左邊粘貼字符,lpad: 在列的右邊粘貼字符(不敷字符則用*來填滿)
select lpad(rpad(a.ename,10,'*'),16,'*') as 粘貼 from scott.emp a ;
成果:

--like分歧角度的應用
select * from scott.emp where ename like '%XXR%';
select * from scott.emp where ename like '%S';
select * from scott.emp where ename like 'J%';
select * from scott.emp where ename like 'S';
select * from scott.emp where ename like '%S_';
--每一個部分的工資總和
select a.ename,sum(sal) from scott.emp a group by ename;
--每一個部分的均勻工資
select a.deptno,avg(sal) from scott.emp a group by deptno ;
--每一個部分的最年夜工資
select a.deptno,max(sal) from scott.emp a group by deptno ;
--每一個部分的最小工資
select a.deptno,min(sal) from scott.emp a group by deptno ;
--查詢原工資占部分工資的比率
select deptno ,sal,ratio_to_report(sal) over(partition by deptno) sal_ratio from scott.emp ;
--查詢成就不合格的一切先生信息(提醒:沒有對應的表,只是意思意思。不合格人數年夜於等於三能力查)
select * from scott.emp where empno in(select distinct empno from scott.emp where 3<(select count(sal) from scott.emp where sal<3000) and empno in(select empno from scott.emp where sal<3000));
成果:

--查詢每一個部分的均勻工資
select distinct deptno,avg(sal) from scott.emp group by deptno order by deptno desc;
--union組合查出的成果,但請求查出來的數據類型必需雷同
select sal from scott.emp where sal >=all(select sal from scott.emp ) union select sal from scott.emp ;
select * from scott.emp a where a.empno between 7227 and 7369 ;--只能從小到年夜
---------創立表空間 要用具有create tablespace權限的用戶,好比sys
create tablespace tbs_dat datafile 'c:\oradata\tbs_dat.dbf' size 2000M;
---------添加數據文件
alter tablespace tbs_dat add datafile 'c:\oradata\tbs_dat2.dbf' size 100M;
---------轉變數據文件年夜小
alter database datafile 'c:\oradata\tbs_dat.dbf' resize 250M;
---------數據文件主動擴大年夜小
alter database datafile 'c:\oradata\tbs_dat.dbf' autoextend on next 1m maxsize 20m;
---------修正表空間稱號
alter tablespace tbs_dat rename to tbs_dat1;
---------刪除表空間 and datafiles 表現同時刪除物理文件
drop tablespace tbs_dat including contents and datafiles;
--substr(s1,s2,s3):截取s1字符串,從s2開端,停止s3
select substr(job,3,length(job)) from scott.emp ;
--replace:調換字符串
select replace(ename,'LL','aa') from scott.emp;
select * from scott.test;
insert into scott.test(ename,job) values('weather','好');
insert into scott.test(ename,job) values('wether','差');
--soundex:前往一個與給定的字符串讀音雷同的字符串
select ename from scott.test where soundex(ename)=soundex('wether');
--floor:取整數
select sal,floor(sal) as 整數 from scott.emp ;
--log(n,s):前往一個以n為低,s的對數
select empno,log(empno,2) as 對數 from scott.emp ;
--mod(n1,n2):前往一個n1除以n2的余數
select empno,mod(empno,2) as 余數 from scott.emp ;
成果:

--power(n1,n2):前往n1的n2次方根
select empno,power(empno,2) as 方根 from scott.emp ;
--round和trunc:依照指定的精度停止捨入
select round(41.5),round(-41.8),trunc(41.6),trunc(-41.9) from scott.emp ;
--sign:取數字n的符號,年夜於0前往1,小於0前往-1,等於0前往0
select sign(45),sign(-21),sign(0) from scott.emp ;
成果:

select * from scott.emp;
oracle相干的數據庫SQL查詢語句:
1. 退職員表中查詢出根本工資比均勻根本工資高的職工編號。
2. 查詢一個或許多個部分的一切員工信息,該部分的一切員工工資都高於公司的均勻工資。
3. 現有張三的出身日期:1985-01-15 01:27:36,請各改過建表,將此日期時光拔出表中,並盤算出張三的年紀,顯示張三的誕辰。
4. 誕辰的輸入格局請求為MM-DD(未滿兩位的用0不全),張三的誕辰為01-15。
5. 算年紀請求用三個方法完成。
6. 誕辰請求用兩個方法完成。
7. 在數據庫表中有以下字符數據,如:
13-1,14-2,13-15,13-2,13-108,13-3,13-10,13-200,13-18,100-11,14-1
如今願望經由過程一條SQL語句停止排序,而且起首要依照前半部門的數字停止排序,然後再依照後半部門的數字停止排序,輸入要拍成以下所示:
13-1,13-2,13-3,13-10,13-15,13-18,13-108,13-200,14-1,14-2,100-11
數據庫表名:SellRecord;字段ListNumber;
8. 顯示一切雇員的姓名和滿10年辦事年限後的日期。
9. 顯示雇員姓名,依據其辦事年限,將最老的雇員排在最後面。
10顯示一切雇員的姓名和參加公司的年份和月份,按雇員受雇日期地點月排序,將最早年份的人員排在最後面。
10. 顯示假定一個月為30天的情形下一切雇員的日薪金。
11. 找出在(任何年份的)2月受聘的一切雇員(用兩種方法完成)。
12. 關於每一個雇員,顯示其參加公司的天數。
13. 以年,月和日的方法顯示一切雇員的辦事年限(入職若干年/入職了若干月/入職了若干天)。
14. 找出各月最初一天受雇的一切雇員。
15. 找出早於25年之前受雇的雇員(用兩種方法完成)。
16. 工資最低1500的人員增長10%,1500以上的增長5%的工資,用一條update語句完成(用兩種方法完成)。
17. 依照部分統計每種崗亭的均勻工資,請求輸入的格局以下圖所示:

18.

19.

20.

21,。

22.

自己聲明:以上內容湧現任何毛病與缺乏,皆與自己有關。