數據庫機能優化一:數據庫本身優化晉升機能。本站提示廣大學習愛好者:(數據庫機能優化一:數據庫本身優化晉升機能)文章只能為提供參考,不一定能成為您想要的結果。以下是數據庫機能優化一:數據庫本身優化晉升機能正文
數據庫優化包括以下三部門,數據庫本身的優化,數據庫表優化,法式操作優化.此文為第一部門
優化①:增長次數據文件,設置文件主動增加(粗略數據分區)
1.1:增長次數據文件
從SQLSERVER2005開端,數據庫不默許生成NDF數據文件,普通情形下有一個主數據文件(MDF)就夠了,然則有些年夜型的數據庫,因為信息許多,並且查詢頻仍,所認為了進步查詢速度,可以把一些表或許一些表中的部門記載離開存儲在分歧的數據文件裡
因為CPU和內存的速度弘遠於硬盤的讀寫速度,所以可以把分歧的數據文件放在分歧的物理硬盤裡,如許履行查詢的時刻,便可以讓多個硬盤同時停止查詢,以充足應用CPU和內存的機能,進步查詢速度。在這裡具體引見一下其寫入的道理,數據文件(MDF、NDF)和日記文件(LDF)的寫入方法是紛歧樣的:
數據文件:SQLServer依照統一個文件組外面的一切文件現有余暇空間的年夜小,按這個比例把新的數據散布到一切有空間的數據文件裡,假如有三個數據文件A.MDF,B.NDF,C.NDF,余暇年夜小分離為200mb,100mb,和50mb,那末寫入一個70mb的器械,他就會向ABC三個文件中一次寫入40、20、10的數據,假如某個日記文件已滿,就不會向其寫入
日記文件:日記文件是依照次序寫入的,一個寫滿,才會寫入別的一個
由上可見,假如能增長其數據文件NDF,有益於年夜數據量的查詢速度,然則增長日記文件卻沒甚麼用途。
1.2:設置文件主動增加(年夜數據量,小數據量無需設置)
在SQLServer2005中,默許MDF文件初始年夜小為5MB,自增為1MB,不限增加,LDF初始為1MB,增加為10%,限制文件增加到必定的數量,普通設計中,應用SQL自帶的設計便可,然則年夜型數據庫設計中,最好親身去設計其增加和初始年夜小,假如初始值太小,那末很快數據庫就會寫滿,假如寫滿,在停止拔出會是甚麼情形呢?當數據文件寫滿,停止某些操作時,SQLServer會讓操作期待,直到文件主動增加停止了,本來的誰人操作能力持續停止。假如自增加用了很長時光,本來的操作會等不及就超時撤消了(普通默許的阈值是15秒),不只這個操作會回滾,文件主動增加也會被撤消。也就是說,這一次文件沒有獲得任何增年夜,增加的時光依據主動增加的年夜小肯定的,假如太小,能夠一次操作須要持續幾回增加能力知足,假如太年夜,就須要期待很長時光,所以設置主動增加要留意一下幾點:
1)要設置成按固定年夜小增加,而不克不及按比例。如許就可以防止一次增加太多或許太少所帶來的不用要的費事。建議比較較小的數據庫,設置一次增加50MB到100MB。對年夜的數據庫,設置一次增加100MB到200MB。
2)要按期監測各個數據文件的應用情形,盡可能包管每一個文件殘剩的空間一樣年夜,或許是希冀的比例。
3)設置文件最年夜值,以避免SQLServer文件自增加用盡磁盤空間,影響操作體系。
4)產生自增加後,要實時檢討新的數據文件空間分派情形。防止SQLServer老是往個體文件寫數據。
是以,關於一個比擬忙碌的數據庫,推舉的設置是開啟數據庫主動增加選項,以防數據庫空間用盡招致運用法式掉敗,然則要嚴厲防止主動增加的產生。同時,盡可能不要應用主動壓縮功效。
1.3數據和日記文件離開寄存在分歧磁盤上
數據文件和日記文件的操作會發生年夜量的I/O。在能夠的前提下,日記文件應當寄存在一個與數據和索引地點的數據文件分歧的硬盤上以疏散I/O,同時還有益於數據庫的災害恢復。
優化②:表分區,索引分區(優化①粗略的停止了表分區,優化②為准確數據分區)
為何要表分區?
當一個表的數據量太年夜的時刻,我們最想做的一件事是甚麼?將這個表一分為二或許更多分,然則表照樣這個表,只是將其內容存儲離開,如許讀取就快了N倍了
道理:表數據是沒法放在文件中的,然則文件組可以放在文件中,表可以放在文件組中,如許就直接完成了表數據寄存在分歧的文件中。能分區存儲的還有:表、索引和年夜型對象數據。
SQLSERVER2005中,引入了表分區的概念,當表中的數據量赓續增年夜,查詢數據的速度就會變慢,運用法式的機能就會降低,這時候就應當斟酌對表停止分區,當一個內外的數據許多時,可以將其分拆到多個的內外,由於要掃描的數據變得更少,查詢可以更快地運轉,如許操作年夜年夜進步了機能,表停止分區後,邏輯上表依然是一張完全的表,只是將表中的數據在物理上寄存到多個表空間(物理文件上),如許查詢數據時,不至於每次都掃描整張表
2.1甚麼時刻應用分區表:
1、表的年夜小跨越2GB。
2、表中包括汗青數據,新的數據被增長到新的分區中。
2.2表分區的優缺陷
表分區有以下長處:
1、改良查詢機能:對分區對象的查詢可以僅搜刮本身關懷的分區,進步檢索速度。
2、加強可用性:假如表的某個分區湧現毛病,表在其他分區的數據依然可用;
3、保護便利:假如表的某個分區湧現毛病,須要修單數據,只修復該分區便可;
4、平衡I/O:可以把分歧的分區映照到磁盤以均衡I/O,改良全部體系機能。
缺陷:
分區表相干:曾經存在的表沒無方法可以直接轉化為分區表。不外Oracle供給了在線重界說表的功效.
2.3表分區的操作三步走
2.31創立分區函數
CREATEPARTITIONFUNCTIONxx1(int)
ASRANGELEFTFORVALUES(10000,20000);
正文:創立分區函數:myRangePF2,以INT類型分區,分三個區間,10000之內在A區,1W-2W在B區,2W以上在C區.
2.3.2創立分區架構
CREATEPARTITIONSCHEMEmyRangePS2
ASPARTITIONxx1
TO(a,b,c);
正文:在分區函數XX1上創立分區架構:myRangePS2,分離為A,B,C三個區間
A,B,C分離為三個文件組的稱號,並且必需三個NDF附屬於這三個組,文件所屬文件組一旦創立就不克不及修正
2.3.3對表停止分區
經常使用數據標准--數據空間類型修正為:分區計劃,然後選擇分區計劃稱號和分區列列表,成果如圖所示:
也能夠用sql語句生成
CREATETABLE[dbo].[AvCache](
[AVNote][varchar](300)NULL,
[bb][int]IDENTITY(1,1)
)ON[myRangePS2](bb);--留意這裡應用[myRangePS2]架構,依據bb分區
2.3.4查詢表分區
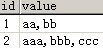
SELECT*,$PARTITION.[myRangePF2](bb)FROMdbo.AVCache

如許便可以清晰的看到表數據是若何分區的了
2.3.5創立索引分區

優化③:散布式數據庫設計
散布式數據庫體系是在集中式數據庫體系的基本上成長起來的,懂得起來也很簡略,就是將全體的數據庫離開,散布到各個處所,就其實質而言,散布式數據庫體系分為兩種:1.數據在邏輯上是同一的,而在物理上倒是疏散的,一個散布式數據庫在邏輯上是一個同一的全體,在物理上則是分離存儲在分歧的物理節點上,我們平日說的散布式數據庫都是這類2.邏輯是散布的,物理上也是散布的,這類同樣成聯邦式散布數據庫,因為構成聯邦的各個子數據庫體系是絕對“自治”的,這類體系可以包容多種分歧用處的、差別較年夜的數據庫,比擬合適於年夜規模內數據庫的集成。
散布式數據庫較為龐雜,在此不作具體的應用和解釋,只是舉例解釋一下,如今散布式數據庫多用於用戶分區性較強的體系中,假如一個全國連鎖店,普通設計為每一個分店都有本身的發賣和庫存等信息,總部則須要有員工,供給商,分店信息等數據庫,這類型的分店數據庫可以完整分歧,許多體系也能夠招致紛歧致,如許,各個連鎖店數據存儲在當地,從而進步了影響速度,下降了通訊費用,並且數據散布在分歧場地,且存有多個正本,即便個體場地產生毛病,不致惹起全部體系的癱瘓。然則他也帶來許多成績,如:數據分歧性成績、數據長途傳遞的完成、通訊開支的下降等,這使得散布式數據庫體系的開辟變得較為龐雜,只是讓年夜家明確其道理,詳細的應用方法就不做具體的引見了。
優化④:整頓數據庫碎片
假如你的表曾經創立好了索引,但機能卻依然欠好,那極可能是發生了索引碎片,你須要停止索引碎片整頓。
甚麼是索引碎片?
因為表上有過度地拔出、修正和刪除操作,索引頁被分紅多塊就構成了索引碎片,假如索引碎片嚴重,那掃描索引的時光就會變長,乃至招致索引弗成用,是以數據檢索操作就慢上去了。
若何曉得能否產生了索引碎片?
在SQLServer數據庫,經由過程DBCCShowContig或DBCCShowContig(表名)檢討索引碎片情形,指點我們對其停止准時重建整頓。

經由過程對掃描密度(太低),掃描碎片(太高)的成果剖析,剖斷能否須要索引重建,重要看以下兩個:
ScanDensity[BestCount:ActualCount]-掃描密度[最好值:現實值]:DBCCSHOWCONTIG前往最有效的一個百分比。這是擴大盤區的最好值和現實值的比率。該百分比應當盡量接近100%。低了則解釋有內部碎片。
LogicalScanFragmentation-邏輯掃描碎片:無序頁的百分比。該百分比應當在0%到10%之間,高了則解釋有內部碎片。
處理方法:
一是應用DBCCINDEXDEFRAG整頓索引碎片
二是應用DBCCDBREINDEX重建索引。
二者差別挪用微軟的原話以下:
DBCCINDEXDEFRAG敕令是聯機操作,所以索引只要在該敕令正在運轉時才可用,並且可以在不喪失已完成任務的情形下中止該操作。這類辦法的缺陷是在從新組織數據方面沒有集合索引的除去/從新創立操作有用。
從新創立集合索引將對數據停止從新組織,其成果是使數據頁填滿。填滿水平可使用FILLFACTOR選項停止設置裝備擺設。這類辦法的缺陷是索引在除去/從新創立周期內為脫機狀況,而且操作屬原子級。假如中止索引創立,則不會從新創立該索引。也就是說,要想取得好的後果,照樣得用重建索引,所以決議重建索引。