SQL Server 總結溫習 (二)。本站提示廣大學習愛好者:(SQL Server 總結溫習 (二))文章只能為提供參考,不一定能成為您想要的結果。以下是SQL Server 總結溫習 (二)正文
1. 排名函數與PARTITION BY
--一切數據
SELECT * FROM dbo.student AS a INNER JOIN dbo.ScoreTB AS b ON a.Id = b.stuid
WHERE scorename = '語文'
-------------------------------------------
--ROW_NUMBER() 的應用 生成列從1開端順次增長
-------------------------------------------
SELECT ROW_NUMBER() OVER (ORDER BY B.SCORE DESC) AS ROWNUMBER ,A.NAME, B.SCORE, a.Id
FROM dbo.student AS a INNER JOIN dbo.ScoreTB AS b ON a.Id = b.stuid
WHERE scorename = '語文'
--也能夠在前面再加一個order by,則表現後面生成後的全體列又被以最初的列從新分列(排名列值不變)
SELECT ROW_NUMBER() OVER (ORDER BY B.SCORE DESC) AS ROWNUMBER ,A.NAME, B.SCORE, a.Id
FROM dbo.student AS a INNER JOIN dbo.ScoreTB AS b ON a.Id = b.stuid
WHERE scorename = '語文' ORDER BY a.Id
--要在分組統計後應用排名函數,則先輩行分組,用cte或嵌套查詢表整出成果集,再用row_number函數處置
WITH b AS
(
SELECT stuid, SUM(score) AS score FROM ScoreTB GROUP BY stuid
)
SELECT * ,ROW_NUMBER() OVER (ORDER BY b.score desc) AS rownumer
FROM dbo.student AS a INNER JOIN b ON a.id = b.stuid
----------------------------------------------------------------------------
--RANK() 用法與ROW_NUMER函數想同,只是在湧現order by同級時,排名會設置成一樣,而下一個會依據之前的記載數生成序號
--例如後面三個是一樣的,那末都是1,下一個則是4,示例略
----------------------------------------------------------------------------
----------------------------------------------------------------------------
--DENSE_RANK() 密集排名 用法與ROW_NUMER、RANK函數雷同,只是在生成序號時是持續的,而rank函數生成的序號有能夠不持續
--例如後面三個是一樣的,那末都是1,下一個則是2,示例略
----------------------------------------------------------------------------
----------------------------------------------------------------------------
--ntile函數可以對序號停止分組處置。這就相當於將查詢出來的記載集放到指定長度的數組中,每個數組元素寄存必定數目的記載。
--為每筆記錄生成的序號就是這筆記錄一切的數組元素的索引(從1開端)。也能夠將每個分派記載的數組元素稱為“桶”。
--它有一個參數,用來指定桶數,例如
----------------------------------------------------------------------------
SELECT ntile(2) OVER (ORDER BY B.SCORE DESC) AS GROUPID ,A.NAME, ISNULL(B.SCORE,0) SCORE, a.Id
FROM dbo.student AS a LEFT JOIN dbo.ScoreTB AS b ON a.Id = b.stuid AND scorename = '語文'
--------------------------------------------------------------------------
--PARTITION BY 相似於向排名函數運用一個group by,分組後對每個組零丁排名
--------------------------------------------------------------------------
--統計各個學科的排名順次為:
SELECT RANK() OVER (PARTITION BY b.scorename ORDER BY B.SCORE DESC) AS ROWNUMBER,b.scorename,
b.score, A.NAME, a.Id FROM dbo.student AS a INNER JOIN dbo.ScoreTB AS b ON a.Id = b.stuid ORDER BY SCORENAME
2. TOP 新用法
DECLARE @num INT = 101
SELECT TOP (@num) * FROM Student ORDER BY Id --必需用括號括起來
SELECT TOP (@num) percent * FROM Student ORDER BY Id --只接收float而且1-100之間的數,假如傳入其他則會報錯
3. group by all 字段 / group by 字段
前者有點像left join ,right join的感到,二者的重要差別表現在有where前提被過濾的聚合函數,會從新抓掏出來放入查詢的數據表中,只是聚合函數會依據前往值的類型用默許值0或許NULL來取代聚合函數的前往值。
固然從效力下去說,後者優於前者,就像inner join 優於left join一樣
4. count(*)/count(0) 與 count(字段)
假如查詢出來的字段中沒有NULL值,那末倆種查詢前提無任何差別,假如有NULL,後者統計出來的記載則是 總記載數 - NULL記載數
從機能下去說,前者高於後者,由於後者會逐行掃描字段中能否有NULL值,有NULL則不加以統計,削減了邏輯讀的開支,從而機能到達晉升
5. top n With ties 的用法
詳見 http://www.cnblogs.com/skynet/archive/2010/03/29/1700055.html
舉個例子
select top 1 with ties * from student order by score desc
等價於
select * from student where score=(select top 1 score from student order by score desc)
6. Apply運算符
View Code
--預備數據
CREATE TABLE [dbo].[Student](
[Id] [int] NULL,
[Name] [varchar](50) NULL
)
go
INSERT INTO dbo.Student VALUES (1, '張三')
INSERT INTO dbo.Student VALUES (2, '李斯')
INSERT INTO dbo.Student VALUES (3, '王五')
INSERT INTO dbo.Student VALUES (4, '神人')
go
CREATE TABLE [dbo].[scoretb](
[stuId] [int] NULL,
[scorename] [varchar](50) NULL,
[score] INT NULL
)
go
INSERT INTO [scoretb] VALUES (1,'語文',22)
INSERT INTO [scoretb] VALUES (1,'數學',32)
INSERT INTO [scoretb] VALUES (1,'外語',42)
INSERT INTO [scoretb] VALUES (2,'語文',52)
INSERT INTO [scoretb] VALUES (2,'數學',62)
INSERT INTO [scoretb] VALUES (2,'外語',72)
INSERT INTO [scoretb] VALUES (3,'語文',82)
INSERT INTO [scoretb] VALUES (3,'數學',92)
INSERT INTO [scoretb] VALUES (3,'外語',72)
--創立表值函數
CREATE FUNCTION [dbo].[fGetScore](@stuid int)
RETURNS @score TABLE
(
[stuId] [int] NULL,
[scorename] [varchar](50) NULL,
[score] INT NULL
)
as
BEGIN
INSERT INTO @score
SELECT stuid,scorename,score FROM dbo.scoretb WHERE stuId = @stuid
RETURN;
END
GO
--開端應用
SELECT A.id,A.name,B.scorename,B.score FROM [Student] A
CROSS APPLY [dbo].[fGetScore](A.Id) B --相當於inner join後果
SELECT A.id,A.name,B.scorename,B.score FROM [Student] A
OUTER APPLY [dbo].[fGetScore](A.Id) B --相當於left join後果
--而不克不及如許應用
--SELECT A.id,A.name,B.scorename,B.score FROM [Student] A
-- INNER JOIN [dbo].[fGetScore](A.Id) B ON A.Id = B.stuid
-- SELECT A.id,A.name,B.scorename,B.score FROM [Student] A
-- INNER JOIN (SELECT * FROM [dbo].[fGetScore](A.Id)) B ON A.Id = B.stuid
7. INTERSECT和EXCEPT運算符
EXCEPT 只包括excpet症結字右邊並且左邊的成果集中不存在的那些行 INTERSECT 只包括兩個成果集中都存在的那些行
常常EXISTS症結字可以取代下面的症結字,而且從機能中可以看到比他們更好,但EXCEPT/INTERSECT更便於浏覽和直不雅。照樣建議從機能更優動手。
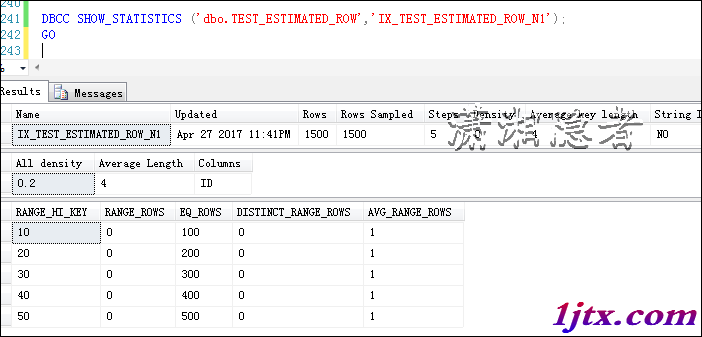
8. 索引進步查詢效力的道理
索引與EXISTS運算符在處置方法上很像,它們都可以在找到婚配值後立刻加入查詢運轉,從而進步了查詢機能
9. 表變量與暫時表
重要差別: 1表變量不寫日記,沒有統計信息,頻仍更改不會形成存儲進程從新編譯,不克不及建索引和統計信息,然則可以樹立主鍵,變通完成索引查找,表變量不只是在內存中操作,數據量年夜的情形也會寫tempdb,即物理磁盤的IO操作。 2.事務回滾對表變量有效(緣由沒有統計信息)
普通來講,數據量年夜,暫時成果集須要和其他表二次聯系關系用暫時表 數據量小,零丁操作暫時成果集用表變量
10. 劇本和批處置
Go不是一條T-SQL敕令,他只能被編譯對象Management Studio, SQLCMD辨認,假如用第三方對象,紛歧定支撐GO敕令。例如ADO.NET,ADO。
11. SQLCMD的應用
SQLCMD -Usa -Psa -Q "SELECT * FROM TESTDB.dbo.mytable"
SQLCMD -Usa -Psa -i testsql.sql 運轉文件裡的SQL語句
12. EXEC 應用解釋
在履行過EXEC以後,可使用相似@@ROWCOUNT如許的變量檢查影響行數;不克不及在EXEC的參數中,針對EXEC字符串運轉函數,例如cast(XX AS VARCHAR),關於EXEC的參數,只能用字符串相加,或許是全體的字符串。
13. WAITFOR 的寄義
WAITFOR TIME <'TIME'> 准時履行; WAITFOR DELAY <'TIME'> 延遲履行
14. 存儲進程 總結
1)用TRY/CATCH 替換 @@ERROR這類更迷信,其一@@ERROR沒有TRA/CATCH直不雅,其二碰到毛病級別在11-19的毛病,毛病會使運轉直接中止,招致@@ERROR斷定毛病與否有效。
2)應用RAISERROR 拋錯
WITH LOG,當嚴重級別年夜於等於19時,須要應用這個選項
WITH SETERROR,使其重寫@@ERROR值,便利內部挪用
WITH NOWAIT 連忙將毛病告訴給客戶端
15. 游標的溫習
游標重要部門包含:1)聲明 2)翻開 3)應用或導航 4)封閉 5)釋放
嵌套應用游標示例
DECLARE BillMsgCursor CURSOR FOR
SELECT TypeNo,TabDetailName FROM dbo.BillType
OPEN BillMsgCursor
DECLARE @TypeNo CHAR(5)
DECLARE @DetailName VARCHAR(50)
FETCH NEXT FROM BillMsgCursor INTO @TypeNo,@DetailName
WHILE @@FETCH_STATUS = 0
BEGIN
DECLARE @DataFieldName VARCHAR(50)
DECLARE ColumnName CURSOR FOR
SELECT name FROM syscolumns WHERE id = OBJECT_ID(@DetailName)
OPEN ColumnName
FETCH NEXT FROM ColumnName INTO @DataFieldName
PRINT '單據編號:' + @TypeNo
WHILE @@FETCH_STATUS = 0
BEGIN
PRINT 'ListDetailDataFiled.Add('''+@DataFieldName+''');'
FETCH NEXT FROM ColumnName INTO @DataFieldName
END
CLOSE ColumnName
DEALLOCATE ColumnName
FETCH NEXT FROM BillMsgCursor INTO @TypeNo,@DetailName
END
CLOSE BillMsgCursor
DEALLOCATE BillMsgCursor
@@fetch_status值的意義:0 FETCH 語句勝利;-1 FETCH 語句掉敗或此行不在成果集中;-2 被提取的行不存在
FETCH [NEXT/PRIOR/FIRST/LAST] FROM ... INTO 針對游標為SCROLL類型的
16. 游標的分類
1)靜態游標(static):相當於暫時表,會保留在tempdb裡的公有表中,如同快照表復制一份
a.一旦創立了游標,它就與現實記載相分別其實不再保持任何鎖
b.游標就是自力的,不再以任何方法與原始數據相干聯
2)鍵集驅動的游標(keyset):須要在必定水平上感知對數據的修正,但不用懂得最新產生的一切拔出
a.表必需具有獨一索引
b.只要鍵集在tempdb中,而非全部數據集,對全部辦事器機能發生有益的影響
c.能感知到對己是鍵集一部門的行所做的修正(改刪),不克不及感知新增
3)靜態游標(DYNAMIC)
a.完整靜態,異常敏感,對底層數據做的一切工作都邑影響,機能固然也是最差的
b.它們會帶來額定的並發性成績
c.每收回一次FETCH,都要重建游標
d.可許可運轉沒有獨一索引的表中,但弊病會形成SQLSERVER沒法追蹤它在游標的地位形成逝世輪回,應防止如許應用
4)快進游標(FAST_FORWARD)
在很多情形下,FAST_FORWARD游標會隱式轉換為其他游標類型