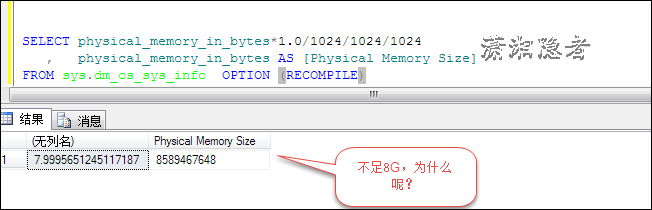
索引的道理及索引樹立的留意事項。本站提示廣大學習愛好者:(索引的道理及索引樹立的留意事項)文章只能為提供參考,不一定能成為您想要的結果。以下是索引的道理及索引樹立的留意事項正文
集合索引,數據現實上是按次序存儲的,數據頁就在索引頁上。就似乎參考手冊將一切主題按次序編排一樣。一旦找到了所要搜刮的數據,就完成了此次搜刮,關於非集合索引,索引是平安自力於數據自己構造的,在索引中找到了尋覓的數據,然後經由過程指針定位到現實的數據。
SQL Server中的索引應用尺度的B-樹來存儲他們的信息,以下圖所示,B-樹經由過程查找索引中的一個症結之來供給關於數據的疾速拜訪,B-樹以類似的鍵記載聚合在一路,B不代表二叉(binary),而是代表balanced(均衡的),而B-樹的一個焦點感化就是堅持樹的均衡。同伙向下遍歷這棵樹以找到一個數值並定位記載。由於樹是均衡的,所以尋覓任何記載都只須要等量的資本,並且獲得的速度老是分歧的—由於從根索引葉索引都具有雷同的深度。
索引的中央條理是依據表的行數一級索引行的年夜小而變更的,假如應用一個較長的鍵(KEY)來創立索引,一個分頁上就只包容較少的條目,因此索引就須要更多分頁(或許說更多層),頁越多那末查找就須要話費絕對較長的時光來找到所須要的信息,索引便可能不太有效了。
集合索引
集合索引的葉級別不只包括了索引鍵,還包括了數據頁。另外一種說法數據自己也是集合索引的一部門,集合索引基於鍵值堅持表中的數據有序,表中的數據頁是經由過程一個被稱作頁鏈(page chain)的雙向鏈接表來保護的,因為現實的數據頁的頁鏈只能按一種方法排序,是以一張表只能具有一個集合索引。
這裡能夠有一個誤區,有許多引見SQL Server索引的文檔會告知讀者:集合索引依照排序次序(sorted order)物理地存儲數據。假如認為物理存儲就是磁盤自己的話就會發生誤會。試想假如集合索引須要依照特定次序在現實的磁盤上保護數據的話,那末任何修正操作都將會發生相當昂揚的價值。當一個頁變滿了須要一分為二的時刻,一切後續頁面上的數據都必需向後挪動。集合索引中的排序次序(sorted order)僅僅表現數據頁鏈在邏輯上是有序的。
年夜多半表都應當須要一個集合索引。優化器異常偏向於采取集合索引,由於集合索引可以或許直接在葉級別找到數據。因為界說了數據的邏輯次序,集合索引可以或許特殊快的拜訪針對規模值的查詢,查詢優化器可以或許發明只要某一段規模的數據頁須要掃描。
非集合索引
關於非集合索引,葉級別不包括全體的數據。除鍵值以外,每一個葉級別(樹的最底層)中的索引行包括了一個書簽(bookmark),告知SQL Server可以在那邊找到與索引鍵響應的數據行。一個書簽能夠有兩種情勢。假如表上存在集合索引,書簽就是響應的數據行的集合索引鍵。假如彪是堆(heap)構造,書簽就是一個行表現(row identifier,RID),以“文件號:頁號:槽號”的格局來定位現實的行。
主鍵(PRIMARY KEY)與集合索引(CLUSTER INDEX)
嚴厲來講,主鍵與集合索引沒有任何干系,假如要說有話,那就是表中沒有集合索引的時刻,創立的主鍵默許就是集合索引(除非有特殊設置為NOCLUSTER)。
在主鍵與集合索引的處置方面,留意以下事項:
1、主鍵不與集合索引分別
2、集合索引鍵列盡可能防止應用int以外的數據類型
3、盡可能防止應用復合主鍵
創立索引時的留意事項
1、一直包括集合索引
當表中不包括集合索引時,表中的數據是無序的,這會下降數據檢索效力。即便經由過程索引減少了數據檢索的規模,但因為數據自己是無序的,當從表中提取現實數據時,會發生頻仍的定位成績,這也使得SQL Server根本上不會應用無集合索引表中的索引來檢索數據。
2、包管集合索引獨一
因為集合索引長短集合索引的行定位器,假如它不惟一,則會使行定位器中包括幫助數據,同時也招致從表中提取數據時,須要借助行定位器中的幫助數據來定位,這會下降處置效力。
3、包管集合索引最小
每一個集合鍵值都是一切非集合索引的葉結點記載,它越小,意味著每一個非集合索引的索引葉包括的有用數據越多,這關於晉升索引效力很有利益。
4、籠罩索引
籠罩索引是指索引中的列包括了數據處置中觸及的一切列,籠罩索引相當原始表的一個子集,因為這個子集中包括了數據處置觸及的一切列,是以操作這個子集便可以知足數據處置須要。普通而言,假如年夜多半處置都只觸及某個年夜表的某些列,可以斟酌為這些列樹立籠罩索引。
籠罩索引的樹立辦法是將要包括的列中的症結列做為索引鍵列,將其他列做為索引的包括列(應用索引創立語句中的INCLUDE子句)。
5、過量的索引
當數據產生變更時,SQL Server會同步保護相干索引中的數據,過量的索引會加影響數據變革的處置效力。是以,只應當在常常應用的列上樹立索引。
過量的索引還表現在對索引列的組合方法的掌握上。例如,假如有兩個列col1和col2,這兩個列的組合會發生三種應用情形:零丁應用col1、零丁應用col2及同時應用col1和col2。假如無為每種情形都樹立索引,則須要樹立三個索引。但也能夠只樹立一個復合索引(col1, col2),如許可以或許順次知足col1+col2、col1、col2這三種方法的查詢,個中,col2應用這個查詢會比擬委曲(還要合營零丁的統計),可以視現實情形肯定能否須要為col2樹立零丁的索引。
特殊留意:
不要樹立反復索引,今朝最多見的反復索引是零丁為某個列樹立主鍵和集合索引
與直接從表中提取數據比擬,依據索引檢索數據,多了一個索引檢索的進程,這個進程請求可以或許盡可能減少數據檢索規模,而且應用起碼的時光,如許能力真正包管可以或許經由過程索引進步數據檢索效力。
完成上述目標,關於索引鍵列的選擇,應當遵守以下准繩:
選擇性准繩
選擇性是知足前提的記載占總記載數的百分比,這個比率應當盡量低,如許能力包管經由過程索引掃描後,只須要從基本表提取很少的數據。
假如這個比率偏高,則不該該斟酌在此列上樹立索引。
數據密度准繩
數據密度是指列值獨一的記載占總記載數的百分比,這個比率越高,則解釋此列越合適樹立索引。
在斟酌數據密度的時刻,還要留意數據散布的成績,只要常常檢索的密度高時,才合適樹立索引。例如,假如一張表有10萬記載,固然某個列不反復的記載有9萬條,但假如常常檢索的2萬筆記錄,其不反復的列值才幾十條的話,這個列是不太合適樹立索引的。另外一種情形是,全體數據密度不年夜,但常常檢索的數據的密度年夜,例如定單的狀況,普通來講,定單的狀況就幾種,但曾經Close的定單常常占全部數據的絕年夜部門,但數據處置的時刻,根本上都是檢索未Close的定單,這類情形下,為定單的狀況列樹立索引照樣比擬有用的(SQL Server 2008中,可認為這類列樹立具有更佳後果的挑選索引)。
6、索引鍵列年夜小
普通不宜為跨越100Byte的列樹立索引。
7、復合索引鍵列次序
在索引中,索引的次序重要由索引中的每個鍵列肯定,是以,關於復合索引,索引中的列次序是很主要的,應當優先把數據密度年夜,選擇性列,存儲空間小的列放在索引鍵列的後面。