淺談SQL Server中統計關於查詢的影響剖析。本站提示廣大學習愛好者:(淺談SQL Server中統計關於查詢的影響剖析)文章只能為提供參考,不一定能成為您想要的結果。以下是淺談SQL Server中統計關於查詢的影響剖析正文

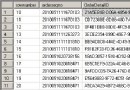
圖1.統計信息
統計信息若何影響查詢上面我們經由過程一個簡略的例子來看統計信息是若何影響查詢剖析器。我樹立一個測試表,有兩個INT值的列,個中id為自增,ref上樹立非集合索引,拔出100條數據,從1到100,再拔出9900條等於100的數據。圖1中的統計信息就是示例數據的統計信息。
此時,我where後應用ref值作為查詢前提,然則給定分歧的值,我們可以看出依據統計信息,查詢剖析器做出了分歧的選擇,如圖2所示。

圖2.依據分歧的謂詞,查詢優化器做了分歧的選擇
其實,關於查詢剖析器來講,柱狀圖關於直接可以肯定的謂詞異常管用,這些謂詞好比:
where date = getdate()
where id= 12345
where monthly_sales < 10000 / 12
where name like “Careyson” + “%”
然則關於好比
where price = @vari
where total_sales > (select sum(qty) from sales)
where a.id =b.ref_id
where col1 =1 and col2=2
這類在運轉時能力曉得值的查詢,采樣步長就顯著不是那末好用了。別的,下面第四行假如謂詞是兩個查詢前提,應用采樣步長也其實不好用。由於不管索引有若干列,采樣步長僅僅存儲索引的第一列。當柱狀圖不再好用時,SQL Server應用密度來肯定最好的查詢道路。
密度的公式是:1/表中獨一值的 個數。當密度越小時,索引越輕易被選中。好比圖1中的第二個表,我們可以經由過程以下公式來盤算一下密度:

圖3.某一列的密度
依據公式可以揣摸,當表中的數據量逐步增年夜時,密度會愈來愈小。
關於那些不克不及依據采樣步長做出選擇的查詢,查詢剖析器應用密度來估量行數,這個公式為:估量的行數=表中的行數*密度
那末,依據這個公式,假如我做查詢時,估量的行數就會為如圖4所示的數字。

圖4.估量的行數
我們來驗證一下這個結論,如圖5所示。

圖5.估量的行數
是以,可以看出,估量的行數是和現實的行數有收支的,當數據散布平均時,或許數據量年夜時,這個誤差將會變的異常小。
統計信息的更新由下面的例子可以看到,查詢剖析器因為依附於統計信息停止查詢,那末過時的統計信息則能夠招致低效力的查詢。統計信息既可以由SQL Server來停止治理,也能夠手動停止更新,也能夠由SQL Server治理更新時手動更新。
當開啟了主動更新後,SQL Server監控表中的數據更改,當到達臨界值時則會主動更新數據。這個尺度是:
向空表拔出數據時 少於500行的表增長500行或許更多 當表中行多於500行時,數據的變更量年夜於20%時上述前提的知足均會招致統計被更新。
固然,我們也能夠應用以下語句手動更新統計信息。
UPDATE STATISTICS 表名[索引名]
列級統計信息SQL Server還可以針對不屬於任何索引的列創立統計信息來贊助查詢剖析器獲得”估量的行數“.當我們開啟數據庫級其余選項“主動創立統計信息”如圖6所示。

圖6.主動創立統計信息
當這個選項設置為True時,當我們where謂詞指定了不在任何索引上的列時,列的統計信息會被創立,然則會有以下兩種情形破例:
創立統計信息的本錢跨越生成查詢籌劃的本錢 當SQL Server忙時不會主動生成統計信息我們可以經由過程體系視圖sys.stats來檢查這些統計信息,如圖7所示。

圖7.經由過程體系視圖檢查統計信息
固然,也能夠經由過程以下語句手動創立統計信息:
CREATE STATISTICS 統計稱號 ON 表名 (列名 [,...n])
總結本文簡略談了統計信息關於查詢途徑選擇的影響。過時的統計信息很輕易形成查詢機能的下降。是以,按期更新統計信息是DBA主要的任務之一。