sqlserver中distinct的用法(不反復的記載)。本站提示廣大學習愛好者:(sqlserver中distinct的用法(不反復的記載))文章只能為提供參考,不一定能成為您想要的結果。以下是sqlserver中distinct的用法(不反復的記載)正文
table表
字段1 字段2
id name
1 a
2 b
3 c
4 c
5 b
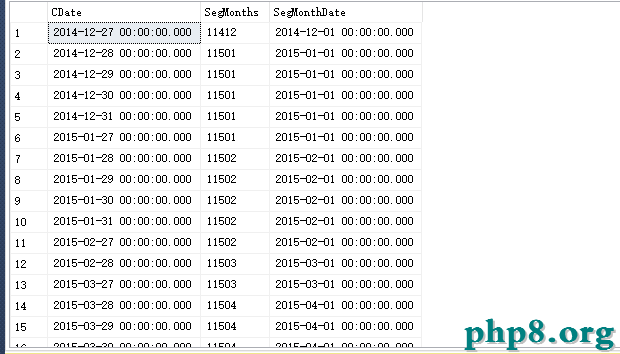
庫構造年夜概如許,這只是一個簡略的例子,現實情形會龐雜很多。
好比我想用一條語句查詢獲得name不反復的一切數據,那就必需
應用distinct去失落過剩的反復記載。
select distinct name from table
獲得的成果是:
----------
name
a
c
似乎到達後果了,可是,我想要獲得的是id值呢?改一下查詢語句吧:
select distinct name, id from table
成果會是:
----------
id name
1 a
2 b
3 c
4 c
5 b
distinct怎樣沒起感化?感化是起了的,不外他同時感化了兩個
字段,也就是必需得id與name都雷同的才會被消除
我們再改改查詢語句:
select id, distinct name from table
很遺憾,除毛病信息你甚麼也得不到,distinct必需放在開首。難到不克不及把distinct放到where前提裡?能,照樣報錯。
--------------------------------------------------------
上面辦法可行:
select *, count(distinct name) from table group by name
成果:
id name count(distinct name)
1 a 1
2 b 1
3 c 1
最初一項是過剩的,不消管就好了,目標到達
group by 必需放在 order by 和 limit之前,否則會報錯