一些有效的sql語句整頓 推舉珍藏。本站提示廣大學習愛好者:(一些有效的sql語句整頓 推舉珍藏)文章只能為提供參考,不一定能成為您想要的結果。以下是一些有效的sql語句整頓 推舉珍藏正文
1、解釋:創立數據庫
CREATE DATABASE database-name
2、解釋:刪除數據庫
drop database dbname
3、解釋:備份sql server
--- 創立 備份數據的 device
USE master
EXEC sp_addumpdevice 'disk', 'testBack', 'c:\mssql7backup\MyNwind_1.dat'
--- 開端 備份
BACKUP DATABASE pubs TO testBack
4、解釋:創立新表
create table tabname(col1 type1 [not null] [primary key],col2 type2 [not null],..)
依據已有的表創立新表:
A:create table tab_new like tab_old (應用舊表創立新表)
B:create table tab_new as select col1,col2… from tab_old definition only
5、解釋:刪除新表drop table tabname
6、解釋:增長一個列
Alter table tabname add column col type
注:列增長後將不克不及刪除。DB2中列加上後數據類型也不克不及轉變,獨一能轉變的是增長varchar類型的長度。
7、解釋:添加主鍵: Alter table tabname add primary key(col)
解釋:刪除主鍵: Alter table tabname drop primary key(col)
8、解釋:創立索引:create [unique] index idxname on tabname(col….)
刪除索引:drop index idxname
注:索引是弗成更改的,想更改必需刪除從新建。
9、解釋:創立視圖:create view viewname as select statement
刪除視圖:drop view viewname
10、解釋:幾個簡略的根本的sql語句
選擇:select * from table1 where 規模
拔出:insert into table1(field1,field2) values(value1,value2)
刪除:delete from table1 where 規模
更新:update table1 set field1=value1 where 規模
查找:select * from table1 where field1 like '%value1%' ---like的語法很精巧,查材料!
排序:select * from table1 order by field1,field2 [desc]
總數:select count * as totalcount from table1
乞降:select sum(field1) as sumvalue from table1
均勻:select avg(field1) as avgvalue from table1
最年夜:select max(field1) as maxvalue from table1
最小:select min(field1) as minvalue from table1
11、解釋:幾個高等查詢運算詞
A: UNION 運算符
UNION 運算符經由過程組合其他兩個成果表(例如 TABLE1 和 TABLE2)並消去表中任何反復行而派生出一個成果表。當 ALL 隨 UNION 一路應用時(即 UNION ALL),不用除反復行。兩種情形下,派生表的每行不是來自 TABLE1 就是來自 TABLE2。
B: EXCEPT 運算符
EXCEPT 運算符經由過程包含一切在 TABLE1 中但不在 TABLE2 中的行並清除一切反復行而派生出一個成果表。當 ALL 隨 EXCEPT 一路應用時 (EXCEPT ALL),不用除反復行。
C: INTERSECT 運算符
INTERSECT 運算符經由過程只包含 TABLE1 和 TABLE2 中都有的行並清除一切反復行而派生出一個成果表。當 ALL 隨 INTERSECT 一路應用時 (INTERSECT ALL),不用除反復行。
注:應用運算詞的幾個查詢成果行必需是分歧的。
12、解釋:應用外銜接
A、left outer join:
左外銜接(左銜接):成果集幾包含銜接表的婚配行,也包含左銜接表的一切行。
SQL: select a.a, a.b, a.c, b.c, b.d, b.f from a LEFT OUT JOIN b ON a.a = b.c
B:right outer join:
右外銜接(右銜接):成果集既包含銜接表的婚配銜接行,也包含右銜接表的一切行。
C:full outer join:
全外銜接:不只包含符號銜接表的婚配行,還包含兩個銜接表中的一切記載。
其次,年夜家來看一些不錯的sql語句
1、解釋:復制表(只復制構造,源表名:a 新表名:b) (Access可用)
法一:select * into b from a where 1<>1
法二:select top 0 * into b from a
2、解釋:拷貝表(拷貝數據,源表名:a 目的表名:b) (Access可用)
insert into b(a, b, c) select d,e,f from b;
3、解釋:跨數據庫之間表的拷貝(詳細數據應用相對途徑) (Access可用)
insert into b(a, b, c) select d,e,f from b in ‘詳細數據庫' where 前提
例子:..from b in '"&Server.MapPath(".")&"\data.mdb" &"' where..
4、解釋:子查詢(表名1:a 表名2:b)
select a,b,c from a where a IN (select d from b ) 或許: select a,b,c from a where a IN (1,2,3)
5、解釋:顯示文章、提交人和最初答復時光
select a.title,a.username,b.adddate from table a,(select max(adddate) adddate from table where table.title=a.title) b
6、解釋:外銜接查詢(表名1:a 表名2:b)
select a.a, a.b, a.c, b.c, b.d, b.f from a LEFT OUT JOIN b ON a.a = b.c
7、解釋:在線視圖查詢(表名1:a )
select * from (SELECT a,b,c FROM a) T where t.a > 1;
8、解釋:between的用法,between限制查詢數據規模時包含了界限值,not between不包含
select * from table1 where time between time1 and time2
select a,b,c, from table1 where a not between 數值1 and 數值2
9、解釋:in 的應用辦法
select * from table1 where a [not] in (‘值1','值2','值4','值6')
10、解釋:兩張聯系關系表,刪除主表中曾經在副表中沒有的信息
delete from table1 where not exists ( select * from table2 where table1.field1=table2.field1 )
11、解釋:四表聯盤問題:
select * from a left inner join b on a.a=b.b right inner join c on a.a=c.c inner join d on a.a=d.d where .....
12、解釋:日程支配提早五分鐘提示
SQL: select * from 日程支配 where datediff('minute',f開端時光,getdate())>5
13、解釋:一條sql 語句弄定命據庫分頁
select top 10 b.* from (select top 20 主鍵字段,排序字段 from 表名 order by 排序字段 desc) a,表名 b where b.主鍵字段 = a.主鍵字段 order by a.排序字段
14、解釋:前10筆記錄
select top 10 * form table1 where 規模
15、解釋:選擇在每組b值雷同的數據中對應的a最年夜的記載的一切信息(相似如許的用法可以用於服裝論壇t.vhao.net每個月排行榜,每個月熱銷產物剖析,按科目成就排名,等等.)
select a,b,c from tablename ta where a=(select max(a) from tablename tb where tb.b=ta.b)
16、解釋:包含一切在 TableA 中但不在 TableB和TableC 中的行並清除一切反復行而派生出一個成果表
(select a from tableA ) except (select a from tableB) except (select a from tableC)
17、解釋:隨機掏出10條數據
select top 10 * from tablename order by newid()
18、解釋:隨機選擇記載
select newid()
19、解釋:刪除反復記載
Delete from tablename where id not in (select max(id) from tablename group by col1,col2,...)
20、解釋:列出數據庫裡一切的表名
select name from sysobjects where type='U'
21、解釋:列出內外的一切的
select name from syscolumns where id=object_id('TableName')
22、解釋:列示type、vender、pcs字段,以type字段分列,case可以便利地完成多重選擇,相似select 中的case。
select type,sum(case vender when 'A' then pcs else 0 end),sum(case vender when 'C' then pcs else 0 end),sum(case vender when 'B' then pcs else 0 end) FROM tablename group by type
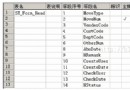
顯示成果:
type vender pcs
電腦 A 1
電腦 A 1
光盤 B 2
光盤 A 2
手機 B 3
手機 C 3
23、解釋:初始化表table1
TRUNCATE TABLE table1
24、解釋:選擇從10到15的記載
select top 5 * from (select top 15 * from table order by id asc) table_別號 order by id desc
ext:
1. 檢查數據庫的版本
select @@version
罕見的幾種SQL SERVER打補釘後的版本號:
8.00.194 Microsoft SQL Server 2000
8.00.384 Microsoft SQL Server 2000 SP1
8.00.532 Microsoft SQL Server 2000 SP2
8.00.760 Microsoft SQL Server 2000 SP3
8.00.818 Microsoft SQL Server 2000 SP3 w/ Cumulative Patch MS03-031
8.00.2039 Microsoft SQL Server 2000 SP4
2. 檢查數據庫地點機械操作體系參數
exec master..xp_msver
3. 檢查數據庫啟動的參數
sp_configure
4. 檢查數據庫啟動時光
select convert(varchar(30),login_time,120) from master..sysprocesses where spid=1
檢查數據庫辦事器名和實例名
print 'Server Name...............: ' + convert(varchar(30),@@SERVERNAME)
print 'Instance..................: ' + convert(varchar(30),@@SERVICENAME)
5. 檢查一切數據庫稱號及年夜小
sp_helpdb
重定名數據庫用的SQL
sp_renamedb 'old_dbname', 'new_dbname'
6. 檢查一切數據庫用戶登錄信息
sp_helplogins
檢查一切數據庫用戶所屬的腳色信息
sp_helpsrvrolemember
修復遷徙辦事器時孤立用戶時,可以用的fix_orphan_user劇本或許LoneUser進程
更改某個數據對象的用戶屬主
sp_changeobjectowner [@objectname =] 'object', [@newowner =] 'owner'
留意: 更改對象名的任一部門都能夠損壞劇本和存儲進程。
把一台辦事器上的數據庫用戶登錄信息備份出來可以用add_login_to_aserver劇本
檢查某數據庫下,對象級用戶權限
sp_helprotect
7. 檢查鏈接辦事器
sp_helplinkedsrvlogin
檢查遠端數據庫用戶登錄信息
sp_helpremotelogin
8.檢查某數據庫下某個數據對象的年夜小
sp_spaceused @objname
還可以用sp_toptables進程看最年夜的N(默許為50)個表
檢查某數據庫下某個數據對象的索引信息
sp_helpindex @objname
還可以用SP_NChelpindex進程檢查更具體的索引情形
SP_NChelpindex @objname
clustered索引是把記載按物理次序分列的,索引占的空間比擬少。
對鍵值DML操作非常頻仍的表我建議用非clustered索引和束縛,fillfactor參數都用默許值。
檢查某數據庫下某個數據對象的的束縛信息
sp_helpconstraint @objname
9.檢查數據庫裡一切的存儲進程和函數
use @database_name
sp_stored_procedures
檢查存儲進程和函數的源代碼
sp_helptext '@procedure_name'
檢查包括某個字符串@str的數據對象稱號
select distinct object_name(id) from syscomments where text like '%@str%'
創立加密的存儲進程或函數在AS後面加WITH ENCRYPTION參數
解密加密過的存儲進程和函數可以用sp_decrypt進程
10.檢查數據庫裡用戶和過程的信息
sp_who
檢查SQL Server數據庫裡的運動用戶和過程的信息
sp_who 'active'
檢查SQL Server數據庫裡的鎖的情形
sp_lock
過程號1--50是SQL Server體系外部用的,過程號年夜於50的才是用戶的銜接過程.
spid是過程編號,dbid是數據庫編號,objid是數據對象編號
檢查過程正在履行的SQL語句
dbcc inputbuffer ()
推舉年夜家用經由改良後的sp_who3進程可以直接看到過程運轉的SQL語句
sp_who3
檢討逝世鎖用sp_who_lock進程
sp_who_lock
11.檢查和壓縮數據庫日記文件的辦法
檢查一切數據庫日記文件年夜小
dbcc sqlperf(logspace)
假如某些日記文件較年夜,壓縮簡略恢復形式數據庫日記,壓縮後@database_name_log的年夜小單元為M
backup log @database_name with no_log
dbcc shrinkfile (@database_name_log, 5)
12.剖析SQL Server SQL 語句的辦法:
set statistics time {on | off}
set statistics io {on | off}
圖形方法顯示查詢履行籌劃
在查詢剖析器->查詢->顯示估量的評價籌劃(D)-Ctrl-L 或許點擊對象欄裡的圖形
文本方法顯示查詢履行籌劃
set showplan_all {on | off}
set showplan_text { on | off }
set statistics profile { on | off }
13.湧現紛歧致毛病時,NT事宜檢查器裡出3624號毛病,修單數據庫的辦法
先正文失落運用法式裡援用的湧現紛歧致性毛病的表,然後在備份或其它機械上先恢復然後做修復操作
alter database [@error_database_name] set single_user
修復湧現紛歧致毛病的表
dbcc checktable('@error_table_name',repair_allow_data_loss)
或許惋惜選擇修復湧現紛歧致毛病的小型數據庫名
dbcc checkdb('@error_database_name',repair_allow_data_loss)
alter database [@error_database_name] set multi_user
CHECKDB 有3個參數:
repair_allow_data_loss 包含對行和頁停止分派和撤消分派以糾正分派毛病、構造行或頁的毛病,
和刪除已破壞的文本對象,這些修復能夠會招致一些數據喪失。
修復操作可以在用戶事務下完成以許可用戶回滾所做的更改。
假如回滾修復,則數據庫仍會含有毛病,應當從備份停止恢復。
假如因為所供給修復品級的原因漏掉某個毛病的修復,則將漏掉任何取決於該修復的修復。
修復完成後,請備份數據庫。
repair_fast 停止小的、不耗時的修復操作,如修復非集合索引中的附加鍵。
這些修復可以很快完成,而且不會有喪失數據的風險。
repair_rebuild 履行由 repair_fast 完成的一切修復,包含須要較長時光的修復(如重建索引)。
履行這些修復時不會有喪失數據的風險。
sql語句實例
1 Examples
=======================================
select id,age,Fullname from tableOne a
where a.id!=(select max(id) from tableOne b where a.age=b.age and a.FullName=b.FullName)
=========================================
delete from dbo.Schedule where
RoomID=29 and StartTime>'2005-08-08' and EndTime<'2006-09-01' and Remark like 'preset' and UserID=107
and (
(ScheduleID>=3177 and ScheduleID<=3202 )
or (ScheduleID>=3229 and ScheduleID<=3254)
or (ScheduleID>=3307 and ScheduleID<=3332)
=========================================
delete tableOne
where tableOne.id!=(select max(id) from tableOne b where tableOne.age=b.age and tableOne.FullName=b.FullName);
==========================================
DataClient 12/23/2005 5:03:38 PM
select top 5
DOC_MAIN.CURRENT_VERSION_NO as Version, DOC_MAIN.MODIFY_DATE as ModifyDT, DOC_MAIN.SUMMARY as Summary, DOC_MAIN.AUTHOR_EMPLOYEE_NAME as AuthorName, DOC_MAIN.TITLE as Title, DOC_MAIN.DOCUMENT_ID as DocumentID, Attribute.ATTRIBUTE_ID as AttributeId, Attribute.CATALOG_ID as CatalogId, DOC_STATISTIC.VISITE_TIMES as VisiteTimes, DOC_STATISTIC.DOCUMENT_ID as DocumentID2
from DOC_MAIN DOC_MAIN
Inner join CATALOG_SELF_ATTRIBUTE Attribute on DOC_MAIN.CATALOG_ID=Attribute.CATALOG_ID
Left join DOC_STATISTIC DOC_STATISTIC on DOC_MAIN.DOCUMENT_ID=DOC_STATISTIC.DOCUMENT_ID
where (DOC_MAIN.AUTHOR_EMPLOYEE_ID = 1) and (Attribute.ATTRIBUTE_ID = 11)
order by VisiteTimes DESC
====================================
select top 1 DOCUMENT_ID,EMPLOYEE_NAME,COMMENT_DATE,COMMENT_VALUE
from dbo.DOC_COMMENT
where DOCUMENT_ID=19 and COMMENT_DATE = (select max(COMMENT_DATE) from DOC_COMMENT where DOCUMENT_ID=19)
====================================
select TITLE, (select top 1 EMPLOYEE_NAME
from dbo.DOC_COMMENT where DOCUMENT_ID=19) Commentman,
(select top 1 COMMENT_DATE
from dbo.DOC_COMMENT where DOCUMENT_ID=19) COMMENT_DATE
from DOC_MAIN where DOCUMENT_ID=19
======================================
alter view ExpertDocTopComment
as
select DOCUMENT_ID, max(ORDER_NUMBER ) as lastednum
from dbo.DOC_COMMENT
group by DOCUMENT_ID
go
alter view ExpertDocView
as
select TITLE , a.AUTHOR_EMPLOYEE_ID , c.EMPLOYEE_NAME , c.COMMENT_DATE
from dbo.DOC_MAIN a
left join
ExpertDocTopComment b
on
a.DOCUMENT_ID = b.DOCUMENT_ID
inner join
DOC_COMMENT c
on
b.DOCUMENT_ID = c.DOCUMENT_ID and
b.lastednum = c. ORDER_NUMBER
======================================
select a.Id ,a.WindowsUsername ,
0 , 1 ,
a.Email ,
case b.EnFirstName when null then a.Username else b.EnFirstName end,
case b.EnLastName when null then a.Username else b.EnLastName end
from UUMS_KM.dbo.UUMS_User a
left join
UUMS_KM.dbo.HR_Employee b
on
a. HR_EmployeeId = b.id
=====================================
列出上傳文檔最多的五小我的ID
select AUTHOR_EMPLOYEE_ID,count(AUTHOR_EMPLOYEE_ID)
from dbo.DOC_MAIN
group by AUTHOR_EMPLOYEE_ID
order by count(AUTHOR_EMPLOYEE_ID)
2719 2
6 9
12 30
1 116
列出上傳文檔最多的五小我的信息
select distinct AUTHOR_EMPLOYEE_ID ,AUTHOR_EMPLOYEE_NAME
from dbo.DOC_MAIN
where AUTHOR_EMPLOYEE_ID
in (
select top 5 AUTHOR_EMPLOYEE_ID
from dbo.DOC_MAIN
group by AUTHOR_EMPLOYEE_ID
order by count(AUTHOR_EMPLOYEE_ID)
)