SqlServer 履行籌劃及Sql查詢優化初探。本站提示廣大學習愛好者:(SqlServer 履行籌劃及Sql查詢優化初探)文章只能為提供參考,不一定能成為您想要的結果。以下是SqlServer 履行籌劃及Sql查詢優化初探正文
網上的SQL優化的文章其實是許多,說其實的,我也已經隨處找如許的文章,甚麼不要應用IN了,甚麼OR了,甚麼AND了,許多許多,還有許多人拿出僅幾S乃至幾MS的時光差的例子來證實著甚麼(有點好笑),讓很多人不曉得其是對照樣錯。而SQL優化又是每一個要與數據庫打交道的法式員的?課,所以寫了此文,與同伙們共勉。<?XML:NAMESPACE PREFIX = O />
談到優化就必定要觸及索引,就像要講鎖必定要說事務一樣,所以你須要懂得一下索引,僅僅是索引,就可以講半天了,所以索引我就不說了(打許多字是很累的,何況我也知之甚少),可以去參考相干的文章,這個網上材料比擬多了。
明天來摸索下MSSQL的履行籌劃,來讓年夜家曉得若何檢查MSSQL的優化機制,以此來優化SQL查詢。
--DROP TABLE T_UserInfo----------------------------------------------------
--建測試表
CREATE TABLE T_UserInfo
(
Userid varchar(20), UserName varchar(20),
RegTime datetime, Tel varchar(20),
)
--拔出測試數據
DECLARE @I INT
DECLARE @ENDID INT
SELECT @I = 1
SELECT @ENDID = 100 --在此處更改要拔出的數據,從新拔出之前要刪失落一切數據
WHILE @I <= @ENDID
BEGIN
INSERT INTO T_UserInfo
SELECT 'ABCDE'+CAST(@I AS VARCHAR(20))+'EF','李'+CAST(@I AS VARCHAR(20)),
GETDATE(),'876543'+CAST(@I AS VARCHAR(20))
SELECT @I = @I + 1
END
--相干SQL語句說明
---------------------------------------------------------------------------
--建集合索引
CREATE CLUSTERED INDEX INDEX_Userid ON T_UserInfo (Userid)
--建非集合索引
CREATE NONCLUSTERED INDEX INDEX_Userid ON T_UserInfo (Userid)
--刪除索引
DROP INDEX T_UserInfo.INDEX_Userid
---------------------------------------------------------------------------
---------------------------------------------------------------------------
--顯示有關由Transact-SQL 語句生成的磁盤運動量的信息
SET STATISTICS IO ON
--封閉有關由Transact-SQL 語句生成的磁盤運動量的信息
SET STATISTICS IO OFF
--顯示[前往有關語句履行情形的具體信息,並估量語句對資本的需求]
SET SHOWPLAN_ALL ON
--封閉[前往有關語句履行情形的具體信息,並估量語句對資本的需求]
SET SHOWPLAN_ALL OFF
---------------------------------------------------------------------------
請記住:SET STATISTICS IO 和 SET SHOWPLAN_ALL 是互斥的。
OK,如今開端:
起首,我們拔出100條數據
然後我寫了一個查詢語句:
SELECT * FROM T_UserInfo WHERE USERID='ABCDE6EF'
選中以上語句,按Ctrl+L,以下圖
<?XML:NAMESPACE PREFIX = V />
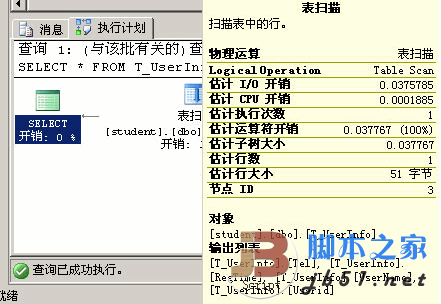
這就是MSSQL的履行籌劃:表掃描:掃描表中的行
然後我們來看該語句對IO的讀寫:
履行:SET STATISTICS IO ON
此時再履行該SQL:SELECT * FROM T_UserInfo WHERE USERID='ABCDE6EF'
切換到消逝欄顯示以下:
表'T_UserInfo'。掃描計數1,邏輯讀1 次,物理讀0 次,預讀0 次。
說明下其意思:
四個值分離為:
履行的掃描次數;
從數據緩存讀取的頁數;
從磁盤讀取的頁數;
為停止查詢而放入緩存的頁數
主要:假如關於一個SQL查詢有多種寫法,那末這四個值中的邏輯讀(logical reads)決議了哪一個是最優化的。
接上去我們為其建一個集合索引
履行CREATE CLUSTERED INDEX INDEX_Userid ON T_UserInfo (Userid)
然後再履行SELECT * FROM T_UserInfo WHERE USERID='ABCDE6EF'
切換到新聞欄以下顯示:
表'T_UserInfo'。掃描計數1,邏輯讀2 次,物理讀0 次,預讀0 次。
此時邏輯讀由本來的1釀成2,
解釋我們又加了一個索引頁,如今我們查詢時,邏輯讀就是要讀兩頁(1索引頁+1數據頁),此時的效力還不如不建索引。
此時再選中查詢語句,然後再Ctrl+L,以下圖:
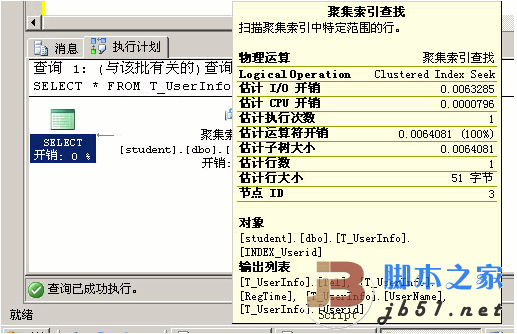
集合索引查找:掃描集合索引中特定規模的行
解釋,此時用了索引。
OK,到這裡你應當曾經曉得初步曉得MSSQL查詢籌劃和若何檢查對IO的讀撤消耗了吧!
接上去我們持續:
如今我再把測試數據轉變成1000條
再履行SET STATISTICS IO ON,再履行
SELECT * FROM T_UserInfo WHERE USERID='ABCDE6EF'
在不加集合索引的情形下:
表'T_UserInfo'。掃描計數1,邏輯讀7 次,物理讀0 次,預讀0 次。
在加集合索引的情形下:CREATE CLUSTERED INDEX INDEX_Userid ON T_UserInfo (Userid)
表'T_UserInfo'。掃描計數1,邏輯讀2 次,物理讀0 次,預讀0 次。
(其實也就是說此時是讀了一個索引頁,一個數據頁)
如斯,在數據量稍年夜時,索引的查詢優勢就顯示出來了。
先小總結下:
當你構建SQL語句時,按Ctrl+L便可以看到語句是若何履行,是用索引掃描照樣表掃描?
經由過程SET STATISTICS IO ON 來檢查邏輯讀,完成統一功效的分歧SQL語句,邏輯讀
越小查詢速度越快(固然不要找誰人只要幾百筆記錄的例子來反我)。
我們再持續深刻:
OK,如今我們再來看一次,我們換個SQL語句,來看下MSSQL若何來履行的此SQL呢?
如今去失落索引:DROP INDEX T_UserInfo.INDEX_Userid
如今翻開[顯示語句履行情形的具體信息]:SET SHOWPLAN_ALL ON
然後再履行:SELECT * FROM T_UserInfo WHERE USERID LIKE 'ABCDE8%'
看成果欄:成果中有些詳細參數,好比IO的消費,CPU的消費。
在這裡我們只看StmtText:
SELECT * FROM T_UserInfo WHERE USERID LIKE 'ABCDE8%'
|--Table Scan(OBJECT:([student].[dbo].[T_UserInfo]), WHERE:(like([T_UserInfo].[Userid], 'ABCDE8%', NULL)))
Ctrl+L看下此時的圖行履行籌劃:

我再加上索引:
先封閉:SET SHOWPLAN_ALL OFF
再履行:CREATE CLUSTERED INDEX INDEX_Userid ON T_UserInfo (Userid)
再開啟:SET SHOWPLAN_ALL ON
再履行:SELECT * FROM T_UserInfo WHERE USERID LIKE 'ABCDE8%'
檢查StmtText:
SELECT * FROM T_UserInfo WHERE USERID LIKE 'ABCDE8%'
|--Clustered Index Seek(OBJECT:([student].[dbo].[T_UserInfo].[INDEX_Userid]), SEEK:([T_UserInfo].[Userid] >= 'ABCDE8' AND [T_UserInfo].[Userid] < 'ABCDE9'), WHERE:(like([T_UserInfo].[Userid], 'ABCDE8%', NULL)) ORDERED FORWARD)Ctrl+L看下此時的圖行履行籌劃:
Ctrl+L看下此時的圖行履行籌劃:
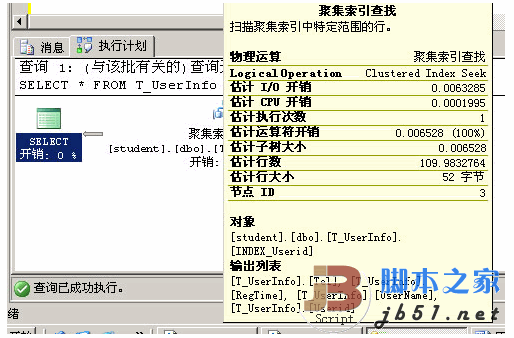
在有索引的情形下,我們再寫一個SQL:
SET SHOWPLAN_ALL ON
SELECT * FROM T_UserInfo WHERE LEFT(USERID,4)='ABCDE8%'
檢查StmtText:
SELECT * FROM T_UserInfo WHERE LEFT(USERID,4)='ABCDE8%'
|--Clustered Index Scan(OBJECT:([student].[dbo].[T_UserInfo].[INDEX_Userid]), WHERE:(substring([T_UserInfo].[Userid], 1, 4)='ABCDE8%'))
Ctrl+L看下此時的圖行履行籌劃:
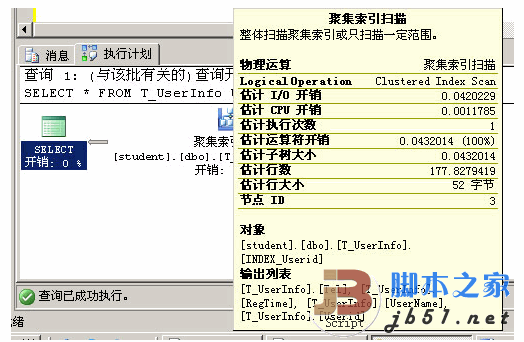
我們再分離看一下三種情形下對IO的操作
分離以下:
第一種情形:表'T_UserInfo'。掃描計數1,邏輯讀7 次,物理讀0 次,預讀0 次。
第二種情形:表'T_UserInfo'。掃描計數1,邏輯讀3 次,物理讀0 次,預讀0 次。
第三種情形:表'T_UserInfo'。掃描計數1,邏輯讀8 次,物理讀0 次,預讀0 次。
這解釋:
第一次是表掃描,掃了7頁,也就是全表掃描
第二次是索引掃描,掃了1頁索引,2頁數據頁
第三次是索引掃描+表掃描,掃了1頁索引,7頁數據頁
經由過程比擬,嘿嘿,很輕易的看出:第二種第三種寫法在都有索引的情形下,like有用的應用索引,而left則不克不及,如許一個最簡略的優化的例子就出來了,哈哈。
在我舉的例子中,用的是集合索引掃描,字段是字母加數字,年夜家可以嘗嘗看純數字的、字母的、漢字的等等,懂得下MMSQL會若何轉變SQL語句來應用索引。然後再嘗嘗非集合索引是甚麼情形?用不消索引和甚麼有關?子查詢MSSQL是若何履行?IN用不消索引,LIKE用不消索引?函數用不消索引?OR、AND、UNION?子查詢呢?在這裡我紛歧一去試給年夜家看了,只需曉得了若何去看MSSQL的履行籌劃(圖形和文本),許多工作就很晴明了。
年夜總結:
完成統一查詢功效的SQL寫法能夠會有多種,假如斷定哪一種最優化,假如僅僅是從時光下去測,會受許多外界身分的影響,而我們明確了MSSQL若何去履行,經由過程IO邏輯讀、經由過程檢查圖示的查詢籌劃、經由過程其優化後而履行的SQL語句,才是優化SQL的真正路徑。
別的提示下:數據量的若干有時會影響MSSQL對統一種查詢寫法語句的履行籌劃,這一點在非集合索引上特殊顯著,還有就是在多CPU與單CPU下,在多用戶並發情形下,統一寫法的查詢語句履行籌劃會有所分歧,這個就須要年夜家無機會去實驗了(我也沒有這方面的太多經歷與年夜家分享)。
先寫這些吧,因為我對MSSQL熟悉還很淺陋,若有纰謬的處所,還請斧正。